【此后无良辰】实验四 单周期CPU设计与实现——单指令CPU
一、 实验目的
通过设计并实现支持一条指令的CPU,理解和掌握CPU设计的基本原理和过程。
二、 实验内容
设计和实现一个支持加法指令的单周期CPU。要求该加法指令(表示为add r1,r2,r3)格式约定如下:
采用寄存器寻址,r1,r2,r3为寄存器编号,r1和r2存放两个源操作数,r3为目标寄存器,其功能为[r1] + [r2] -> r3;
指令字长16位,操作码和地址码字段分配如下所示:

三、 实验原理
单周期CPU是指所有指令均在一个时钟周期内完成的CPU。CPU由数据通路及其控制部件两部分构成,因而要完成一个支持若干条指令CPU的设计,需要依次完成以下两件事:
1) 根据指令功能和格式设计CPU的数据通路;
2) 根据指令功能和数据通路设计控制部件。
3.1 根据功能和格式完成CPU的数据通路设计
本实验需要设计的CPU只需要支持一条加法指令,而该指令的功能是在一个时钟周期内从寄存器组中r1和r2中取出两个操作数,然后送到ALU进行加法运算,最后把计算结果保存到r1寄存器中。下图给出了改加法指令的数据通路图。
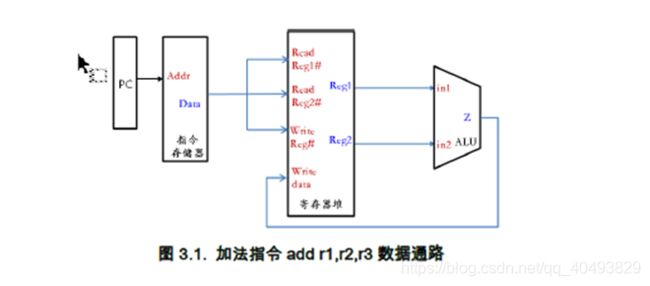
此外,还需要确定各个部件的位数,为了简单起见,我们假设目标CPU的机器字长、存储字长和指令字长相等均为16位,存储单元个数假设为256,按字寻址,并取PC位数为8。
3.2 根据指令功能、数据通路完成控制单元的设计
控制单元的功能是为当前要执行的指令产生微操作命令从而完成该指令的执行。为了能够完成加法指令的执行,结合图1,控制单元需要在取出指令后根据指令操作码(本例中是加法指令),控制ALU(参考实验二)做加法(通过给alu_op信号线相应赋值),并把结果写回寄存器组(参考实验三)中(通过给wr_en赋值为true)。图2给出了整合控制单元后目标CPU的原理图,系统时钟信号也已标注。
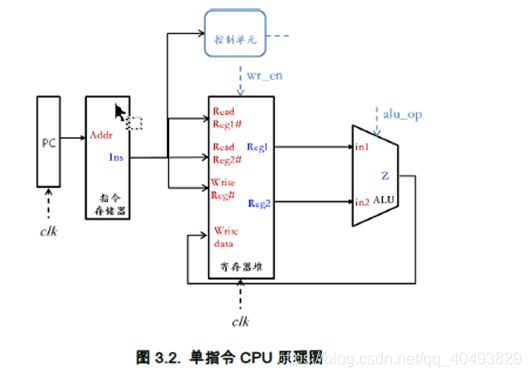
自己生成的原理图:

图片清晰度可能不够
可见附件CPU-1.pdf
四、 实验步骤
在第三部分通过对该CPU实现细节的分析、设计,并得到该CPU的原理图后,就可以依次实现各个模块,并进行仿真验证了。
4.1 CPU各模块Verilog实现
在前面实验中,已经分别设计和实现了PC、指令存储器、寄存器组和ALU,这里只给出各个模块的功能描述及其接口定义,具体实现可以直接使用或者调整前面试验的实现代码。
1) PC模块

module pc4(
input clk, rst,
output reg [7:0] pc
);
always@(posedge clk) begin // 上升沿判断
if(rst == 1)
pc = 0;
else
pc = pc + 1;
end
endmodule
2) 指令存储器模块

module IPunit4(
output reg [15:0] Ins,
input [7:0] Addr
);
integer i,j;
reg [15:0] unit[8'b11111111:0]; // 1k按字编址
initial begin
for(i = 0; i < 256; i = i + 1)
begin
j = i % 6;
unit[i][2:0] = j;
unit[i][5:3] = j + 1;
unit[i][8:6] = j + 2;
unit[i][15:9] = 0;
end
end
always@* begin // 任何时钟改变均会进入
Ins = unit[Addr];
end
endmodule
3) 寄存器堆

module reg_stack4(
input clk, wr_en,
input [15:0] write_data,
input [2:0] read_reg1, read_reg2, write_reg,
output reg [15:0] reg1, reg2
);
integer i;
reg [15:0] regunit[7:0];
initial begin
for(i = 0; i < 8; i = i + 1) begin
regunit[i] = i;
end
end
always@* begin // 任何一个时钟的变化都会引起
reg1 = regunit[read_reg1];
reg2 = regunit[read_reg2];
end
always@(negedge clk) begin // 在每一个下降沿就行判断
if(wr_en == 1)
regunit[write_reg] = write_data;
end
endmodule
4) ALU

module alu4(
input [15:0] in1, in2,st_r1,st_addr,
input [2:0] alu_op,
output reg [15:0] Z
);
always@* begin
case(alu_op)
3'b000: Z = in1+in2;
3'b001: Z = in1-in2;
3'b010: Z = in1&&in2;
3'b011: Z = in1||in2;
3'b100: Z = in1<>in2;
3'b110: Z = st_r1;// 进一步实验中的
endcase
end
endmodule
5) 控制单元

Verilog关键代码:
module cu4(
input [6:0] Ins_op,
output reg wr_en,
output reg [2:0] alu_op
);
always@* begin // 任何时钟信号都引起
if(Ins_op == 0)
begin
wr_en = 1;
end
alu_op = 3'b000;// 设置alu的操作码 对应为加
end
endmodule
4.2 CPU顶层文件封装实现
通过根据图2将以上定义的模块进行连接、封装就得到了目标CPU,该CPU的输入为系统时钟信号clk和重置信号reset。
Verilog关键代码:
module cpu(
input clk, rst
);
wire wr;
wire [2:0] alu_op;
wire [7:0] addr;
wire [15:0] z, ins, r1, r2,st_r1,st_addr;
pc4 pc4(
.clk(clk), .rst(rst), .pc(addr)
);
IPunit4 IPunit4(
.Addr(addr), .Ins(ins)
);
cu4 cu4(
.Ins_op(ins[15:9]),
.wr_en(wr), .alu_op(alu_op)
);
reg_stack4 reg_stack4(
.clk(clk), .wr_en(wr),
.read_reg1(ins[8:6]), .read_reg2(ins[5:3]), .write_reg(ins[2:0]),
.write_data(z), .reg1(r1), .reg2(r2)
);
alu4 alu4(
.st_r1(ins[8:6]),.st_addr(ins[5:0]),
.in1(r1), .in2(r2),
.alu_op(alu_op), .Z(z)
);
Endmodule
4.3 CPU模拟仿真
为了仿真验证所实现的CPU,需要定义测试文件并在测试文件中对指令存储器和寄存器堆中的相应寄存器的值进行初始化,并通过仿真波形图查看是否指令得到了正确执行。
TestBench关键代码
module cpu_sim;
reg clk, rst;
always #1 clk = ~clk;
initial begin
clk = 1;
rst = 1;
#10 rst = 0;
end
cpu uut(
.clk(clk), .rst(rst)
);
endmodule
2)ModelSim仿真及分析

添加其他变量到监控中
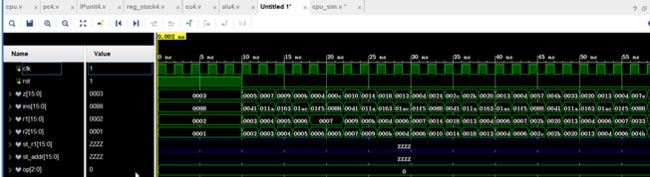
根据ModelSim仿真,我们可以看出
Alu_op一直为0,则一直执行加法操作
Z中存放的是结果 即 r1+ r2 = Z
根据ModelSim仿真图可以知道实验成功
五、总结
通过实验,请思考你认为完成一个CPU的设计与实现主要由哪几个步骤完成?主要注意事项有哪些?
(1) 设计指令
设计指令包括设计指令的长度,指令要被分成几段的内容,每段内容需要去赋予什么样的功能,例如存数指令

(2) 设计组件
例如ALU,CU,IR等组件,每一个组件有自己的功能和输入信号和输出信号,这个环节要保证每一个的组件能够正常运行
(3) cpu顶层文件封装
cpu顶层文件封装,即对每一个组件进行连接,实现各个组件的相互通信,以达到cpu能够正常运行
注意事项 (即PPT第二章到第五章的内容)
第一次运行后,需要手动将一些变量添加进监视器
选择create files
Add files改变文件会同时改源文件
所以不要不同实验使用同一份文件(血的教训
六、进一步实验
1)在本节实现的单指令CPU基础上,添加存数指令st r1,addr,实现一个可以支持加法和存数指令的CPU,并使用ModelSim进行仿真验证。
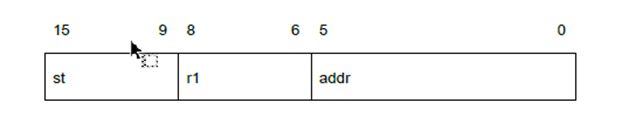
指令st r1, addr: [r1] -> mem[addr]的格式如下:
实验分析提示
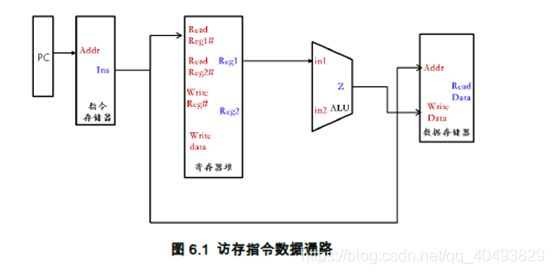
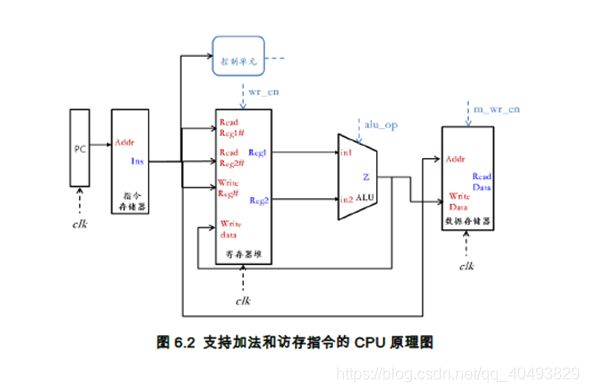
首先根据新增加的访存指令功能设计其数据通路,如图6.1。为使CPU能够支持前面的加法指令和该访存指令,只需要将两个数据通路进行合并(即图3.1和图6.1),并最终得到该CPU的原理图,如图6.2所示。
如果要设计支持更多条指令的CPU,只需根据每条指令设计其数据通路,并采用合并的方式构建支持所有指令的CPU数据通路,然后在进行控制单元的设计即可。在合并过程中需要注意的是:当某个部件的输入端口有多个输入来源的时候需在此端口前添加一个多路选择器从而允许控制部件根据执行的需要选择所需的数据来源。
为了实现我们的存数指令,我们可以在原来的基础上进行修改:
Verilog文件中需要修改的部分:
IR

CU
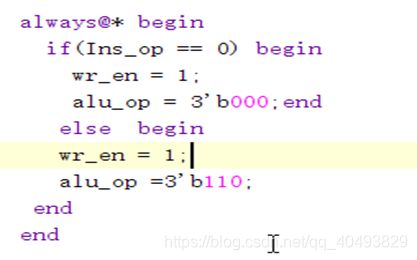
ALU
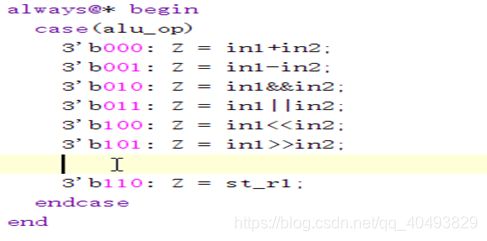
ModelSim仿真及分析

根据ModelSim仿真,我们可以看出
Alu_op在0-40ns,80-100ns仍然执行加数指令
40ns到80ns时为6,执行的是我们的存数指令
根据ModelSim仿真图可以知道实验成功