阿里云安全恶意程序检测(速通三)
阿里云安全恶意程序检测
- 特征工程进阶与方案优化
-
- pivot特征构建
-
- pivot特征
- pivot特征构建时间
- pivot特征构建细节特点
- 业务理解和结果分析
-
- 结合模型理解业务
- 多分类问题预测结果分析
- 特征工程进阶
-
- 基于LightGBM模型验证
- 模型结果分析
- 模型测试
- 优化技巧与解决方案升级
-
- 内存管理控制
- 加速数据处理技巧
- 其他开源工具包
- 深度学习解决方案:TextCNN建模
- 开源方案学习
特征工程进阶与方案优化
pivot特征构建
pivot特征
pivot特征,简言之就是采用pandas pivot操作获得的特征。
pivot特征的本质是分层统计特征,同时也是一种组合特征。很多时候因为样本在每层的表现都不一一样,所以需要我们先对特征进行分层,然后在新层对特征进行构建,此时的特征相较于直接用所有层构建得到的特征更加细化,也更具有代表性。
pivot特征构建步骤如下:
(1) tmp= df.groupby (A) [B]agg (opt) .to_ frame © .reset_ index()。
(2) mp_ pivot = pd.pivot _table ( data-tmp,index = A,columns=B,values=C)。
pivot特征构建时间
当样本在同一层不同面的表现有较大区别时,则需要进行pivot特征的构建。比如,我们有用户在不同商店的购物信息,其中商店就是层,而每个不同的商店就是一个面,即层包含多个面。
再如,我们要判断某个用户是不是重要用户,往往会统计用户过去的购物频率。虽然这是一个很不错的方法,但是它反映的信息却很粗,因为小朋友每天去买零食和商业成功人士每天去购买名牌的次数可能一样。但如果此时我们将其按面展开,就可以得到每个用户每天去不同店的购物次数,此时就可以很明显地将二者区分开,信息表示得也更加细致。
pivot特征构建细节特点
pivot特征构建的细节: pivot 层一般是 categorical类别的特征。
pivot特征的优点:表示得更加细致,往往可以获得更好的效果,有时还可以大大提升模型的性能。缺点:会大大增加特征的冗余度,特征展开后经常会带来特征稀疏的问题。此时冗余的特征不仅会加大存储压力,而且也会大大增加模型训练的资源,同时冗余的特征有时也会降低模型的准确性。
业务理解和结果分析
结合模型理解业务
结合模型特征的重要性理解业务:LightGBM等一类基于树的集成模型和我们理解业务的过程类似,都是层层递进的形式。LightGBMtopN重要性的特征往往也是问题的关键所在,可以思考为什么这些特征重要,对业务会产生什么样的影响等。
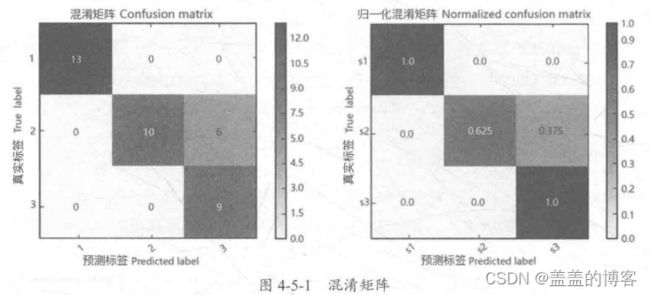
多分类问题预测结果分析
在多分类问题中,我们常常会通过观察预测结果的Confusion Matrix 混淆矩阵,来了解哪一类分得不好、 哪两个类经常混淆、能否通过其他的方式来改进等。常见的有混淆矩阵、归一化混淆矩阵等形式,如图4-5-1所示。
特征工程进阶
每个API调用线程tid的次数
def api_pivot_count_features(df):
tmp = df.groupby(
['file_id',
'api'])['tid'].count().to_frame('api_tid_count').reset_index()
tmp_pivot = pd.pivot_table(data=tmp,
index = 'file_id',
columns = 'api',
values = 'api_tid_count',
fill_value = 0)
tmp_pivot.columns = [
tmp_pivot.columns.names[0] + '_pivot_' + str(col)
for col in tmp_pivot.columns
]
tmp_pivot.reset_index(inplace = True)
tmp_pivot = memory_process._memory_process(tmp_pivot)
return tmp_pivot
每个API调用不同线程tid的次数
def api_pivot_nunique_features(df):
tmp = df.groupby(
['file_id',
'api'])['tid'].nunique().to_frame('api_tid_nunique').reset_index()
tmp_pivot = pd.pivot_table(data=tmp,
index = 'file_id',
columns = 'api',
values = 'api_tid_nunique',
fill_value = 0)
tmp_pivot.columns = [
tmp_pivot.columns.names[0] + '_pivot_' + str(col)
for col in tmp_pivot.columns
]
tmp_pivot.reset_index(inplace = True)
tmp_pivot = memory_process._memory_process(tmp_pivot)
return tmp_pivot
特征获取
%%time
simple_train_fea3 = api_pivot_count_features(train)
simple_test_fea3 = api_pivot_count_features(test)
simple_train_fea4 = api_pivot_nunique_features(train)
simple_test_fea4 = api_pivot_nunique_features(test)
基于LightGBM模型验证
#获取标签
train_label = train[['file_id','label']].drop_duplicates(subset=['file_id','label'],keep='first')
test_submit = test[['file_id']].drop_duplicates(subset=['file_id'],keep='first')
#训练集和测试集的构建,此处将之前提取的特征与新生成的特征进行合并
train_data = train_label.merge(simple_train_fea1,on = 'file_id',how = 'left')
train_data = train_data.merge(simple_train_fea2,on = 'file_id',how = 'left')
train_data = train_data.merge(simple_train_fea3,on = 'file_id',how = 'left')
train_data = train_data.merge(simple_train_fea4,on = 'file_id',how = 'left')
test_submit = test_submit.merge(simple_test_fea1,on = 'file_id',how = 'left')
test_submit = test_submit.merge(simple_test_fea2,on = 'file_id',how = 'left')
test_submit = test_submit.merge(simple_test_fea3,on = 'file_id',how = 'left')
test_submit = test_submit.merge(simple_test_fea4,on = 'file_id',how = 'left')
#关于LGB的自定义评估指标的书写
def lgb_logloss(preds,data):
labels_ = data.get_label()
classes_ = np.unique(labels_)
preds_prob = []
for i in range(len(classes_)):
preds_prob.append(preds[i * len(labels_):(i+1)*len(labels_)])
preds_prob_ = np.vstack(preds_prob)
loss = []
for i in range(preds_prob_.shape[1]): #样本个数
sum_ = 0
for j in range(preds_prob_.shape[0]): #类别个数
pred = preds_prob_[j,i] #第i个样本预测为第j类的概率
if j == labels_[i]:
sum_ += np.log(pred)
else:
sum_ += np.log(1 - pred)
loss.append(sum_)
return 'loss is: ',-1 * (np.sum(loss) / preds_prob_.shape[1]),False
#模型采用5折交叉验证方式
train_features = [
col for col in train_data.columns if col not in ['label','file_id']
]
train_label = 'label'
%%time
from sklearn.model_selection import StratifiedKFold,KFold
params = {
'task':'train',
'num_leaves':255,
'objective':'multiclass',
'num_class':8,
'min_data_in_leaf':50,
'learning_rate':0.05,
'feature_fraction':0.85,
'bagging_fraction':0.85,
'bagging_freq':5,
'max_bin':128,
'random_state':100
}
folds = KFold(n_splits=5,shuffle=True,random_state = 15) #n_splits = 5定义5折
oof = np.zeros(len(train))
predict_res = 0
models = []
for fold_, (trn_idx,val_idx) in enumerate(folds.split(train_data)):
print("fold n°{}".format(fold_))
trn_data = lgb.Dataset(train_data.iloc[trn_idx][train_features],label = train_data.iloc[trn_idx][train_label].values)
val_data = lgb.Dataset(train_data.iloc[val_idx][train_features],label = train_data.iloc[val_idx][train_label].values)
clf = lgb.train(params,
trn_data,
num_boost_round = 2000,
valid_sets = [trn_data,val_data],
verbose_eval = 50,
early_stopping_rounds = 100,
feval = lgb_logloss)
models.append(clf)
模型结果分析
特征相关性分析:计算特征之间的相关性系数,并用热力图可视化显示。
这里采样10000个样本,观察其中20个特征的线性相关性。
plt.figure(figsize = [10,8])
sns.heatmap(train_data.iloc[:10000,1:21].corr())

通过查看特征变量与label的相关性,我们也可以再次验证之前数据探索EDA部分的结论,每个文件调用API的次数与病毒类型是强相关的。
#特征重要性分析
feature_importance = pd.DataFrame()
feature_importance['fea_name'] = train_features
feature_importance['fea_imp'] = clf.feature_importance()
feature_importance = feature_importance.sort_values('fea_imp',ascending = False)
feature_importance.sort_values('fea_imp', ascending = False)
#plt.figure(figsize = [20,10,])
#sns.barplot(x = feature_importance['fea_name'],y = feature_importance['fea_imp'])
plt.figure(figsize = [20,10,])
sns.barplot(x = feature_importance.iloc[:10]['fea_name'],y = feature_importance.iloc[:10]['fea_imp'])

plt.figure(figsize = [20,10,])
sns.barplot(x = feature_importance['fea_name'],y = feature_importance['fea_imp'])

对特征的重要性分析也再一次验证了我们的想法:
API的调用次数及API的调用类别数是最重要的两个特征,也就是说不同的病毒常常会调用不同的API,而且因为有些病毒需要复制自身的原因,调用API 的次数会非常多;第三到第五强的都是线程统计特征,这也较为容易理解,因为木马等病毒经常需要通过线程监听一些内容,所以在线程数量的使用上也会表现的略不相同。
树模型绘制。我们把LightGBM的树模型依次输出,并结合绘制的树模型进行业务的理解。
#树模型绘制。把LightGBM的树模型依次输出,并结合绘制的树模型进行业务的理解
ax = lgb.plot_tree(clf,
tree_index =1,
figsize = (20,8),
show_info = ['split_gain'])
plt.show()
模型测试
优化技巧与解决方案升级
内存管理控制
利用数据类型控制内存。首先判断特征列取值的最小表示范围,然后进行类型转换,如float64转换为float16 等。
加速数据处理技巧
1.加速Pandas的merge
当数据量较大时,Pandas的merge操作相比基于object的merge操作耗时,在比赛中index经常会编码成一个非常复杂的字符串序列,此时我们可以直接将index编码为简单的数字,然后存储映射的字典,再对数字进行merge,最后通过字典映射回来。
2.加速Pandas分位数的特征提取
在比赛中经常会遇到提取各种分位数的问题,这时有些选手经常会枚举分位数特征,但如果每次都自定义一个分位数提取函数会极其耗时。这时就可以考虑将所有分位数的提取用一个函数实现,返回一个分位数的list,这样就无须再进行多次分位数的提取了。
3.用Numpy替换Pandas
由于Numpy的操作比Pandas操作得快,因此当Pandas全部是数值等特征时,可以考虑,将其转换为Numpy再进行特征提取。
其他开源工具包
- Github的Dask
- Github的Numba