solr研究
这些天学习solr,整理了下相关资料,发出来给看看。感谢@信息检索团队的@陈毅,以及好朋友@许琦同学的耐心解答。
在此推荐solr学习论坛http://www.solr.cc/
1. Solr简介
历史:
Ø 2004年CNET开发Solar,为CNET提供站内搜索服务
Ø 2006年1月捐献给Apache ,成为Apache的孵化项目
Ø 一年后Solr孵化成熟,发布了1.2版,并成为Lucene的子项目
Ø 2010年 6月 solr发布了最新的1.4.1版,这是1.4的bugfix版本
Ø 如今Solr已经广为人知,并且许多公司都已经使用Solr去构建自己的搜索引擎:
Ø AOL、 Disney、Apple, Inc、阿里巴巴、安居客……
概况:
Ø Searchon lucene w/Replication
Ø 一个基于Lucene的全文搜索服务器
Ø 提供了基于Http的Rest-like操作接口
Ø 高可扩展的开放架构
Ø 提供了强大的WEB管理界面
Ø 有多种客户端:Ruby、PHP 、Java 、Python 、.NET 、Perl 、JavaScript
Ø 索引复制
Ø 更方便的使用停用词、同义词等
Ø 易于集成、几乎不用写代码就能适应一般的需求
一句话概况:Solr是Lucene面向企业搜索应用的扩展!
2. Solr功能介绍
l
l
Ø 提供了丰富的查询缓存
Ø 很容易的为本地以及远程的数据创建索引,DataImportHandler
Ø 对Rich Document(word、pdf、ppt……)进行解析和创建索引
Ø 快速增量更新索引,并复制到其他机器上
Ø 层面搜索
Ø More like this、Spelling suggestions、Auto-suggest……
Ø 高度的可扩展性
Ø NearRealtimeSearch
3. Solr实现原理
Ø Lucene回顾
Ø 用Java编写的全文信息检索工具包,提供了基本的API
Ø 使用倒排索引技术,极大提高了检索效率
Ø 让最相关的头100条结果满足98%以上用户的需求
Ø Org.apache.lucene.document、analysis、index、search
Ø 应用jive、eclipse、linkedin(bobo、zoie)、twritter(NRT)
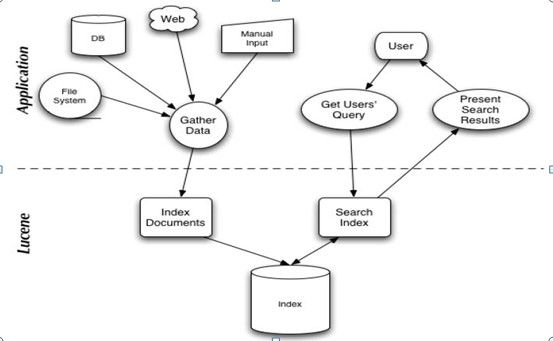
l Lucene索引结构
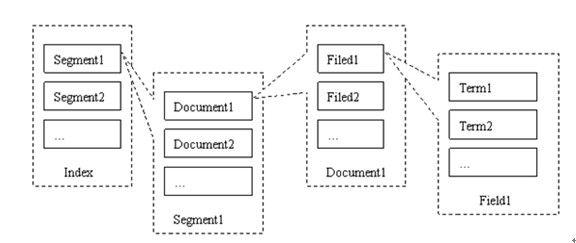
l Segment
l Document
l Filed
l Term
l Lucene搜索原理
l 分词、中文分词
Ø 机械分词:一元、二元、基于词库的分词
l 未登录词识别:机构名、人名、神马
l 歧义词
Ø 基于统计:HMM
l 样本
l 索引
Ø 国家:{1,3,6,8,}
Ø 上海:{3,7,16,17}
Ø 法规:{1,6}
Ø 人民:{3,9,16,20}
l 搜索
Ø 搜索:上海人民
Ø 解析为: ’上海’ and ‘人民’ ,表示搜索同时出现’上海 ‘和’人民’的文档
可以搜索出第3 和第16篇文档
Ø Solr架构
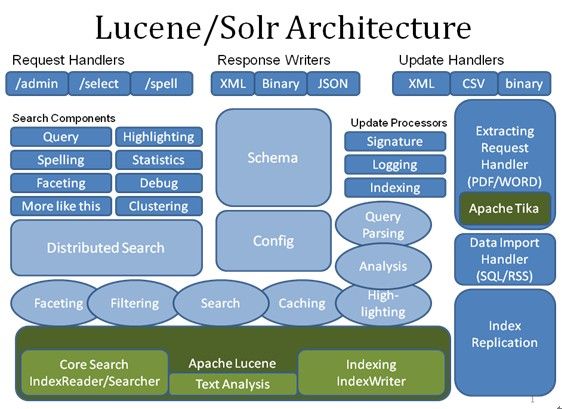
总体架构
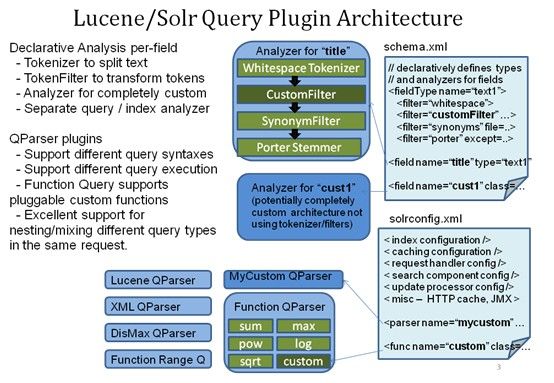
查询
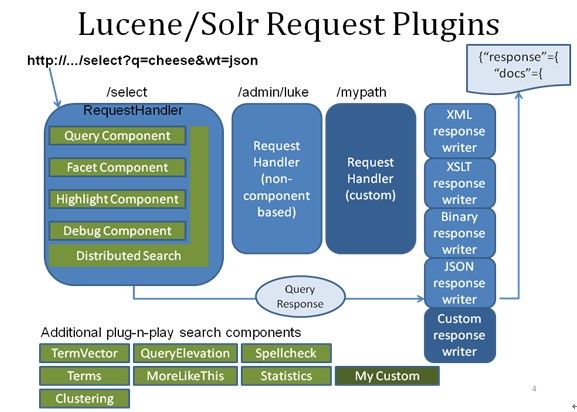
查询扩展
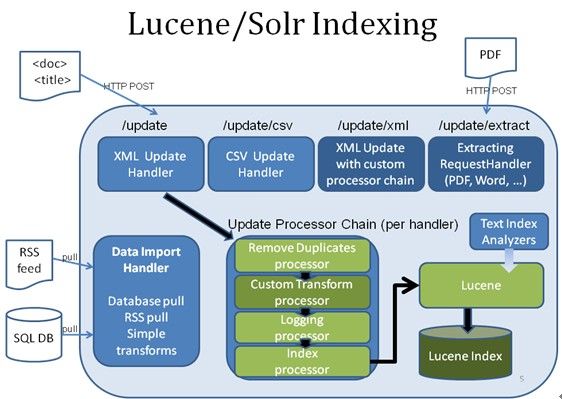
建索引
4. Solr分布式
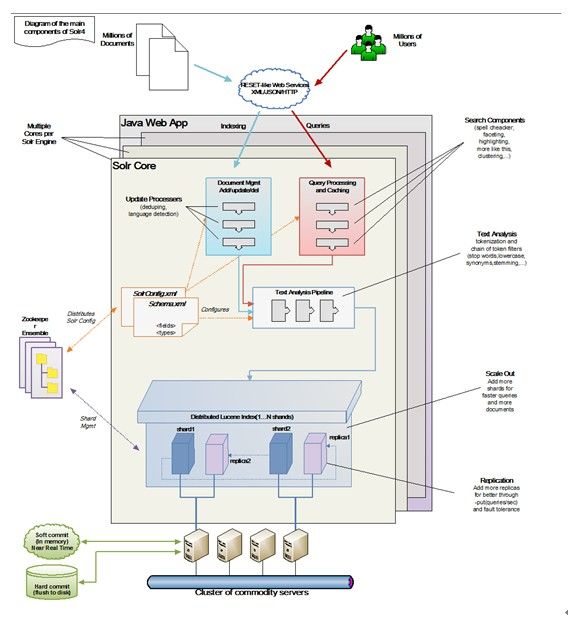
1、 索引分片(水平扩展)
2、 对分片做副本(并发、容错)
3、 Zookeeper总体调度
4、 查询引擎对结果做merge
5. Solr性能指标
负载量:待测试
查询速度:待测试
并发量:待测试
6. Solr结合微博应用构建方案
1、 主体组件:搭建solr集群(多solr实例+replication)。
2、 数据接入:使用onlinestream接入firehose数据,发送数据给solr,对数据做sharding分发
3、 索引构建:Solr设置定时更新索引
4、 功能扩展:扩展solr的排序功能,开发二次过滤功能。
4、client端查询:客户端通过solrj(java客户端)或者http请求进行查询
7. Solr待解决疑问
7.1索引更新
Solr搜索中第一次对数据建索引为索引新建,后续过程是索引更新过程。随着索引量增大是不是会出现更新越来越慢的情况。而且对于新增词库存在需要对原有索引进行重建过程.
增量索引/索引更新问题目前较好的解决方案是google的Caffeine
在Google采用Caffeine之前,Google使用MapReduce和分布式文件系统(如GFS)来构建搜索索引(从已知的Web页面索引中)。在2010年,Google搜索引擎发生了重大变革。Google将其搜索迁移到新的软件平台,他们称之为“Caffeine”。Caffeine是Google出自自身的设计,Caffeine使Google能够更迅速的添加新的链接(包括新闻报道以及博客文章等)到自身大规模的网站索引系统中,相比于以往的系统,新系统可提供“50%新生”的搜索结果。
在本质上Caffeine丢弃MapReduce转而将索引放置在由Google开发的分布式数据库BigTable上。
7.2分片问题
按时间分片/按id的hash分片?