《编程之美》 2.19 解法二需要在一个数组 arr[] 中找到最后一个≤ value 的值,可以顺序查找,也可以使用二分查找。但标准的二分查找用来查找 =value 的值,因此这里需要改造一下:
1. 标准二分查找:
注意:退出原因有两个——“ arr[mid]==value ,即找到” 或者 “ l==r 且仍未找到”
(这个版本代码根据《编程珠玑》)
private static void find(int[] arr, int value){
int l=0,r=arr.length-1;
int mid=(l+r)/2;
while(arr[mid]!=value && l<=r){
if(arr[mid]<value){
l=mid+1;
}else{
//arr[mid]>value
r=mid-1;
}
mid=(l+r)/2;
}
if(arr[mid]==value){
System.out.println(arr[mid]);
}else{
//退出原因:l==r
System.out.println("不存在!");
}
}
2. 查找最后一个属性为true的元素
如果一个数组的某个维度属性值依次为:{true, true, ... , true, false, false, ... , false}. 查找最后一个属性为true的元素的位置。
这种变体和标准二分查找最大的区别在于每次进入循环时不用判断是否找到满足条件的点。在变体中,这样的点往往不只一个,而有很多,我们要找的是最后一个满足条件的点:)
(如果至少有一个true的话)
1). 每次进入循环while(l<=r)时,闭区间[l,r]都至少包括了“最后一个true的位置”和“第一个false的位置”两者之一。
2). 任意满足l<=r的l,r都可以转化成以下两大类情况,即最后一次进入while(l<=r)时必定是以下两种情况之一:
情况一: r-l==0
情况二: r-l==1
后面的示意图中会对这两种情况进行详细讨论,可以看到循环结束时mid均指向最后一个true的位置。
注:对于数组a[],对于任意i∈[0,n-2],都有(a[i]+a[i+1])/2=a[i]. 这和i的奇偶性是无关的。
这种变体在二分答案中经常用到,并且可以看做是下面“查找最后一个≤value值”的基础。


代码: 综上,调用bin_search(arr, 0, len),将返回最后一个true的位置;若不存在true则返回0.
#include<iostream>
using namespace std;
bool arr1[]={true,true,true,true,false,false,false,false};
bool arr2[]={true,true,false,false,false};
int bin_search(bool* arr, int l, int r){
int mid=(l+r)>>1;
while(l<=r){
cout<<"l="<<l<<", r="<<r<<", mid="<<mid<<endl;
if(arr[mid])
l=mid+1;
else
r=mid-1;
mid=(l+r)>>1;
}
//退出上面while(l<=r)循环时,mid指向最后一个true的位置
if(arr[mid])
return mid;
else
return 0;
}
int main(){
cout<<bin_search(arr1,0,7)<<endl;
cout<<bin_search(arr2,0,4)<<endl;
system("pause");
return 0;
}
其实根本没有上面那么麻烦,只需要最后判断“mid当前位置”和“mid-1位置”即可
#include <iostream>
#include <algorithm>
using namespace std;
int bs(int *arr,int ll, int rr, int v){
int res=-1;
int l = ll;
int r = rr;
int mid=(l+r)>>1;
while(l<r){
if(arr[mid]<=v){
l=mid+1;
}else if(arr[mid]>v){
r=mid-1;
}
mid=(l+r)>>1;
}
if(arr[mid]<=v){
res=mid;
}else{
if(mid-1>=l){
if(arr[mid-1]<=v){
res=mid-1;
}else{
res=-1;
}
}else{
res=-1;
}
}
return res;
}
int main()
{
int arr0[]={4};
cout<<bs(arr0,0,0,8); //0
int arr1[]={4,5};
cout<<bs(arr1,0,1,8); //1
int arr2[]={9,10,23};
cout<<bs(arr2,0,2,8); //-1
int arr3[]={8,9,10,23};
cout<<bs(arr3,0,3,8); //0
int arr4[]={8,8,9,10,23};
cout<<bs(arr4,0,4,8); //1
int arr5[]={8,8,8,8,8};
cout<<bs(arr5,0,4,8); //4
int arr6[]={7,8,9,10,23};
cout<<bs(arr6,0,4,8); //1
int arr7[]={8};
cout<<bs(arr7,0,0,8); //0
int arr8[]={10};
cout<<bs(arr8,0,0,8); //-1
return 0;
}
3. 查找最后一个≤ value 的元素
将“≤value的元素”看做属性为true,将“>value的元素”看做属性为false,这样“3 查找最后一个≤value的元素”就转换为“2. 查找最后一个属性为true的元素”. 直接套用上面的过程即可,分析同上:)
代码:
#include<iostream>
using namespace std;
int arr1[]={1,2,3,4,6,7,8};
int arr2[]={1,2,3,4,6,7};
int bin_search(int* arr, int l, int r, int k){
int mid=(l+r)>>1;
while(l<=r){
cout<<"l="<<l<<", r="<<r<<", mid="<<mid<<endl;
if(arr[mid]<=k)
l=mid+1;
else
r=mid-1;
mid=(l+r)>>1;
}
if(arr[mid]<=k)
return mid;
else
return 0;
}
int main(){
cout<<bin_search(arr1,0,6,5)<<endl;
cout<<bin_search(arr2,0,5,5)<<endl;
system("pause");
return 0;
}
另外,思考一个问题:如果二分查找是数组中允许重复元素,这种方法还适用吗?
4. 二分查找“有序二维数组”
在一个二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。
请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。
例如下面的二维数组就是每行、每列都递增排序。如果在这个数组中查找数字7,则返回true;
如果查找数字5,由于数组不含有该数字,则返回false。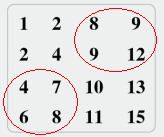
我的解题思路是这样的矩阵行列都是从小到大排好序的,要查找的话自然用二分效率比较高,而且这样的矩阵有个性质,最左上角的元素必定是最小值,最右下角的是最大值 ,在一个n*n的矩阵中,对角线的元素也是排好序的 ,找到对角线上的一个元素,使得这个元素小于待查找的key,并且下一元素大于待查找的key,那么只要在这个元素的左下角矩阵和右上角矩阵递归继续对角线查找就可以了,例如上图例子里查找7,只要找到对角线的元素4,然后递归查找红圈的矩阵就可以了 ,左上角矩阵最大值4<7,右下角矩阵最小值10>7,无需查找了。
但是此题并没有告诉我们原始矩阵是n*n的,这是比较麻烦的地方,不过思路是一样的,无非不能用对角线查找这样简单的办法了,假设m*n的矩阵,对角线查找的办法改进为i = (m1+m2)/2,j = (n1+n2)/2 进行查找就可以了,(m1,n1)为矩阵最左上角元素下标,(m2,n2)为最右下角元素下标
总结一下基本思路:
(1)对于n*n的有序二维数组 : 函数bin_search()在对角线上运用“二分”过程,找到i使得a[i][i]<k<a[i+1][i+1],然后对于“a[i][i]的左下角矩阵”和“a[i][i]的右上角矩阵”分别递归调用bin_search()查找即可。
(2)对于m*n的有序二维数组 : 基本同上,只是bin_search()不是对对角线“二分”,而是对矩阵m*n进行“二分缩放”(Sam: 这个词是我发明的:)示意图如下)

贴一下(2)的代码:
int bin_search(int value, int *a, int n, int m1, int n1, int m2, int n2)
{
int begin_m1 = m1, begin_n1 = n1, end_m2 = m2, end_n2 = n2;
int left_result = 0, right_result = 0;
int i = (m1+m2)/2, j = (n1+n2)/2;
if (a == NULL)
return 0;
if (value < *(a+m1*n+n1) || value > *(a+m2*n+n2))
return 0;
else if (value == *(a+m1*n+n1) || value == *(a+m2*n+n2))
return 1;
while ((i!=m1 || j!=n1) && (i!=m2 || j!=n2)){
if ( value == *(a+i*n+j) )
return 1;
else if ( value < *(a+i*n+j) ){
m2 = i;
n2 = j;
i = (i+m1)/2;
j = (j+n1)/2;
}
else{
m1 = i;
n1 = j;
i = (i+m2)/2;
j = (j+n2)/2;
}
}
//search left & right
if ( i<end_m2 )
left_result = bin_search(value, a, n, i+1, begin_n1, end_m2, j);
if ( j<end_n2 )
right_result = bin_search(value, a, n, begin_m1, j+1, i, end_n2);
if (left_result | right_result )
return 1;
else
return 0;
}
顺便提一句,我先前还看到一个笨娃娃说:可以变量所有的a[][]的行,对每一列进行二分查找,这样的复杂度是O(nlog(n)),呜呼!当然不错啦,但一看就学艺不精。