皮尔逊相关系数
在具体阐述皮尔逊相关系数之前,有必要解释下什么是相关系数 ( Correlation coefficient )与相关距离(Correlation distance)。
相关系数 ( Correlation coefficient )的定义是:

其中,E为数学期望或均值,D为方差,D开根号为标准差,E{ [X-E(X)] [Y-E(Y)]}称为随机变量X与Y的协方差,记为Cov(X,Y),即Cov(X,Y) = E{ [X-E(X)] [Y-E(Y)]},而两个变量之间的协方差和标准差的商则称为随机变量X与Y的相关系数,记为![]()
相关系数衡量随机变量X与Y相关程度的一种方法,相关系数的取值范围是[-1,1]。相关系数的绝对值越大,则表明X与Y相关度越高。当X与Y线性相关时,相关系数取值为1(正线性相关)或-1(负线性相关)。
具体的,如果有两个变量:X、Y,最终计算出的相关系数的含义可以有如下理解:
当相关系数为0时,X和Y两变量无关系。
当X的值增大(减小),Y值增大(减小),两个变量为正相关,相关系数在0.00与1.00之间。
当X的值增大(减小),Y值减小(增大),两个变量为负相关,相关系数在-1.00与0.00之间。
相关距离的定义是:
![]()
OK,接下来,咱们来重点了解下皮尔逊相关系数。
在统计学中,皮尔逊积矩相关系数(英语:Pearson product-moment correlation coefficient,又称作 PPMCC或PCCs, 用r表示)用于度量两个变量X和Y之间的相关(线性相关),其值介于-1与1之间。
通常情况下通过以下相关系数取值范围判断变量的相关强度:
0.8-1.0 极强相关
0.6-0.8 强相关
0.4-0.6 中等程度相关
0.2-0.4 弱相关
0.0-0.2 极弱相关或无相关
这个相关系数也称作“皮尔森相关系数r”。
(1)皮尔逊系数的定义:
两个变量之间的皮尔逊相关系数定义为两个变量之间的协方差和标准差的商:
![]()
以上方程定义了总体相关系数, 一般表示成希腊字母ρ(rho)。基于样本对协方差和方差进行估计,可以得到样本标准差, 一般表示成r:
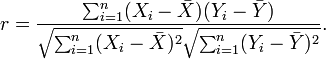
一种等价表达式的是表示成标准分的均值。基于(Xi, Yi)的样本点,样本皮尔逊系数是
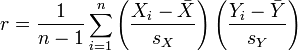
其中![]() 、
、![]() 及
及 ![]() ,分别是标准分、样本平均值和样本标准差。
,分别是标准分、样本平均值和样本标准差。
或许上面的讲解令你头脑混乱不堪,没关系,我换一种方式讲解,如下:
假设有两个变量X、Y,那么两变量间的皮尔逊相关系数可通过以下公式计算:
公式一:
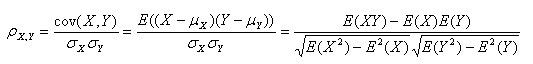
注:勿忘了上面说过,“皮尔逊相关系数定义为两个变量之间的协方差和标准差的商”,其中标准差的计算公式为:
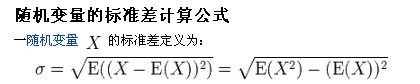
公式二:
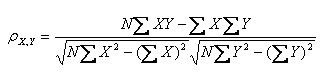
公式三: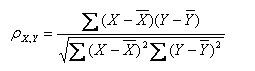
公式四: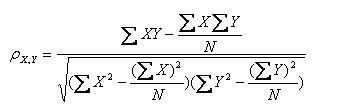
以上列出的四个公式等价,其中E是数学期望,cov表示协方差,N表示变量取值的个数。
(2)皮尔逊相关系数的适用范围
当两个变量的标准差都不为零时,相关系数才有定义,皮尔逊相关系数适用于:
两个变量之间是线性关系,都是连续数据。
两个变量的总体是正态分布,或接近正态的单峰分布。
两个变量的观测值是成对的,每对观测值之间相互独立。
(3)如何理解皮尔逊相关系数
rubyist:皮尔逊相关系数理解有两个角度
其一, 按照高中数学水平来理解, 它很简单, 可以看做将两组数据首先做Z分数处理之后, 然后两组数据的乘积和除以样本数,Z分数一般代表正态分布中, 数据偏离中心点的距离.等于变量减掉平均数再除以标准差.(就是高考的标准分类似的处理)
样本标准差则等于变量减掉平均数的平方和,再除以样本数,最后再开方,也就是说,方差开方即为标准差,样本标准差计算公式为:
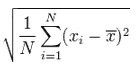
所以, 根据这个最朴素的理解,我们可以将公式依次精简为:
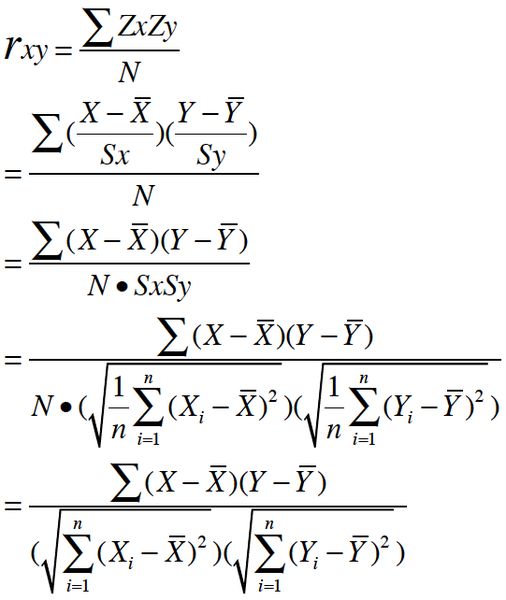
其二, 按照大学的线性数学水平来理解, 它比较复杂一点,可以看做是两组数据的向量夹角的余弦。下面是关于此皮尔逊系数的几何学的解释,先来看一幅图,如下所示:

回归直线: y=gx(x) [红色] 和 x=gy(y) [蓝色]
如上图,对于没有中心化的数据, 相关系数与两条可能的回归线y=gx(x) 和 x=gy(y) 夹角的余弦值一致。
对于没有中心化的数据 (也就是说, 数据移动一个样本平均值以使其均值为0), 相关系数也可以被视作由两个随机变量 向量 夹角 的 余弦值(见下方)。
举个例子,例如,有5个国家的国民生产总值分别为 10, 20, 30, 50 和 80 亿美元。 假设这5个国家 (顺序相同) 的贫困百分比分别为 11%, 12%, 13%, 15%, and 18% 。 令 x 和 y 分别为包含上述5个数据的向量: x = (1, 2, 3, 5, 8) 和 y = (0.11, 0.12, 0.13, 0.15, 0.18)。
利用通常的方法计算两个向量之间的夹角 (参见 数量积), 未中心化 的相关系数是:
![]()
我们发现以上的数据特意选定为完全相关: y = 0.10 + 0.01 x。 于是,皮尔逊相关系数应该等于1。将数据中心化 (通过E(x) = 3.8移动 x 和通过 E(y) = 0.138 移动 y ) 得到 x = (−2.8, −1.8, −0.8, 1.2, 4.2) 和 y = (−0.028, −0.018, −0.008, 0.012, 0.042), 从中
![]()
(4)皮尔逊相关的约束条件
从以上解释, 也可以理解皮尔逊相关的约束条件:
1 两个变量间有线性关系
2 变量是连续变量
3 变量均符合正态分布,且二元分布也符合正态分布
4 两变量独立
在实践统计中,一般只输出两个系数,一个是相关系数,也就是计算出来的相关系数大小,在-1到1之间;另一个是独立样本检验系数,用来检验样本一致性。
简单说来,各种“距离”的应用场景简单概括为,空间:欧氏距离,路径:曼哈顿距离,国际象棋国王:切比雪夫距离,以上三种的统一形式:闵可夫斯基距离,加权:标准化欧氏距离,排除量纲和依存:马氏距离,向量差距:夹角余弦,编码差别:汉明距离,集合近似度:杰卡德类似系数与距离,相关:相关系数与相关距离。