第四章 分治策略
通过递归求解分治问题:
1.分解, 将问题分解为规模更小的相似的问题。
2.解决,递归的求解子问题,如果问题规模足够小,则直接求解。
3.合并,讲子问题的解合并为原问题的解。
求解递归式的方法:
1.代入法,猜测一个界,然后用数学归纳法证明他是正确的
2.递归树法,将递归式转换为一棵树,其节点表示 不同层次的递归调用产生的代价,然后采用边界和技术求解递归式
3.主方法,用于求解形如T(n) = aT(n/b)+f(n),其中a>=1, b>1, f(n)是一个给定的函数
4.1 最大子数组问题:
对于给定的一个组股票价格[100,113,110,85,105,102,86,63,81,101,94,106,101,79,94,90,97],采用T+1的方式交易,如何求得最大收益?
枚举出所有可能的结果,再从其中选择收益最大的一组,其复杂度为theta(n^2)
def FIND_MAXIMUN_PROFIT(A):
maxProfit = 0
for buy in range(0, len(A)):
for sell in range(buy+1, len(A)):
profit = A[sell] - A[buy]
if profit > maxProfit:
maxProfit = profit
low = buy
high = sell
return low, high, maxProfit
若我们从另外一个角度考虑问题,收益最大即是找到数组中的一段其净值变化最大,这样问题就转化为了最大子数组问题。最大子数组问题通常指寻找一个A的和最大的非空连续子数组,我们依然采用枚举法可以得到答案,但对效率的提升并没有帮助
def FORCE_FIND_MAXIMUN_SUBAARRAY(A):
maxsum = 0
for buy in range(0, len(A)):
subsum = 0
for sell in range(buy, len(A)):
subsum = subsum + A[sell]
if subsum > maxsum:
maxsum = subsum
low = buy
high = sell+1
return low, high, maxsum
def FIND_MAXIMUN_PROFIT_TRANS(A):
B = []
for i in range(1, len(A)):
dValue = A[i] - A[i - 1]
B.append(dValue)
low, high, maxsum = FORCE_FIND_MAXIMUN_SUBAARRAY(B)
return low, high, maxsum
我们将问题的输入转化之后,问题转化为最大子数组问题,将数组分为两半,最大子数组只会包含在以下情况中:1.最大子数组在左侧的数组;2.最大子数组在右侧的数组;3.跨左右数组。左右数组均为更小规模的原数组,跨左右数组则与原问题不同,则对其另外处理。
def FIND_MAXIMUN_CROSS_SUBAARRAY(A, low, mid, high):
left_sum = -float("inf")
subsum = 0
for i in range(mid-1, low-1, -1):
subsum = subsum + A[i]
if subsum > left_sum:
left_sum = subsum
max_left = i
right_sum = -float("inf")
subsum = 0
for i in range(mid, high):
subsum = subsum + A[i]
if subsum > right_sum:
right_sum = subsum
max_right = i+1
return max_left, max_right, left_sum+right_sum
def FIND_MAXIMUN_SUBAARRAY(A, low, high):
if high == low + 1:
return low, high, A[low]
else:
mid = (low + high) // 2
left_low, left_high, left_sum = FIND_MAXIMUN_SUBAARRAY(A, low, mid)
right_low, right_high, right_sum = FIND_MAXIMUN_SUBAARRAY(A, mid, high)
cross_low, cross_high, cross_sum = FIND_MAXIMUN_CROSS_SUBAARRAY(A, low, mid, high)
if left_sum >= right_sum and left_sum > cross_sum:
return left_low, left_high, left_sum
elif right_sum >= left_sum and right_sum > cross_sum:
return right_low, right_high, right_sum
else:
return cross_low, cross_high, cross_sum
def FIND_MAXIMUN_PROFIT_TRANS(A):
B = []
for i in range(1, len(A)):
dValue = A[i] - A[i - 1]
B.append(dValue)
low, high, maxsum = FIND_MAXIMUN_SUBAARRAY(B, 0, len(B))
return low, high, maxsum则可以将问题的效率提高到theta(nlogn)
4.2矩阵乘法的Strassen算法
对于计算n*n方阵的积我们有数学公式:
由此得出的算法为:
def SQUARE_MATRIX_MULTIPLY(A, B):
assert(len(A) == len(B))
n = len(A)
C = [[0 for col in range(n)] for row in range(n)]
for i in range(0, n):
for j in range(0, n):
for k in range(0, n):
C[i][j]= C[i][j] + A[i][k]*B[k][j]
return C三层循环每次循环n,其时间复杂度为theta(n^3)
由矩阵的性质有:
若使用分治策略则有:
1.分解, 将问题分解为4个规模更小的矩阵乘法问题。
2.解决,递归的求解子问题,直到n值为1,则直接求解。
3.合并,C11, C12, C21, C22合并为原问题的解。
其实现如下(与书中的算法不同,为了不引入下标计算的复杂度,此处运算皆会生成新的矩阵,在最后合并时合并为一个新的矩阵,并不影响算法复杂度):
def matrixGetSub(matrix, row1, row2, col1, col2):
data = []
rows = matrix[row1:row2]
for row in rows:
data.append(row[col1:col2])
return data
def matrixAdd(m1, m2):
assert(len(m1) == len(m2))
result = [[0 for col in range(len(m1))] for row in range(len(m1))]
for i in range(0, len(m1)):
for j in range(0, len(m1)):
result[i][j] = m1[i][j] + m2[i][j]
return result
def matrixMerge(A, A11, A12, A21, A22):
assert(len(A11) == len(A12))
assert(len(A) == len(A11) + len(A21))
n = len(A11)
for i in range(0, n):
for j in range(0, n):
A[i][j] = A11[i][j]
A[i + n][j] = A21[i][j]
A[i][ j + n] = A12[i][j]
A[i + n][j + n] = A22[i][j]
def SQUARE_MATRIX_MULTIPLY_RECURSIVE(A, B):
assert(len(A) == len(B))
n = len(A)
C = [[0 for col in range(n)] for row in range(n)]
if n == 1:
C[0][0] = A[0][0] * B[0][0]
else:
mid = len(A)//2
A11 = matrixGetSub(A, 0, mid, 0, mid)
A12 = matrixGetSub(A, 0, mid, mid, n)
A21 = matrixGetSub(A, mid, n, 0, mid)
A22 = matrixGetSub(A, mid, n, mid, n)
B11 = matrixGetSub(B, 0, mid, 0, mid)
B12 = matrixGetSub(B, 0, mid, mid, n)
B21 = matrixGetSub(B, mid, n, 0, mid)
B22 = matrixGetSub(B, mid, n, mid, n)
C11 = matrixAdd(SQUARE_MATRIX_MULTIPLY_RECURSIVE(A11, B11), SQUARE_MATRIX_MULTIPLY_RECURSIVE(A12, B21))
C12 = matrixAdd(SQUARE_MATRIX_MULTIPLY_RECURSIVE(A11, B12), SQUARE_MATRIX_MULTIPLY_RECURSIVE(A12, B22))
C21 = matrixAdd(SQUARE_MATRIX_MULTIPLY_RECURSIVE(A21, B11), SQUARE_MATRIX_MULTIPLY_RECURSIVE(A22, B21))
C22 = matrixAdd(SQUARE_MATRIX_MULTIPLY_RECURSIVE(A21, B12), SQUARE_MATRIX_MULTIPLY_RECURSIVE(A22, B22))
matrixMerge(C, C11, C12, C21, C22)
return C其复杂度由以下几个方面组成:1.分解,4theta(n^2);2.解决,递归的求解子问题,SQUARE_MATRIX_MULTIPLY_RECURSIVE被执行了8次,n的规模缩小为n/2则其复杂度为,8T(n/2);3.合并,matrixMerge的复杂度为theta(n^2)。总的复杂度为T(n) = 8T(n/2) + theta(n^2) = theta(n^3),其值由8T(n/2)贡献,故只需要降低其系数则可以减低其复杂度
STRASSEN算法利用以下数学性质:

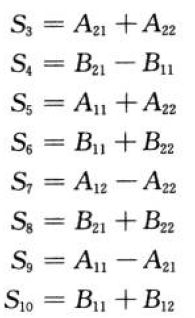
![]()
![]()
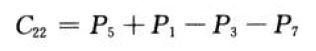
将n阶的乘法分解为7次递归的乘法求解减低了T(n/2)前的系数,提高了算法效率。
其实现如下(与书中的算法不同,为了不引入下标计算的复杂度,此处运算皆会生成新的矩阵,在最后合并时合并为一个新的矩阵,并不影响算法复杂度):
def matrixGetSub(matrix, row1, row2, col1, col2):
data = []
rows = matrix[row1:row2]
for row in rows:
data.append(row[col1:col2])
return data
def matrixAdd(m1, m2):
assert(len(m1) == len(m2))
result = [[0 for col in range(len(m1))] for row in range(len(m1))]
for i in range(0, len(m1)):
for j in range(0, len(m1)):
result[i][j] = m1[i][j] + m2[i][j]
return result
def matrixSub(m1, m2):
assert(len(m1) == len(m2))
result = [[0 for col in range(len(m1))] for row in range(len(m1))]
for i in range(0, len(m1)):
for j in range(0, len(m1)):
result[i][j] = m1[i][j] - m2[i][j]
return result
def matrixMerge(A, A11, A12, A21, A22):
assert(len(A11) == len(A12))
assert(len(A) == len(A11) + len(A21))
n = len(A11)
for i in range(0, n):
for j in range(0, n):
A[i][j] = A11[i][j]
A[i + n][j] = A21[i][j]
A[i][ j + n] = A12[i][j]
A[i + n][j + n] = A22[i][j]
def STRASSEN_METHOD(A, B):
assert(len(A) == len(B))
n = len(A)
C = [[0 for col in range(n)] for row in range(n)]
if n == 1:
C[0][0] = A[0][0] * B[0][0]
else:
mid = len(A)//2
A11 = matrixGetSub(A, 0, mid, 0, mid)
A12 = matrixGetSub(A, 0, mid, mid, n)
A21 = matrixGetSub(A, mid, n, 0, mid)
A22 = matrixGetSub(A, mid, n, mid, n)
B11 = matrixGetSub(B, 0, mid, 0, mid)
B12 = matrixGetSub(B, 0, mid, mid, n)
B21 = matrixGetSub(B, mid, n, 0, mid)
B22 = matrixGetSub(B, mid, n, mid, n)
S1 = matrixSub(B12, B22)
S2 = matrixAdd(A11, A12)
S3 = matrixAdd(A21, A22)
S4 = matrixSub(B21, B11)
S5 = matrixAdd(A11, A22)
S6 = matrixAdd(B11, B22)
S7 = matrixSub(A12, A22)
S8 = matrixAdd(B21, B22)
S9 = matrixSub(A11, A21)
S10 = matrixAdd(B11, B12)
P1 = STRASSEN_METHOD(A11, S1)
P2 = STRASSEN_METHOD(S2, B22)
P3 = STRASSEN_METHOD(S3, B11)
P4 = STRASSEN_METHOD(A22, S4)
P5 = STRASSEN_METHOD(S5, S6)
P6 = STRASSEN_METHOD(S7, S8)
P7 = STRASSEN_METHOD(S9, S10)
C11 = matrixAdd(matrixSub(matrixAdd(P5, P4), P2), P6)
C12 = matrixAdd(P1, P2)
C21 = matrixAdd(P3, P4)
C22 = matrixSub(matrixSub(matrixAdd(P5, P1), P3), P7)
matrixMerge(C, C11, C12, C21, C22)
return C
由于递归次数的改变效率提高到T(n) = theta(n^lg7)
4.3用代入法求解递归式
去猜测一个解,然后代入去证明他正确与否,对于无法直接证明的一般采用加减一个常数项或者低阶项来求得一个更加紧确的界,对于指数计算的通常采用变量代换的方法计算。
4.4用递归树方法求解递归式
由T中n的系数X^-1确定问题规模减小可知有以X为低的对数函数lgX(n)求出层数, 由T的系数Y确定每增加一层节点数以Y为基的指数增长,尾数函数确定了第i层每个节点贡献f((1/X)^i )的执行时间,叶子节点有Y^(lgX(n))个数,对所有节点和叶子取和并利用级数公式化简T(n) ,使用代入法证明。对于有多个分解的取上界则只需计算其中的分解,下界只需计算较小的分解,这也导致递归树方法的不精确。
4.5用主方法求解递归式
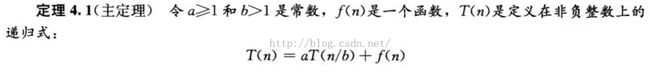

4.6 证明主定理
用递归树方法证明主定理
第四章习题解答