SVM的数学原理
SVM的数学原理
- 前言
- 线性分类器
- 可分离的case
-
- 原始优化问题
- 支持向量
- 对偶优化问题
- 不可完全分离的case
-
- 原始优化问题
- 支持向量
- 对偶优化问题
前言
看了大概10天的SVM,本来计划着自己从零到有写一篇对SVM的数学原理的理解,草稿写了一半发现自己对其内部本质认识的并不透彻,还需要时间修炼。
我发现Foundations of machine learning(Second Edition)中第五章有关SVM的部分讲的很好,这篇博客致力于将其用最简洁的中文讲述出来。
线性分类器
考虑一个输入空间X, 假设输入空间是RN的子集, 其中N>=1
定义一个输出空间或者称之为目标空间y={+1,-1}
定义 f : X → y 是一个目标函数
给定一个能够将X映射到y的函数的假设集H,二分类问题被形式化描述如下:
根据某些未知的分布D,学习器从X中接收一个服从i.i.d的共具有m个样本的训练集S,其中S = ((x1, y1), . . . ,(xm, ym)) ∈(X × y)m, with yi = f(xi) for all i ∈ [m].
问题就变为要确定一个假设h ∈ H,找到这样一个二分类器,使得泛化误差最小:

在这个任务中,不同的假设集H可以被选择,根据奥卡姆剃刀原理,具有更小复杂性的假设集被受到青睐。
一个具有相对小的复杂性的天然的假设集就是线性分类器,或者称之为超平面,它被定义成如下形式:
![]()
这样,学习问题就是一个线性分类问题。在RN空间上面的超平面的通用等式为
![]()
其中,w ∈ RN,是超平面的一个非零法向量,b ∈ R,是一个标量。
形式为x → sign(w · x + b)的一个假设使得所有标签为正的点都落在超平面w · x + b = 0的一边,所有标签为负的点都落在另一边。
可分离的case
假设训练样本集S是完全线性可分的,也就是说存在一个超平面可以完美的毫不差错的将标签为+1和标签为-1的样本点分开,就像图5.1左边那个图所展现的那样

这等价于存在一个超平面
![]()
使得

但是,从图5.1中可以很容易看出,存在无穷多个满足条件超平面,哪一个超平面才是我们的学习算法应该选择的呢?SVM解的定义是基于几何间隔的概念的。
定义5.1(几何间隔)
一个线性分类器h: x → w·x+b在一个点x处的几何间隔是该点到超平面w·x+b = 0的欧氏距离

对于一个训练样本集 S = (x1, . . . , xm),线性分类器h的几何间隔是样本集中所有点的最小几何间隔
![]()
这是定义h的超平面到最近的采样点的距离
SVM的解是具有最大几何间隔的分离超平面,因此被称为最大间隔超平面
图5.1中右边那幅图表明的是在完全可分离的case中SVM算法返回的使间隔最大化的超平面。
我们已经可以观察到,从以下意义上说,SVM解决方案也可以被视为“最安全”的选择:
一个测试点可以被几何边界为ρ的分离超平面正确地分类,即使当它落在距离ρ内,只要它与训练集在超平面这一侧具有相同的标签。对于SVM的解,ρ是最大几何间隔,因此是“最安全”的值。
原始优化问题
我们现在推导并定义SVM解的方程和优化问题。

根据几何间隔的定义,分离超平面的最大间隔ρ由下式给出:
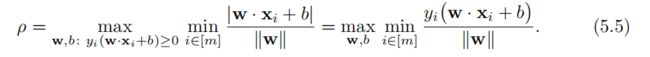
第二个等式成立是基于这样的事实:因为所有的样本点都是严格线性可分的,对所有的i ∈ [m].必定有yi(w · xi + b)非负。现在,我们又观察到最后一个表达式对于(w,b)乘一个正标量是不变的,因此我们可以将(w,b)缩放到
![]()
从而
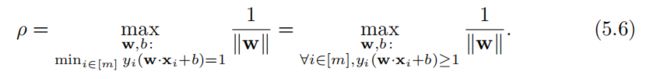
第二个等式成立的原因是,对于最大化(w,b),yi(w·xi + b)的最小值为1

图5.3表达了最大化(5.6)的解(w,b),除了最大间隔超平面,图中还引入了边界超平面,边界超平面平行于分割超平面,并且经过正的和负的一边的离分割超平面最近的点。因为它们平行于分割超平面,因此三者具有相同的法向量w。除此之外,因为对于离分割超平面最近的点有|w·x+b| = 1,那么边界超平面就可以用w ·x+b = ±1来表达。
因为最大化1/||w||等价于最小化0.5||w||2,所以公式5.6在可分离case中由SVM返回的(w,b)是下列凸函数问题的解:

其中下列目标函数是无限可微的
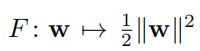
它的梯度是:
![]()
它的Hessian是单位矩阵I,I的特征值是严格为正的:
![]()
因此,
![]()
所以,F是严格凸的。
所有的约束都由下列仿射函数来定义,因此是性质良好的
![]()
根据凸优化理论,式为5.7的优化问题具有唯一解,这是一个不是所有学习算法都有的重要且有利的属性。
更多的,因为目标函数是二次的且约束是仿射的,5.7的优化问题是二次规划(QP)问题的一个特定实例,在优化中QP问题已经有了一系列扩展的研究。除此之外,在SVM的经验成功及其丰富的理论基础的推动下,已经开发出专门的方法来更有效地解决这个特定的凸QP问题。
支持向量
返回到优化问题(5.7),我们注意到约束是仿射的因此是性质良好的。目标函数也像仿射约束那样是凸的并且是可微的。于是,KKT条件就可以应用到这个应用中。我们将使用这些条件来分析算法并演示其中几个关键属性,然后在下一节中推导出与SVM相关的对偶优化问题。
我们引入如下的Lagrange变量,使其与m个约束相关联
![]()
用向量表示为
![]()
那么,拉格朗日函数就可以定义成如下形式:


通过将拉格朗日函数相对于原始变量w和b的梯度置为零,并且加上互补条件从而来获得KKT条件:

通过等式(5.9),在SVM问题解上面的权重向量w是训练集向量x1,…,xm的线性组合。一个向量xi出现在(5.9)的展开式中当且仅当
![]()
这些向量被称为支持向量。通过互补条件(5.11),可以看出,如果
![]()
那么一定有
![]()
于是,支持向量全部落在如下描述的边界超平面上
![]()
支持向量完全确定了最大间隔超平面或者SVM的解,就像这个算法的名字所表示的那样。由于支持向量的定义,那些不落在边界超平面上的向量对最大间隔超平面的确定不产生任何影响,他们是否存在,最终SVM的解都将保持不变。注意到尽管SVM问题的解w是唯一的,但是支持向量却不是唯一的。在N维空间,N+1个点足够定义一个超平面。于是,当超过N+1个点落在边界超平面上,对N+1个支持向量的选择是有多种方案的。
对偶优化问题
为了推导出约束优化问题(5.7)的对偶形式,我们将(5.9)式中表达的关于w的定义带入到拉格朗日函数中,并应用约束(5.10),拉格朗日函数可以写成:
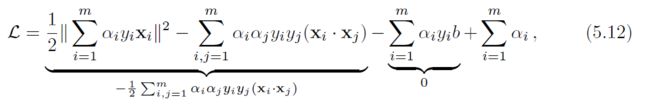
进而简化为:
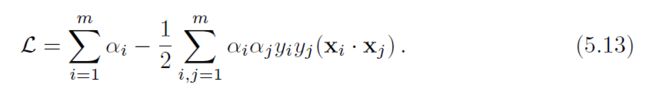
进而对于在可分离case中的SVM对偶优化问题可以写为:

该对偶优化目标函数如下:

它是无限可微的,它的Hessian阵可以写成:
![]()
其中A是与向量y1x1,…, ymxm相关联的Gram矩阵,因此是半正定的,所以
![]()
说明G是一个凹函数。
因为约束是仿射的并且是凸的,因此最大化问题(5.14)是一个凸优化问题。
因为G是alpha的二次函数,这个对偶优化问题仍然是一个QP问题,与在原始变量优化的情况下是一样的,并且再一次可以使用通用和专用QP求解器来获得解(通常可以用SMO算法来进行求解)。
更多的,因为约束是仿射的,它们是性质良好的并且是强对偶的。于是,原始的和对偶的优化问题是等价的,即对偶问题(5.14)的解alpha,通过利用等式(5.9)可以直接被作为SVM算法返回的假设。利用等式(5.9),有:

因为支持向量全部落在边界超平面上,对于任意支持向量xi,都有w xi + b = yi,所以b可以经由下列公式获得:
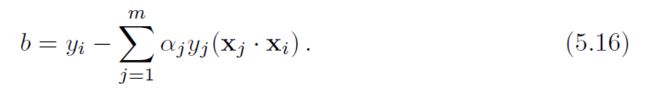
对偶优化问题(5.14)以及表达式(5.15)(5.16)共同揭示了SVM的一个重要属性:假设解只依赖于向量间的内积,并不直接依赖于向量本身。这个至关重要的属性将在核方法中变得清晰。
现在可以使用等式(5.16)来推导出几何间隔ρ关于alpha的简单表达式。因为(5.16)对所有alphai !=0 的 i 成立,那么在等式两边同乘alphaiyi,并且对它们求和可以得到:

考虑到等式(5.9)并且yi2=1,上式可以写为:

因为alphai>=0,我们根据L1范数获得以下关于间隔ρ的表达式:
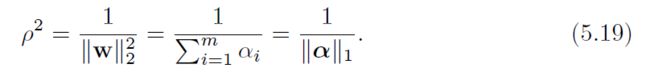
不可完全分离的case
在大多数的实际应用中,训练数据不是完全可分离的,这表明对任何分割超平面w x + b = 0,存在xi属于S,能够使:
因此,上一节中讨论的线性可分离情况中施加的约束不能同时保持成立。但是,这些约束的松弛版本却是可以同时成立的,松弛版本的约束可以写为:

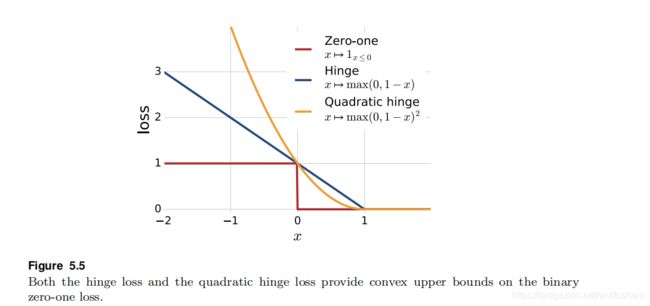
其中变量 ξi被称为松弛变量,在优化问题中通常用来定义约束的松弛版本。在这里,松弛变量 ξi衡量的是某一个向量xi偏离期望不等式yi(w · xi + b) ≥ 1的距离,图5.4表明了这种情况。

对一个超平面w · x + b = 0, 使ξi > 0的向量xi可以被视作异常值。每个xi必须位于适当的边界超平面的正确一侧,以免被视为异常值。因此,0
在不可分离case中我们应该怎样选择超平面呢?一种想法是选择能够使经验误差最小的超平面,但是,这个解不一定满足最大间隔保证。此外,当作为维度为N空间的函数的时候,确定具有最小0-1损失的超平面(即,最小数量的错误分类)的问题是NP-难问题。
因此这里有两个相互矛盾的目标:一方面,我们希望限制由异常值引起的总松弛量,这可以通过如下标准来衡量:
![]()
或者,更通用的衡量形式是:
![]()
另一方面,我们寻求具有较大间隔的超平面,但较大的间隔会导致更多的异常值,从而导致更大的松弛。
原始优化问题
这促成了以下一般优化问题在不可分离的case中重新定义SVM,其中参数C≥0确定间隔最大化(或最小化||w||2)和最小化松弛惩罚之间的权衡:
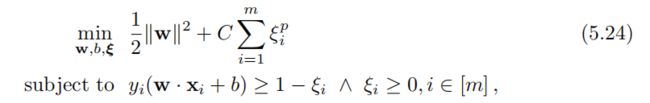
![]()
参数C通常会由n折交叉验证确定。
与可分离的case中一样,(5.24)也是一个凸优化问题,因为约束是仿射的且是凸的,并且目标函数对于任何p≥1都是凸的。特别的,考虑到范数||·||p具有凸的性质,下式也是凸的:
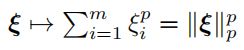
p有许多可能的选择,导致对松弛项的或多或少的激进性的惩罚。选择p = 1和p = 2可以生成最直接的解和相关的分析。与p=1和p=2相关的额损失函数分别被称为hinge损失和二次hinge损失。图5.5画出了这些损失和标准的0-1损失之间的关系。两个hinge损耗都是零损耗的凸上限,因此非常适合优化。在下文中,分析在hinge损失(p = 1)的情况下呈现,这是SVM最广泛使用的损失函数。
支持向量
正如在可分离的case中那样,约束是仿射的因此是性质良好的。目标函数也像仿射约束那样是凸的并且是可微的。因此可以将KKT条件应用到这个优化问题中,我们使用KKT条件既分析算法本身也解释与之相关的一些重要属性,再接下来会推导SVM的对偶优化问题。
我们引入对于m个约束的拉格朗日变量
![]()
以及m个与松弛变量的非负性约束相关联的拉格朗日变量
![]()
向量α,β可以表示成:
![]()
![]()
拉格朗日函数被定义如下:
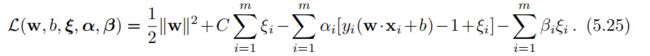
![]()
![]()
通过将拉格朗日相对于原始变量w,b和ξ的梯度设置为零并引入互补条件来获得KKT条件:

正如可分离的case中表示的那样,根据等式(5.26),权重向量w在SVM问题中的解是训练集向量x1,x2,…,xm的一个线性组合。一个向量xi会出现在展开式中当且仅当αi != 0,这些向量被称为支持向量。这里有两种类型的支持向量,根据互补条件(5.29),当αi != 0的时候,一定有yi(w·xi+b) = 1-ξi
(1) 当ξi=0的时候,有yi(w·xi+b) = 1,这种情况与可分离case中是一样的,向量xi恰好落在边界超平面上
(2)而当ξi!=0的时候,向量xi是一个离群向量,根据条件(5.30),此时一定有βi = 0,又根据条件(5.28),需要αi = C。
综上,支持向量要么是离群向量,这种情况下αi = C,要么正好落在边界超平面上。正如可分离case中所表现的那样,尽管权重向量w的解是唯一的,但是支持向量并不是唯一的。
对偶优化问题
为了推导出约束优化问题(5.24)的对偶形式,我们将(5.26)式中表达的关于w的定义带入到拉格朗日函数中,并应用约束(5.27),拉格朗日函数可以写成:
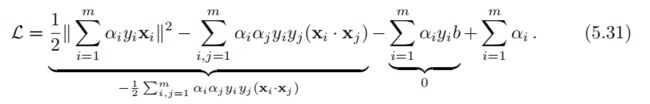
值得注意的是,我们发现目标函数与可分case的表达形式没有任何区别:
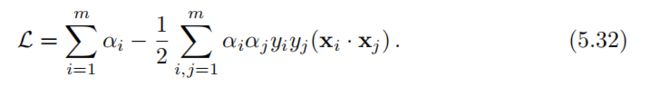
然而,在这里,除了αi ≥ 0,我们必须增加由新的拉格朗日变量 βi ≥ 0引入的约束,根据条件(5.28),有αi+βi=C,而βi ≥,因此一定有αi≤C。从而得出不可分离case中SVM的以下对偶优化问题,其与可分离case(5.14)的位移不同之处在于增加了约束αi≤C:
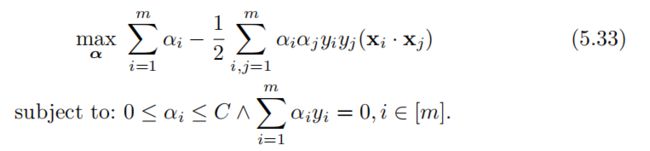
因此,我们之前关于优化问题(5.14)的讨论也适用于(5.33)。 特别地,在(5.33)中目标函数是凹的并且是无限可微的,并且(5.33)等价于凸QP问题,因此(5.33)等价于原始问题(5.24).
对偶问题(5.33)的解α通过等式(5.26)可以被用来直接决定SVM返回的假设:
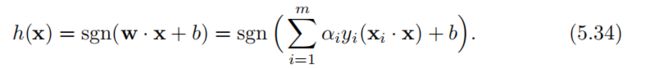
更多的,b可以由任何落在边界超平面上的支持向量xi算出,该支持向量xi满足 0 < αi < C,并且w·xi+b = yi,因此:

与可分离的情况一样,对偶优化问题(5.33)和表达式(5.34)和(5.35)显示了SVM的一个重要特性:假设解仅依赖于向量之间的内积,而不是直接依赖于向量本身。 这个事实可用于扩展SVM以定义非线性决策边界。