模糊C均值聚类算法
学习了一下模糊聚类中的模糊 C 均值聚类算法 (Fuzzy C-Means Clustering)。
Fuzzy 意为模糊,其中包括几种模糊的方式,这里使用的是最简单的方式,它是基于概率的概念。我们把每一个点属于每一类的概率值求出,它属于哪一类别的概率最大,我们就将其归于哪一类。
这里的 C 其实对应于 K-means 中的 K。其中,K-means 中的 K 决定类别数。同样的,C 也是决定类别数。
首先我们介绍该算法的目标函数。
当分类时,我们希望类内距离要越小越好(越集中越好),类与类之间的距离要越大越好。而 Fuzzy C-Means 只用到第一个概念 (类内距离要越小越好)。如果我们同时考虑类与类之间的距离,那么分类效果自然会得到提升。所以还有很多种不同的方式。
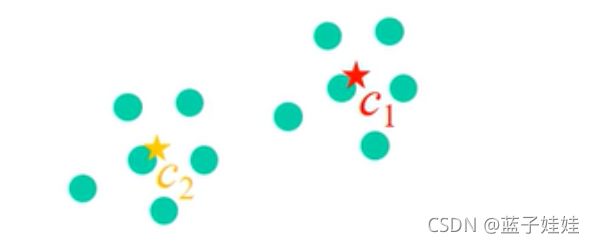
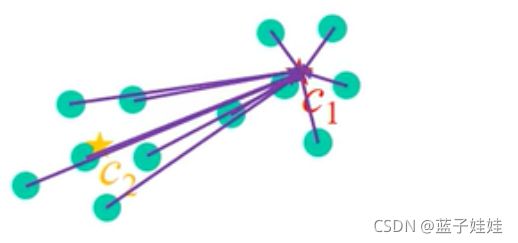
下图中,假设红星是 c 1 c_1 c1 的中心,黄星是 c 2 c_2 c2 的中心。
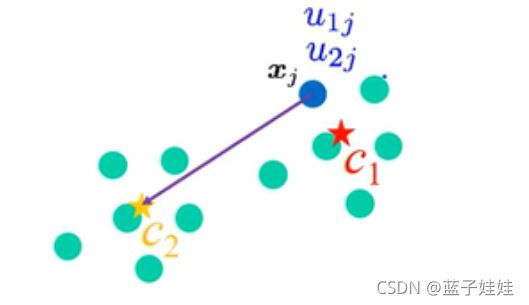
我们给每一个点赋予到每一个类别中心的几率值,如下图中, x j x_j xj 到 c 1 c_1 c1 中心点的几率值为 u 1 j u_{1j} u1j,其中 1 表示类别数,j 表示哪一个点。我们将 u 1 j u_{1j} u1j 称为隶属值 (membership values),代表点 j 隶属于第一类概率是多少。

那么,也就有点 j j j 隶属于第2类的概率 u 2 j u_{2j} u2j。
依次类推,如果有 3 类,点 j j j 就有 3 个隶属值;有 n n n 类,就有 n n n 个隶属值。并且需要满足 u 1 j + u 2 j + ⋯ + u n j = 1 u_{1j} + u_{2j} + \dots + u_{nj} = 1 u1j+u2j+⋯+unj=1,例子中为 u 1 j + u 2 j = 1 u_{1j} + u_{2j} = 1 u1j+u2j=1.
接下来,我们希望点 j j j 到 c 1 c_1 c1 的距离越小越好,到 c 2 c_2 c2 的距离越大越好。所以与 K-means 类似,我们需要先算距离。

那么,我们给两段距离分别称上相应的几率值。
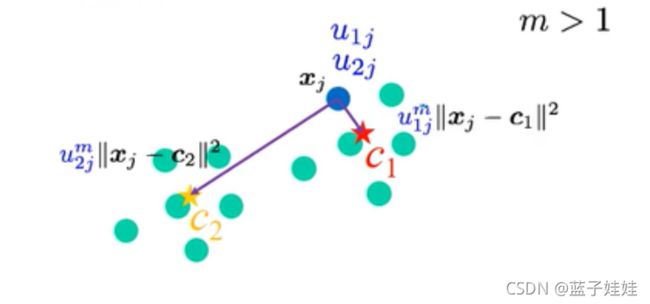
从图中可以看到,几率值上面多了一个 m m m ,这个 m m m 就是 Fuzzifier m m m,用来控制每一段距离重要性的大小,如图上所示, u 1 j u_{1j} u1j 应该比较大,比如 0.8, u 2 j u_{2j} u2j 比较小,如 0.2。
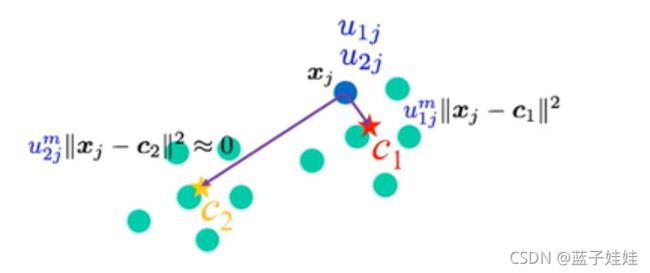
如果 u 2 j m ∥ x j − c 2 ∥ ≈ 0 u_{2j}^m \| x_j - c_2\| ≈ 0 u2jm∥xj−c2∥≈0,那么就会忽略 x j x_j xj 到 c 2 c_2 c2 的距离,只会算 u 1 j m ∥ x j − c 1 ∥ u_{1j}^m \| x_j - c_1\| u1jm∥xj−c1∥ 。
那么扩展到每一个点,就会得到如下式子:
∑ j = 1 N u 1 j m ∥ x j − c 1 ∥ 2 = u 1 , 1 m ∥ x 1 − c 1 ∥ 2 + u 1 , 2 m ∥ x 2 − c 1 ∥ 2 + ⋯ + u 1 , N m ∥ x N − c 1 ∥ 2 \sum_{j=1}^N u_{1j}^m\| x_j - c_1\|^2 = u_{1,1}^m\| x_1 - c_1\|^2 + u_{1,2}^m\| x_2 - c_1\|^2 + \dots + u_{1,N}^m\| x_N - c_1\|^2 j=1∑Nu1jm∥xj−c1∥2=u1,1m∥x1−c1∥2+u1,2m∥x2−c1∥2+⋯+u1,Nm∥xN−c1∥2
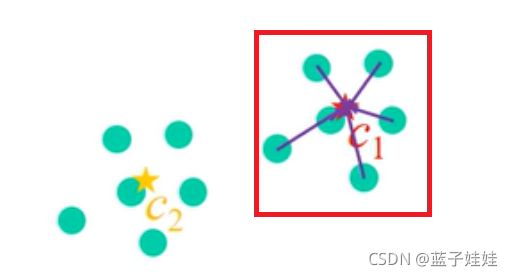
当我们将 membership values 考虑在内时,到 c 2 c_2 c2 的 membership values 会很小,最后乘上距离会场趋近于 0,所以,最后问题近似简化成了只考虑红色区块而已,我们希望距离和越小越好。
以此类推,得到:
∑ j = 1 N u 2 j m ∥ x j − c 2 ∥ 2 = u 2 , 1 m ∥ x 1 − c 2 ∥ 2 + u 2 , 2 m ∥ x 2 − c 2 ∥ 2 + ⋯ + u 2 , N m ∥ x N − c 2 ∥ 2 \sum_{j=1}^N u_{2j}^m\| x_j - c_2\|^2 = u_{2,1}^m\| x_1 - c_2\|^2 + u_{2,2}^m\| x_2 - c_2\|^2 + \dots + u_{2,N}^m\| x_N - c_2\|^2 j=1∑Nu2jm∥xj−c2∥2=u2,1m∥x1−c2∥2+u2,2m∥x2−c2∥2+⋯+u2,Nm∥xN−c2∥2
同样也希望距离和越小越好,那么该栗子的损失函数就是希望 ∑ j = 1 N u 1 j m ∥ x j − c 1 ∥ 2 \sum_{j=1}^N u_{1j}^m\| x_j - c_1\|^2 ∑j=1Nu1jm∥xj−c1∥2 和 ∑ j = 1 N u 2 j m ∥ x j − c 2 ∥ 2 \sum_{j=1}^N u_{2j}^m\| x_j - c_2\|^2 ∑j=1Nu2jm∥xj−c2∥2 越小越好,合为一个式子得到:
J = ∑ i = 1 2 ∑ j = 1 N u i j m ∥ x j − c i ∥ 2 = ∑ j = 1 N u 1 j m ∥ x j − c 1 ∥ 2 + ∑ j = 1 N u 2 j m ∥ x j − c 2 ∥ 2 J = \sum_{i=1}^2 \sum_{j=1}^N u_{ij}^m \| x_j - c_i\|^2 = \sum_{j=1}^N u_{1j}^m \| x_j - c_1\|^2 + \sum_{j=1}^N u_{2j}^m\| x_j - c_2\|^2 J=i=1∑2j=1∑Nuijm∥xj−ci∥2=j=1∑Nu1jm∥xj−c1∥2+j=1∑Nu2jm∥xj−c2∥2
其中, c c c 和 u u u 是未知的。并且满足如下式子:
∑ i = 1 2 u i 1 = u 1 , 1 + u 2 , 1 = 1 … ∑ i = 1 2 u i N = u 1 , N + u 2 , N = 1 \sum_{i=1}^2 u_{i1} = u_{1,1} + u_{2,1} = 1 \\ \dots \\ \sum_{i=1}^2 u_{iN} = u_{1,N} + u_{2,N} = 1 i=1∑2ui1=u1,1+u2,1=1…i=1∑2uiN=u1,N+u2,N=1
将损失函数推广到一般情况为:
J ( u i j , c i ) = ∑ i = 1 K ∑ j = 1 N u i j m ∥ x j − c i ∥ 2 J(u_{ij}, c_i) = \sum_{i=1}^K \sum{j=1}^N u_{ij}^m \| x_j - c_i\|^2 J(uij,ci)=i=1∑K∑j=1Nuijm∥xj−ci∥2
其中, ∑ i = 1 K u i j = 1 , j = 1 , 2 , … , N \sum_{i=1}^K u_{ij} = 1, j = 1,2, \dots, N ∑i=1Kuij=1,j=1,2,…,N
举个例子,假设我们有如下4个点,需要将其分为两类。

我们根据距离可能会将 x 1 , x 2 x_1, x_2 x1,x2 分为一类, x 3 , x 4 x_3, x_4 x3,x4 分为一类。
假设我们知道了第一类的中心为 c 1 c_1 c1,第二类中心为 c 2 c_2 c2。那么我们计算损失为:
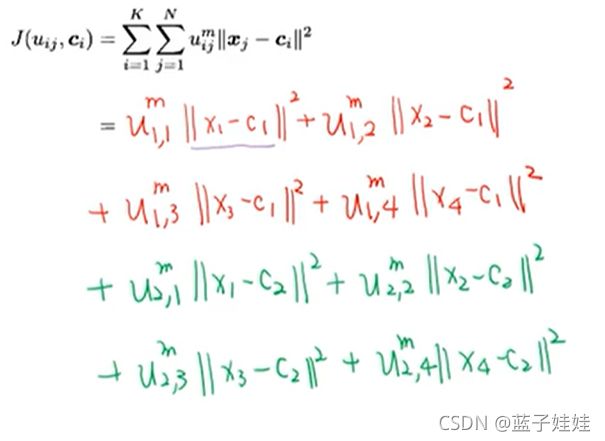
代入距离为:

如上图如式,当我们已知中心点,那么最后损失函数只与 u u u 相关,我们希望 J J J 越小越好。
反过来,当我们知道了 U U U 值,那么最后 J J J 只与 c c c 相关。

我们的损失函数中的未知量为 c c c 和 U U U,那么怎么求解以下这种有限制条件的最小值问题,通常的解决方法是使用拉格朗日进行求解。

我们的每一个限制条件都需要一个拉格朗日因子。如下图所示,对于点 x 1 x_1 x1,有隶属值 u 11 u_{11} u11 和 u 21 u_{21} u21,满足条件 u 11 + u 21 = 1 u_{11} + u_{21} = 1 u11+u21=1,这里的限制条件用一个拉格朗日因子 λ 1 \lambda_1 λ1 表示;同样的对于点 点 x 2 x_2 x2,有隶属值 u 12 u_{12} u12 和 u 22 u_{22} u22,满足条件 u 12 + u 22 = 1 u_{12} + u_{22} = 1 u12+u22=1,这里的限制条件用一个拉格朗日因子 λ 2 \lambda_2 λ2 表示,依此类推,例子中共有10个点,就有10个限制条件,相应的有10个拉格朗日因子。
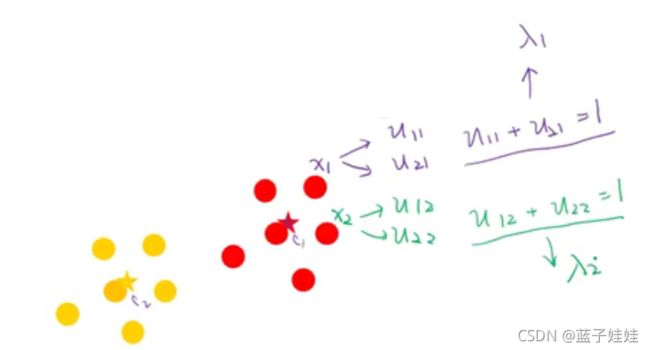
那么,我们的损失函数变为:
L ( u i j , c i , λ j ) = ∑ i = 1 K ∑ j = 1 N u i j m ∥ x j − c i ∥ 2 − λ 1 ( ∑ i = 1 K u i 1 − 1 ) − λ 2 ( ∑ i = 1 K u i 2 − 1 ) − ⋯ − λ N ( ∑ i = 1 K u i N − 1 ) = ∑ i = 1 K ∑ j = 1 N u i j m ∥ x j − c i ∥ 2 − ∑ j = 1 N λ j ( ∑ i = 1 K u i j − 1 ) \mathcal{L}(u_{ij}, c_i, \lambda_j) = \sum_{i=1}^K \sum_{j=1}^N u_{ij}^m \| x_j - c_i\|^2 - \lambda_1 \left(\sum_{i=1}^K u_{i1} - 1\right) - \lambda_2 \left(\sum_{i=1}^K u_{i2} - 1 \right) - \dots - \lambda_N \left(\sum_{i=1}^K u_{iN} - 1 \right)\\ = \sum_{i=1}^K \sum_{j=1}^N u_{ij}^m \| x_j - c_i\|^2 - \sum_{j=1}^N \lambda_j \left(\sum_{i=1}^K u_{ij} - 1 \right) L(uij,ci,λj)=i=1∑Kj=1∑Nuijm∥xj−ci∥2−λ1(i=1∑Kui1−1)−λ2(i=1∑Kui2−1)−⋯−λN(i=1∑KuiN−1)=i=1∑Kj=1∑Nuijm∥xj−ci∥2−j=1∑Nλj(i=1∑Kuij−1)
其中 ∑ i = 1 K u i 1 − 1 \sum_{i=1}^K u_{i1} - 1 ∑i=1Kui1−1 是限制条件 ∑ i = 1 K u i 1 = 1 \sum_{i=1}^K u_{i1} =1 ∑i=1Kui1=1 移项所得。
我们将 L \mathcal{L} L 第一部分展开,可得:
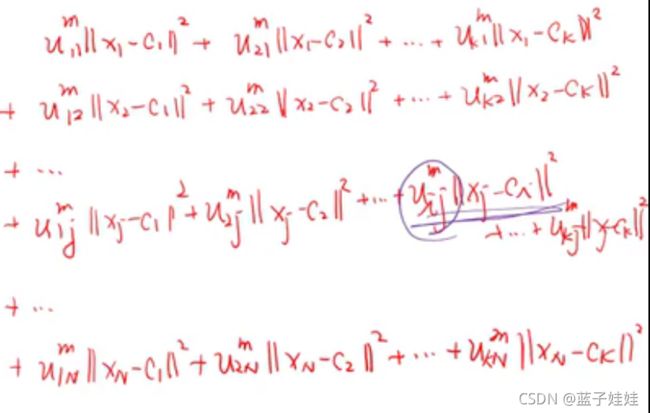
现在我们要求 L \mathcal{L} L 对 u i j u_{ij} uij 的微分,根据上图展开式发现只有一项包含 u i j u_{ij} uij,其余微分时均可看作常量。对于第二项,可以使用相同的方法展开,可得:

那么
∂ L ∂ u i j = m u i j m − 1 ∥ x j − c i ∥ 2 − λ j = 0 = > u i j m − 1 = λ j m ∥ x j − c i ∥ 2 = ( λ j m ) 1 ∥ x j − c i ∥ 2 = > u i j = ( λ j m ) 1 m − 1 1 ∥ x j − c i ∥ 2 m − 1 \frac{\partial \mathcal{L}}{\partial u_{ij}} = mu_{ij}^{m-1} \| x_j - c_i\|^2 - \lambda_j = 0 \\ => u_{ij}^{m-1} = \frac{\lambda_j}{m\|x_j - c_i \|^2} \\ = \left(\frac{\lambda_j}{m}\right) \frac{1}{\| x_j - c_i\|^2} \\ => u_{ij} = \left(\frac{\lambda_j}{m}\right)^{\frac{1}{m-1}} \frac{1}{\| x_j - c_i\|^{\frac{2}{m-1}}} ∂uij∂L=muijm−1∥xj−ci∥2−λj=0=>uijm−1=m∥xj−ci∥2λj=(mλj)∥xj−ci∥21=>uij=(mλj)m−11∥xj−ci∥m−121
但是,式子中仍有 λ j \lambda_j λj 是未知的,但是我们还有一个限制条件 ∑ i = 1 K u i j = 1 \sum_{i=1}^K u_{ij} = 1 ∑i=1Kuij=1.
将其代入可以得:
∑ i = 1 K u i j = ∑ i = 1 K ( λ j m ) 1 m − 1 1 ∥ x j − c i ∥ 2 m − 1 = ( λ j m ) 1 m − 1 ∑ i = 1 K 1 ∥ x j − c i ∥ 2 m − 1 = 1 = > ( λ j m ) 1 m − 1 = 1 ∑ l = 1 K 1 ∥ x j − c l ∥ 2 m − 1 \sum_{i=1}^K u_{ij} = \sum_{i=1}^K \left(\frac{\lambda_j}{m}\right)^{\frac{1}{m-1}} \frac{1}{\| x_j - c_i\|^{\frac{2}{m-1}}} \\ = \left(\frac{\lambda_j}{m}\right)^{\frac{1}{m-1}} \sum_{i=1}^K \frac{1}{\| x_j - c_i\|^{\frac{2}{m-1}}} = 1 \\ => \left(\frac{\lambda_j}{m}\right)^{\frac{1}{m-1}} = \frac{1}{\sum_{l=1}^K \frac{1}{\| x_j - c_l\|^{\frac{2}{m-1}}}} i=1∑Kuij=i=1∑K(mλj)m−11∥xj−ci∥m−121=(mλj)m−11i=1∑K∥xj−ci∥m−121=1=>(mλj)m−11=∑l=1K∥xj−cl∥m−1211
将得到的 $ (\frac{\lambda_j}{m})^{\frac{1}{m-1}} $ 代入 u i j u_{ij} uij 可得:
u i j = 1 ∑ l = 1 K 1 ∥ x j − c l ∥ 2 m − 1 ⋅ 1 ∥ x j − c i ∥ 2 m − 1 = 1 ∥ x j − c i ∥ 2 m − 1 ∑ l = 1 K 1 ∥ x j − c l ∥ 2 m − 1 u_{ij} = \frac{1}{\sum_{l=1}^K \frac{1}{\| x_j - c_l\|^{\frac{2}{m-1}}}} \cdot \frac{1}{\| x_j - c_i\|^{\frac{2}{m-1}}} \\ = \frac{\frac{1}{\| x_j - c_i\|^{\frac{2}{m-1}}}}{\sum_{l=1}^K \frac{1}{\| x_j - c_l\|^{\frac{2}{m-1}}}} uij=∑l=1K∥xj−cl∥m−1211⋅∥xj−ci∥m−121=∑l=1K∥xj−cl∥m−121∥xj−ci∥m−121
现在还是以最开始的栗子为例,现有一点 x j x_j xj 到 c 1 c_1 c1 的距离为 ∥ x j − c 1 ∥ 2 \| x_j - c_1\|^2 ∥xj−c1∥2,到 c 2 c_2 c2 的距离为 ∥ x j − c 2 ∥ 2 \| x_j - c_2\|^2 ∥xj−c2∥2, x j x_j xj 应该属于距离近的一类。
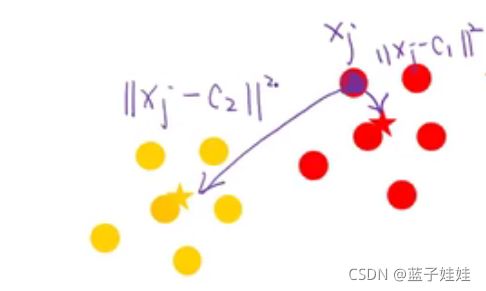
那么怎么表示距离近呢?我们把距离取倒数,距离越近,倒数就越大。
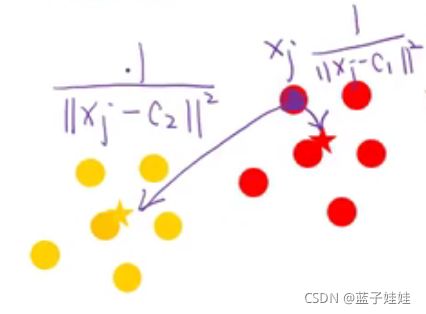
要满足 u 1 j + u 2 j = 1 u_{1j} + u_{2j} = 1 u1j+u2j=1,类似于数据归一化。我们可以得到:
u 1 j = 1 ∥ x j − c 1 ∥ 2 1 ∥ x j − c 1 ∥ 2 + 1 ∥ x j − c 2 ∥ 2 u 2 j = 1 ∥ x j − c 2 ∥ 2 1 ∥ x j − c 1 ∥ 2 + 1 ∥ x j − c 2 ∥ 2 u_{1j} = \frac{\frac{1}{\| x_j - c_1\|^2}}{\frac{1}{\| x_j - c_1\|^2} + \frac{1}{\| x_j - c_2\|^2}} \\ u_{2j} = \frac{\frac{1}{\| x_j - c_2\|^2}}{\frac{1}{\| x_j - c_1\|^2} + \frac{1}{\| x_j - c_2\|^2}} u1j=∥xj−c1∥21+∥xj−c2∥21∥xj−c1∥21u2j=∥xj−c1∥21+∥xj−c2∥21∥xj−c2∥21
以上就是 L \mathcal{L} L 对 u i j u_{ij} uij 微分的推导过程。那么 L \mathcal{L} L 对 c i c_i ci 微分类似。
∂ L ∂ c i = ∑ j = 1 N u i j m ⋅ 2 ⋅ ( x j − c i ) ⋅ ( − 1 ) = ∑ j = 1 N ( − 2 ) ⋅ u i j m ( x j − c i ) = 0 = > ∑ j = 1 N u i j m x j − ( ∑ j = 1 N u i j m ) c i = 0 = > c i = ∑ j = 1 N u i j m x j ∑ j = 1 N u i j m \frac{\partial \mathcal{L}}{\partial c_i} = \sum_{j=1}^N u_{ij}^m \cdot 2 \cdot ( x_j - c_i) \cdot (-1) \\ = \sum_{j=1}^N (-2) \cdot u_{ij}^m (x_j - c_i) = 0 \\ => \sum_{j=1}^N u_{ij}^m x_j - \left(\sum_{j=1}^N u_{ij}^m \right)c_i = 0 \\ => c_i = \frac{\sum_{j=1}^N u_{ij}^m x_j}{\sum_{j=1}^N u_{ij}^m} ∂ci∂L=j=1∑Nuijm⋅2⋅(xj−ci)⋅(−1)=j=1∑N(−2)⋅uijm(xj−ci)=0=>j=1∑Nuijmxj−(j=1∑Nuijm)ci=0=>ci=∑j=1Nuijm∑j=1Nuijmxj
那么该算法的流程大致如下;
- Initialize the membership values u i j u_{ij} uij.
- At t t t-step: calculate the centers by
c i = ∑ j = 1 N u i j m x j ∑ j = 1 N u i j m c_i = \frac{\sum_{j=1}^N u_{ij}^m x_j}{\sum_{j=1}^N u_{ij}^m} ci=∑j=1Nuijm∑j=1Nuijmxj - Update u i j u_{ij} uij by
u i j = 1 ∥ x j − c i ∥ 2 m − 1 ∑ l = 1 K 1 ∥ x j − c l ∥ 2 m − 1 u_{ij} = \frac{\frac{1}{\| x_j - c_i\|^{\frac{2}{m-1}}}}{\sum_{l=1}^K \frac{1}{\| x_j - c_l\|^{\frac{2}{m-1}}}} uij=∑l=1K∥xj−cl∥m−121∥xj−ci∥m−121 - Compute the value of the objective function J ( t ) J^{(t)} J(t),
J ( t ) = ∑ i = 1 K ∑ j = 1 N u i j m ∥ x j − c i ∥ 2 J^{(t)} = \sum_{i=1}^K \sum_{j=1}^N u_{ij}^m \| x_j - c_i\|^2 J(t)=i=1∑Kj=1∑Nuijm∥xj−ci∥2 - If ∣ J ( t ) − J ( t − 1 ) ∣ < ϵ |J^{(t)} - J^{(t-1)} | < \epsilon ∣J(t)−J(t−1)∣<ϵ, then stop; otherwise return to step 2.