Metropolis Light Transport学习与实现
这段时间一直在看Metropolis Light Transport(简称mlt),现利用这篇博文把之前看资料已经coding上的一些体会记录下来。
1.Before MLT
在MLT算法被提出之前,最热的GI算法bidirectional path tracing虽然对比于basic path tracing已经有了效率上的明显提高,但是对于复杂场景的表现力仍显不足。那时候人们已经知道基于path的GI算法的效率关键在于找到有效路径的效率。先说有效路径是什么,简单地说就是从光源出发,在场景中反弹数次最终到达视点的过程中的一系列点和边。但是要想找到一条有效的路径并不是简单的事情,来看看早期的经典算法是怎么处理这个问题的:
basic path tracing:最早的path tracing是从视点出发射出ray,不断在场景中反射,最终如果射中光源,那么一条有效路径就产生了,这时候就可以用这条路径来参与计算该像素的颜色值,这个算法的问题在于场景中光源体积一般比较小,会导致大量的ray最后都不能击中光源(理论上说如果ray的长度可以无限长的话,在封闭的环境中是一定能击中光源的,但是这在实际coding的时候是不可能的),那么没有击中光源的ray就不是一条有效路径,对最终像素颜色值的贡献为0。所以basic path tracing的有效路径搜寻效率是非常低的,从结果上来看就是图像的噪声非常明显,求解收敛速度慢。
monte carlo light tracing:该算法从光源发射ray,在场景中反弹,每次击中场景中的物体表面都判断一下是否可以与视点连接成为有效路径(主要检查交点是否在视平面内,与视点的连线是否有遮挡,bsdf能否采样到这个方向等)。这个算法的主要问题在于如果渲染的图片是一个很大场景的很小一部分,就会导致采样到大量的无效路径,与此同时,每一条路径都要进行一次可见性判断,也会加大计算量,复杂的场景会导致大量落在视平面内的点其实是视点不可见的(被遮挡),进一步减少有效路径的搜索效率,这是basic path tracing所不需要做的事情。但是由于是从光源出发,所以在小光源的环境下比basic path tracing更加有优势。
bidirectional path tracing:BDPT综合了前两者的优点,分别从光源和视点发射两条ray生成两条path(light path和eye path),然后对两条路径上的点进行连接来找寻有效路径,这样就极大得增加了有效路径的搜寻效率,特别是在主要靠间接光照明的场景,无论path tracing还是light tracing都很难找到有效路径,但是BDPT算法,只要生成的两条路径中有两个点可以相连,那么一条有效路径就诞生了。实际上path tracing和light tracing都可以看成是BDPT中的特例而已(L=0 path和E=0 path),并且通常情况下这些路径得到的结果的噪声都比较大,所以在实际coding中会利用multiple importance sampling来控制噪声。
然而,即使是bdpt也会在某些复杂的场景下对有效路径的搜寻效率低下,比如一些大楼的内部结构,光线必须进过几个房间的反射与传播才能到达视点的场景,即使通过BDPT算法,也很难搜索出一条有效的路径,同时bdpt对一些复杂的焦散效果的表现力也并不理想,对于一般的焦散现象,BDPT主要通过E=1 path来解决的,而coding的时候这类路径通常又是在后处理中单独处理的,所以实际效果不见得太好,对于LSDSE的路径就更难以捕捉了,比如下面的图中蓝色的圈内本应该折射看到地面的焦散亮斑,但是结果图中却没有看到:

2.Original MLT
Metropolis Light Transport方法最早由Veach于1997年提出,其根本目的也是为了更效率地寻找有效路径,以及找到对结果影响更大的路径。如何衡量一调路径对结果颜色值影响的大小并没有唯一的标准,但很多地方把亮度值作为一个标准,亮度值在之前的"bloom特效"文章中已经讲到过:Y=0.299R+0.587G+0.114B。MLT算法将物理上的Metropolis方法运用到了GI算法的路径采样中,其核心思想在于,一旦发现对结果影响更大的有效路径后,Metropolis采样方法就会在path space中该路径临近的区域继续采样,使得得到的路径对结果的影响较大的可能性更大。这里有一个假设,就是在path space中一条高贡献度路径周围的路径也很可能是高贡献度的,实际上很多情况下也都是成立的,比如焦散区域。再举一个形象的例子,比如在下图中光源和视点分布位于两个房间,房间通过一个狭小的孔相连:

假设已经采样到一条有效路径P后(橙色路径),MLT算法在path space相邻区域采样可以很容易地得到另外一条有效路径P'(绿色的路径),而BDPT则是完全重新搜索路径,很可能得到的下面一条路径是一条无效路径(光线没有能够通过这个狭小的口子到达另外一个房间),这个例子解释了为什么在一些复杂的场景下MLT的效果会比BDPT好。下面这段伪代码描述了整个MLT算法的核心:

很容易可以理解到算法的过程,在通过INITIALPATH()找到一条有效路径x后,对x进行变异得到y,计算接受概率a,如果新路径y被接受,那么下一次变异则从y开始进行,否则还是继续从x开始进行,最后记录该路径的颜色贡献值到图像(如果变异被接受,则记录路径y的贡献度;否则记录x)。
由此可见,MLT采样的过程是上下关联的,也就是说下一次采样的结果路径依赖于上一次的路径,这种关联性虽然使得有效路径的搜索效率更高,但是也会增加算法的误差,在结果上体现为噪声和错误,但是在大量的采样下,这些误差会趋近为0。另一方面,我们不禁会担心另外一个问题,MLT算法的这种采样关联性会不会一直在某个高贡献度区域采样而忽略了其他区域,比如下图的这种情况:
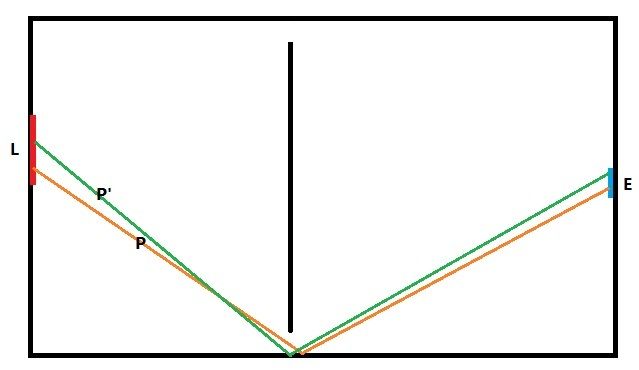
光源是可以通过上下两个孔到达视点的,而由于INITIALPATH的时候采样到的是下面的这条路径P,所以MLT算法很可能一直采样到通过下面这个孔的路径,而忽略了上面的孔导致最终结果出现错误。这也就是MLT算法的遍历性问题,简单来说MLT采样能不能在足够多样本后遍历整个path space。这个问题有个极其简单的解决办法,就是每经过若干次路径变异之后,重新INITIALPATH一次,得到一条与之前路径无关的新路径。最后还是要说说这个接受几率a(算法中的ACCEPTPROB):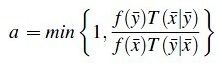 ,其中T函数是路径变异概率,比如从路径x变异到路径y的概率,f函数就是路径贡献度了,假如T(x|y)=T(y|x),而f(y)>f(x)的话,a就一定等于1,也就是说一定发生变异;反之,在新找到的路径贡献度比老路径小的时候,也有一定几率产生变异代替老的路径,这样的好处在于,采样过程不会在一个f函数的峰值一直逗留,也有机会发现其他的峰值,当然光靠这一点这完全不能保证MLT算法能够遍历整个path space,一定数量的re-initialpath过程还是必要的。
,其中T函数是路径变异概率,比如从路径x变异到路径y的概率,f函数就是路径贡献度了,假如T(x|y)=T(y|x),而f(y)>f(x)的话,a就一定等于1,也就是说一定发生变异;反之,在新找到的路径贡献度比老路径小的时候,也有一定几率产生变异代替老的路径,这样的好处在于,采样过程不会在一个f函数的峰值一直逗留,也有机会发现其他的峰值,当然光靠这一点这完全不能保证MLT算法能够遍历整个path space,一定数量的re-initialpath过程还是必要的。
变异函数的选择也关系到整个算法的效率,在Veach的论文(ROBUST MONTE CARLO METHODS FOR LIGHT TRANSPORT SIMULATION)中,Veach使用了几种变异策略:Bidirectional mutations(随机删除中间的部分路径,再添加一段随机路径,这个应该是整个变异方法的主体,特别适用于处理漫反射场景);Lens perturbations(主要针对LDSE路径作随机扰动,用于处理镜面反射);Caustic perturbations(针对LSDE路径作微扰,用于处理焦散);Multi-chain perturbations(这个变异方法主要为了解决bdpt中对于LSDSE这一类路径没有很好的采集方法的问题,实际上我认为即使是MLT对这一类的路径的搜索也是效率低下的);Lens subpath mutations(主要用于LS+E,比如通过镜面看到的光源)。这种MLT算法就是最基本的MLT算法,相对于BDPT来说在复杂场景中(特别是主要由间接光照明的场景)效率一般更高,而且可以更好地处理BDPT很难处理的LSDSE这类路径,并且还是无偏的算法。但是最大的问题是,它的实现太复杂了,主要源于它复杂的变异函数是基于path space进行变异的,后来的PSSMLT算法就针对这一点进行了改进。
3.PSSMLT
Primary Sample Space Metropolis Light Transport (PSSMLT)由Csaba Kelemen等人于2002年提出(A simple and robust mutation strategy for the metropolis light transprot algorithm)。算法主要针对变异函数进行改进,它对在构造路径时使用到的随机数进行扰动,从而获得新的路径。比如在构造一条初始路径的时候我们会在光源取点,光源随机发射方向,以及中途与物体相交的时候求取反射方向等地方用到随机数,那么在变异的时候我们只需要对这些随机数作一个微扰,就能得到新的路径,而这条路径成为高贡献度有效路径的可能性也是很高的。为了记录随机数,以及对其进行扰动,PSSMLT算法需要做一些额外的开销,这使得它在处理简单场景(比如主要由直接光照明的场景)的时候效率反而更低,但是对比original MLT,它更简洁,容易实现。实际上,我在上网查找代码的时候,能找到的MLT代码几乎都是PSSMLT(除了Mitsuba,它把两种MLT算法都实现过了)。PSSMLT也要面对算法遍历性的问题,它使用一个large_step标示符来指示当前变异是小扰动还是大的变异。由于是针对随机数空间进行变异,PSSMLT可以使用basic path tracing,light tracing,甚至bidirectional path tracing来作为变异模板,我自己实现了一个简单的使用bdpt作为模板的PSSMLT算法,其实思想还是很简单的,每次用bdpt找到有效路径之后,分别对其eye path和light path进行Primary Sample Space上的扰动,形成新的eye path和light path,由于bdpt中一条eye path和light path可能连接处多条有效路径,所以贡献度函数f的选择要考虑多条有效路径的贡献度,或者也可以让它等于这些有效路径中贡献度最大的那个值。变异距离也很关键,我这边采用的是论文中默认的参数:
double s1 = 1/1024., s2 = 1/16.;
double dx = s2 * exp(-log(s2/s1) * random());
下面两张图是同一个场景在bdpt(上)和pssmlt(下)下几乎相同的时间中的渲染效果,由于场景主要由间接光照明,pssmlt得到的结果噪点会少很多:

4.小结
初步完成了pssmlt的实现,感觉还是不错的,但是在实现上总还是有一些BUG没有完全处理掉,没有达到自己预想的那样好,程序上需要改进的地方还太多,同时pssmlt之后还有很多改进的文章可以看看,总之还得继续努力!
新的一年到了,也在此给自己和其他还在辛苦工作着的程序员们打打气!加油!