HardFault_Handler问题查找方法
本文来自: http://blog.csdn.net/ouyang_linux007/article/details/7431444
STM32出现HardFault_Handler故障的原因主要有两个方面:
1、内存溢出或者访问越界。这个需要自己写程序的时候规范代码,遇到了需要慢慢排查。
2、堆栈溢出。增加堆栈的大小。
出现问题时排查的方法:
发生异常之后可首先查看LR寄存器中的值,确定当前使用堆栈为MSP或PSP,然后找到相应堆栈的指针,并在内存中查看相应堆栈里的内容。由于异常发生时,内核将R0~R3、R12、Return address、PSR、LR寄存器依次入栈,其中Return address即为发生异常前PC将要执行的下一条指令地址。
注意:寄存器均是32位,且STM32是小端模式。(参考Cortex-M3权威)

编写问题代码如下:
void StackFlow(void)
{
int a[3],i;
for(i=0; i<10000; i++)
{
a[i]=1;
}
}
void SystemInit(void)
{
/* Reset the RCC clock configuration to the default reset state ------------*/
/* Set HSION bit */
RCC->CR |= (uint32_t)0x00000001;
/* Reset CFGR register */
RCC->CFGR = 0x00000000;
/* Reset HSEON, CSSON and PLLON bits */
RCC->CR &= (uint32_t)0xFEF6FFFF;
/* Reset PLLCFGR register */
RCC->PLLCFGR = 0x24003010;
StackFlow();
/* Reset HSEBYP bit */
RCC->CR &= (uint32_t)0xFFFBFFFF;
。。。。。。。。。。。。。。
}
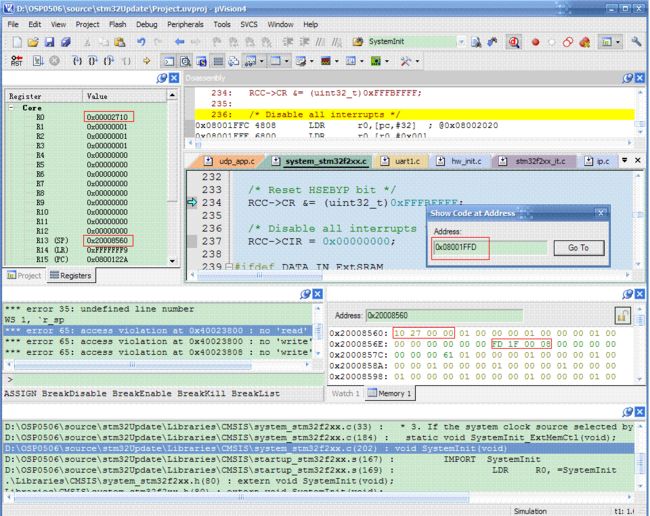
DEBUG如下图
SP值为0x20008560,查看堆栈里面的值依次为R0~R3、R12、Return address、PSR、LR, 例如R0(10 27 00 00), 显然堆栈后第21个字节到24字节即为Return address,该地址0x08001FFD即为异常前PC将要执行的下一条指令地址(即StackFlow()后面的语句处 RCC->CR &= (uint32_t)0xFFFBFFFF)
另一种方法:
默认的HardFault_Handler处理方法不是B .这样的死循环么?楼主将它改成BX LR直接返回的形式。然后在这条语句打个断点,一旦在断点中停下来,说明出错了,然后再返回,就可以返回到出错的位置的下一条语句那儿
__asm void wait()
{
BX lr
}
void HardFault_Handler(void)
{
/* Go to infinite loop when Hard Fault exception occurs */
wait();
}
本文作者特别注释:__asm void wait() 函数引用会出现报错:Unknown opcode lr, expecting opcode or Macro