CUDA编程(六)进一步并行
CUDA编程(六)
进一步并行
在之前我们使用Thread完成了简单的并行加速,虽然我们的程序运行速度有了50甚至上百倍的提升,但是根据内存带宽来评估的话我们的程序还远远不够,在上一篇博客中给大家介绍了一个访存方面非常重要的优化,我们通过使用连续的内存存取模式,取得了令人满意的优化效果,最终内存带宽也达到了GB/s的级别。
之前也已经提到过了,CUDA不仅提供了Thread,还提供了Grid和Block以及Share Memory这些非常重要的机制,我的显卡的Thread极限是1024,但是通过block和Grid,线程的数量还能成倍增长,甚至用几万个线程。所以本篇博客我们将再次回到线程和并行的角度,进一步的并行加速我们的程序。
Thread AND Block AND Grid
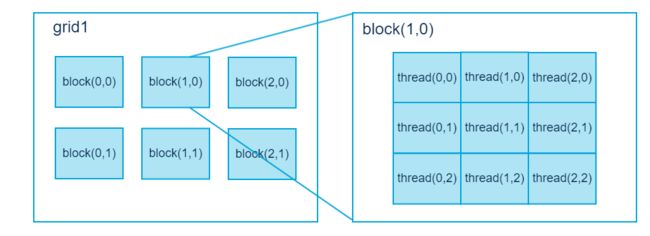
第一篇博客的时候就给大家说明过thread-block-grid 结构了,这里我们再复习一下。
在 CUDA 架构下,显示芯片执行时的最小单位是thread。数个 thread 可以组成一个block。一个 block 中的 thread 能存取同一块共享的内存,而且可以快速进行同步的动作。
每一个 block 所能包含的 thread 数目是有限的。不过,执行相同程序的 block,可以组成grid。不同 block 中的 thread 无法存取同一个共享的内存,因此无法直接互通或进行同步。因此,不同 block 中的 thread 能合作的程度是比较低的。不过,利用这个模式,可以让程序不用担心显示芯片实际上能同时执行的 thread 数目限制。例如,一个具有很少量执行单元的显示芯片,可能会把各个 block 中的 thread 顺序执行,而非同时执行。不同的 grid 则可以执行不同的程序(即 kernel)。
每个 thread 都有自己的一份 register 和 local memory 的空间。同一个 block 中的每个thread 则有共享的一份 share memory。此外,所有的 thread(包括不同 block 的 thread)都共享一份 global memory、constant memory、和 texture memory。不同的 grid 则有各自的 global memory、constant memory 和 texture memory。
大家可能注意到不同block之间是无法进行同步工作的,不过,在我们的程序中,其实不太需要进行 thread 的同步动作,因此我们可以使用多个 block 来进一步增加thread 的数目。
通过多个block使用更多的线程
下面我们就开始继续修改我们的程序:
先贴一下之前的完整代码:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
//CUDA RunTime API
#include <cuda_runtime.h>
//1M
#define DATA_SIZE 1048576
#define THREAD_NUM 1024
int data[DATA_SIZE];
//产生大量0-9之间的随机数
void GenerateNumbers(int *number, int size)
{
for (int i = 0; i < size; i++) {
number[i] = rand() % 10;
}
}
//打印设备信息
void printDeviceProp(const cudaDeviceProp &prop)
{
printf("Device Name : %s.\n", prop.name);
printf("totalGlobalMem : %d.\n", prop.totalGlobalMem);
printf("sharedMemPerBlock : %d.\n", prop.sharedMemPerBlock);
printf("regsPerBlock : %d.\n", prop.regsPerBlock);
printf("warpSize : %d.\n", prop.warpSize);
printf("memPitch : %d.\n", prop.memPitch);
printf("maxThreadsPerBlock : %d.\n", prop.maxThreadsPerBlock);
printf("maxThreadsDim[0 - 2] : %d %d %d.\n", prop.maxThreadsDim[0], prop.maxThreadsDim[1], prop.maxThreadsDim[2]);
printf("maxGridSize[0 - 2] : %d %d %d.\n", prop.maxGridSize[0], prop.maxGridSize[1], prop.maxGridSize[2]);
printf("totalConstMem : %d.\n", prop.totalConstMem);
printf("major.minor : %d.%d.\n", prop.major, prop.minor);
printf("clockRate : %d.\n", prop.clockRate);
printf("textureAlignment : %d.\n", prop.textureAlignment);
printf("deviceOverlap : %d.\n", prop.deviceOverlap);
printf("multiProcessorCount : %d.\n", prop.multiProcessorCount);
}
//CUDA 初始化
bool InitCUDA()
{
int count;
//取得支持Cuda的装置的数目
cudaGetDeviceCount(&count);
if (count == 0) {
fprintf(stderr, "There is no device.\n");
return false;
}
int i;
for (i = 0; i < count; i++) {
cudaDeviceProp prop;
cudaGetDeviceProperties(&prop, i);
//打印设备信息
printDeviceProp(prop);
if (cudaGetDeviceProperties(&prop, i) == cudaSuccess) {
if (prop.major >= 1) {
break;
}
}
}
if (i == count) {
fprintf(stderr, "There is no device supporting CUDA 1.x.\n");
return false;
}
cudaSetDevice(i);
return true;
}
// __global__ 函数 (GPU上执行) 计算立方和
__global__ static void sumOfSquares(int *num, int* result, clock_t* time)
{
//表示目前的 thread 是第几个 thread(由 0 开始计算)
const int tid = threadIdx.x;
int sum = 0;
int i;
//记录运算开始的时间
clock_t start;
//只在 thread 0(即 threadIdx.x = 0 的时候)进行记录
if (tid == 0) start = clock();
for (i = tid; i < DATA_SIZE; i += THREAD_NUM) {
sum += num[i] * num[i] * num[i];
}
result[tid] = sum;
//计算时间的动作,只在 thread 0(即 threadIdx.x = 0 的时候)进行
if (tid == 0) *time = clock() - start;
}
int main()
{
//CUDA 初始化
if (!InitCUDA()) {
return 0;
}
//生成随机数
GenerateNumbers(data, DATA_SIZE);
/*把数据复制到显卡内存中*/
int* gpudata, *result;
clock_t* time;
//cudaMalloc 取得一块显卡内存 ( 其中result用来存储计算结果,time用来存储运行时间 )
cudaMalloc((void**)&gpudata, sizeof(int)* DATA_SIZE);
cudaMalloc((void**)&result, sizeof(int)*THREAD_NUM);
cudaMalloc((void**)&time, sizeof(clock_t));
//cudaMemcpy 将产生的随机数复制到显卡内存中
//cudaMemcpyHostToDevice - 从内存复制到显卡内存
//cudaMemcpyDeviceToHost - 从显卡内存复制到内存
cudaMemcpy(gpudata, data, sizeof(int)* DATA_SIZE, cudaMemcpyHostToDevice);
// 在CUDA 中执行函数 语法:函数名称<<<block 数目, thread 数目, shared memory 大小>>>(参数...);
sumOfSquares << < 1, THREAD_NUM, 0 >> >(gpudata, result, time);
/*把结果从显示芯片复制回主内存*/
int sum[THREAD_NUM];
clock_t time_use;
//cudaMemcpy 将结果从显存中复制回内存
cudaMemcpy(&sum, result, sizeof(int)* THREAD_NUM, cudaMemcpyDeviceToHost);
cudaMemcpy(&time_use, time, sizeof(clock_t), cudaMemcpyDeviceToHost);
//Free
cudaFree(gpudata);
cudaFree(result);
cudaFree(time);
int final_sum = 0;
for (int i = 0; i < THREAD_NUM; i++) {
final_sum += sum[i];
}
printf("GPUsum: %d gputime: %d\n", final_sum, time_use);
final_sum = 0;
for (int i = 0; i < DATA_SIZE; i++) {
final_sum += data[i] * data[i] * data[i];
}
printf("CPUsum: %d \n", final_sum);
return 0;
}我们要去加入多个block来继续增加我们的线程数量:
首先define一个block的数目
#define THREAD_NUM 256
#define BLOCK_NUM 32
我们准备建立 32 个 blocks,每个 blocks 有 256个 threads,也就是说总共有 32*256= 8192个threads,这里有一个问题,我们为什么不用极限的1024个线程呢?那样就是32*1024 = 32768 个线程,难道不是更好吗?其实并不是这样的,从线程运行的原理来看,线程数量达到一定大小后,我们再一味的增加线程也不会取得性能提升了,反而有可能会让性能下降,感兴趣的同学可以改一下数量试一下。另外我们的加和部分是在CPU上进行的,越多的线程意味着越多的结果,而这也意味着CPU上的运算压力会越来越大。
接着,我们需要修改kernel 部份,加入bid = blockIdx.x:
// __global__ 函数 (GPU上执行) 计算立方和
__global__ static void sumOfSquares(int *num, int* result, clock_t* time)
{
//表示目前的 thread 是第几个 thread(由 0 开始计算)
const int tid = threadIdx.x;
//表示目前的 thread 属于第几个 block(由 0 开始计算)
const int bid = blockIdx.x;
int sum = 0;
int i;
//记录运算开始的时间
clock_t start;
//只在 thread 0(即 threadIdx.x = 0 的时候)进行记录,每个 block 都会记录开始时间及结束时间
if (tid == 0) time[bid]= clock();
//thread需要同时通过tid和bid来确定,同时不要忘记保证内存连续性
for (i = bid * THREAD_NUM + tid; i < DATA_SIZE; i += BLOCK_NUM * THREAD_NUM) {
sum += num[i] * num[i] * num[i];
}
//Result的数量随之增加
result[bid * THREAD_NUM + tid] = sum;
//计算时间的动作,只在 thread 0(即 threadIdx.x = 0 的时候)进行,每个 block 都会记录开始时间及结束时间
if (tid == 0) time[bid + BLOCK_NUM] = clock();
}
关于修改注释已经写得很清楚了。
blockIdx.x 和 threadIdx.x 一样是 CUDA 内建的变量,它表示的是目前的 block 编号。
另外我们把计算时间的方式改成每个 block 都会记录开始时间及结束时间。
因此我们result和time变量的长度需要进行更改:
//cudaMalloc 取得一块显卡内存 ( 其中result用来存储计算结果,time用来存储运行时间 )
cudaMalloc((void**) &result, sizeof(int) * THREAD_NUM * BLOCK_NUM);
cudaMalloc((void**) &time, sizeof(clock_t) * BLOCK_NUM * 2);
然后在调用核函数的时候,把控制block数量的的参数改成我们的block数:
sumOfSquares << < BLOCK_NUM, THREAD_NUM, 0 >> >(gpudata, result, time);
注意从显存复制回内存的部分也需要修改(由于result和time长度的改变):
/*把结果从显示芯片复制回主内存*/
int sum[THREAD_NUM*BLOCK_NUM];
clock_t time_use[BLOCK_NUM * 2];
//cudaMemcpy 将结果从显存中复制回内存
cudaMemcpy(&sum, result, sizeof(int)* THREAD_NUM*BLOCK_NUM, cudaMemcpyDeviceToHost);
cudaMemcpy(&time_use, time, sizeof(clock_t)* BLOCK_NUM * 2, cudaMemcpyDeviceToHost);
//Free
cudaFree(gpudata);
cudaFree(result);
cudaFree(time);
int final_sum = 0;
for (int i = 0; i < THREAD_NUM*BLOCK_NUM; i++) {
final_sum += sum[i];
}
此外,由于涉及到block,我们需要采取不同的计时方式,即把每个 block 最早的开始时间,和最晚的结束时间相减,取得总运行时间。
//采取新的计时策略 把每个 block 最早的开始时间,和最晚的结束时间相减,取得总运行时间
clock_t min_start, max_end;
min_start = time_use[0];
max_end = time_use[BLOCK_NUM];
for (int i = 1; i < BLOCK_NUM; i++) {
if (min_start > time_use[i])
min_start = time_use[i];
if (max_end < time_use[i + BLOCK_NUM])
max_end = time_use[i + BLOCK_NUM];
}
printf("GPUsum: %d gputime: %d\n", final_sum, max_end - min_start);完整程序:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
//CUDA RunTime API
#include <cuda_runtime.h>
//1M
#define DATA_SIZE 1048576
#define THREAD_NUM 256
#define BLOCK_NUM 32
int data[DATA_SIZE];
//产生大量0-9之间的随机数
void GenerateNumbers(int *number, int size)
{
for (int i = 0; i < size; i++) {
number[i] = rand() % 10;
}
}
//打印设备信息
void printDeviceProp(const cudaDeviceProp &prop)
{
printf("Device Name : %s.\n", prop.name);
printf("totalGlobalMem : %d.\n", prop.totalGlobalMem);
printf("sharedMemPerBlock : %d.\n", prop.sharedMemPerBlock);
printf("regsPerBlock : %d.\n", prop.regsPerBlock);
printf("warpSize : %d.\n", prop.warpSize);
printf("memPitch : %d.\n", prop.memPitch);
printf("maxThreadsPerBlock : %d.\n", prop.maxThreadsPerBlock);
printf("maxThreadsDim[0 - 2] : %d %d %d.\n", prop.maxThreadsDim[0], prop.maxThreadsDim[1], prop.maxThreadsDim[2]);
printf("maxGridSize[0 - 2] : %d %d %d.\n", prop.maxGridSize[0], prop.maxGridSize[1], prop.maxGridSize[2]);
printf("totalConstMem : %d.\n", prop.totalConstMem);
printf("major.minor : %d.%d.\n", prop.major, prop.minor);
printf("clockRate : %d.\n", prop.clockRate);
printf("textureAlignment : %d.\n", prop.textureAlignment);
printf("deviceOverlap : %d.\n", prop.deviceOverlap);
printf("multiProcessorCount : %d.\n", prop.multiProcessorCount);
}
//CUDA 初始化
bool InitCUDA()
{
int count;
//取得支持Cuda的装置的数目
cudaGetDeviceCount(&count);
if (count == 0) {
fprintf(stderr, "There is no device.\n");
return false;
}
int i;
for (i = 0; i < count; i++) {
cudaDeviceProp prop;
cudaGetDeviceProperties(&prop, i);
//打印设备信息
printDeviceProp(prop);
if (cudaGetDeviceProperties(&prop, i) == cudaSuccess) {
if (prop.major >= 1) {
break;
}
}
}
if (i == count) {
fprintf(stderr, "There is no device supporting CUDA 1.x.\n");
return false;
}
cudaSetDevice(i);
return true;
}
// __global__ 函数 (GPU上执行) 计算立方和
// __global__ 函数 (GPU上执行) 计算立方和
__global__ static void sumOfSquares(int *num, int* result, clock_t* time)
{
//表示目前的 thread 是第几个 thread(由 0 开始计算)
const int tid = threadIdx.x;
//表示目前的 thread 属于第几个 block(由 0 开始计算)
const int bid = blockIdx.x;
int sum = 0;
int i;
//记录运算开始的时间
clock_t start;
//只在 thread 0(即 threadIdx.x = 0 的时候)进行记录,每个 block 都会记录开始时间及结束时间
if (tid == 0) time[bid] = clock();
//thread需要同时通过tid和bid来确定,同时不要忘记保证内存连续性
for (i = bid * THREAD_NUM + tid; i < DATA_SIZE; i += BLOCK_NUM * THREAD_NUM) {
sum += num[i] * num[i] * num[i];
}
//Result的数量随之增加
result[bid * THREAD_NUM + tid] = sum;
//计算时间的动作,只在 thread 0(即 threadIdx.x = 0 的时候)进行,每个 block 都会记录开始时间及结束时间
if (tid == 0) time[bid + BLOCK_NUM] = clock();
}
int main()
{
//CUDA 初始化
if (!InitCUDA()) {
return 0;
}
//生成随机数
GenerateNumbers(data, DATA_SIZE);
/*把数据复制到显卡内存中*/
int* gpudata, *result;
clock_t* time;
//cudaMalloc 取得一块显卡内存 ( 其中result用来存储计算结果,time用来存储运行时间 )
cudaMalloc((void**)&gpudata, sizeof(int)* DATA_SIZE);
cudaMalloc((void**)&result, sizeof(int)*THREAD_NUM* BLOCK_NUM);
cudaMalloc((void**)&time, sizeof(clock_t)* BLOCK_NUM * 2);
//cudaMemcpy 将产生的随机数复制到显卡内存中
//cudaMemcpyHostToDevice - 从内存复制到显卡内存
//cudaMemcpyDeviceToHost - 从显卡内存复制到内存
cudaMemcpy(gpudata, data, sizeof(int)* DATA_SIZE, cudaMemcpyHostToDevice);
// 在CUDA 中执行函数 语法:函数名称<<<block 数目, thread 数目, shared memory 大小>>>(参数...);
sumOfSquares << < BLOCK_NUM, THREAD_NUM, 0 >> >(gpudata, result, time);
/*把结果从显示芯片复制回主内存*/
int sum[THREAD_NUM*BLOCK_NUM];
clock_t time_use[BLOCK_NUM * 2];
//cudaMemcpy 将结果从显存中复制回内存
cudaMemcpy(&sum, result, sizeof(int)* THREAD_NUM*BLOCK_NUM, cudaMemcpyDeviceToHost);
cudaMemcpy(&time_use, time, sizeof(clock_t)* BLOCK_NUM * 2, cudaMemcpyDeviceToHost);
//Free
cudaFree(gpudata);
cudaFree(result);
cudaFree(time);
int final_sum = 0;
for (int i = 0; i < THREAD_NUM*BLOCK_NUM; i++) {
final_sum += sum[i];
}
//采取新的计时策略 把每个 block 最早的开始时间,和最晚的结束时间相减,取得总运行时间
clock_t min_start, max_end;
min_start = time_use[0];
max_end = time_use[BLOCK_NUM];
for (int i = 1; i < BLOCK_NUM; i++) {
if (min_start > time_use[i])
min_start = time_use[i];
if (max_end < time_use[i + BLOCK_NUM])
max_end = time_use[i + BLOCK_NUM];
}
printf("GPUsum: %d gputime: %d\n", final_sum, max_end - min_start);
final_sum = 0;
for (int i = 0; i < DATA_SIZE; i++) {
final_sum += data[i] * data[i] * data[i];
}
printf("CPUsum: %d \n", final_sum);
return 0;
}运行结果:
为了对比我们把block改成1再运行一次:
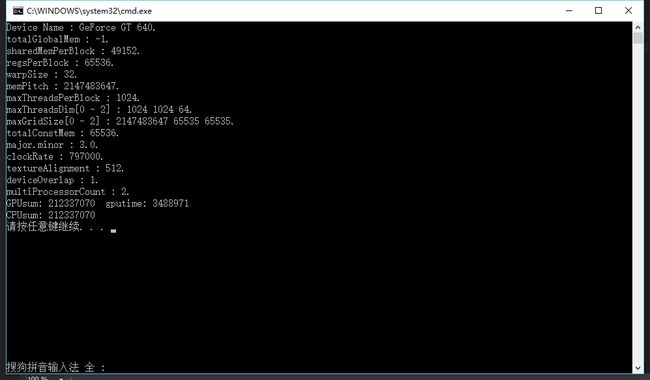
我们看到32block 256 thread 连续存取的情况下运行用了133133个时钟周期
而在 1block 256 thread 连续存取的情况下运行用了3488971个时钟周期
3488971/133133= 26.21倍
可以看到我们的速度整整提升了26倍,这个版本的程序,执行的时间减少很多。
我们还是从内存带宽的角度来进行一下评估:
首先计算一下使用的时间:
133133/ (797000 * 1000) = 1.67e-4S
然后计算使用的带宽:
数据量仍然没有变 DATA_SIZE 1048576,也就是1024*1024 也就是 1M
1M 个 32 bits 数字的数据量是 4MB。
因此,这个程序实际上使用的内存带宽约为:
4MB / 1.67e-4S = 23945.9788MB/s = 23.38GB/s
这对于我这块640,频率仅有797000,已经是一个很不错的效果了,不过,这个程序虽然在GPU上节省了时间,但是在 CPU 上执行的部份,需要的时间加长了(因为 CPU 现在需要加总 8192 个数字)。为了避免这个问题,下一步我们可以让每个 block 把自己的每个 thread 的计算结果进行加总。
关于更多线程的小实验,越多线程越好?
之前中间提过我们为什么不用更多的线程,比如一个block 1024个,或者更多的block。这是因为从线程运行的原理来看,线程数量达到一定大小后,我们再一味的增加线程也不会取得性能提升了,反而有可能会让性能下降。我们可以试验一下:
1024Thread *128block = 101372 个 Thread 够多了吧,我们看下运行结果:
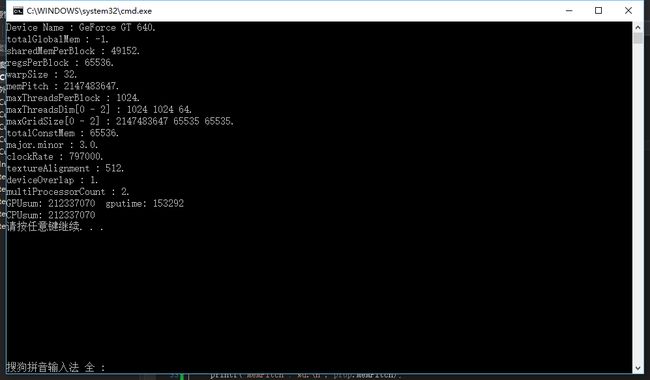
我们看到最终用了153292个时钟周期,劲爆的10万个线程真的变慢了。
为什么会这样呢?下面我们从GPU的原理上来讲解这个问题。
从GPU结构理解线程:
之前关于为什么线程不能这么多的问题,说的还是不是很清楚,其实从硬件角度分析,支持CUDA的NVIDIA 显卡,都是由多个multiprocessors 组成。每个 multiprocessor 里包含了8个stream processors,其组成是四个四个一组,也就是两组4D的处理器。
每个 multiprocessor 还具有 很多个(比如8192个)寄存器,一定的(比如16KB) share memory,以及 texture cache 和 constant cache
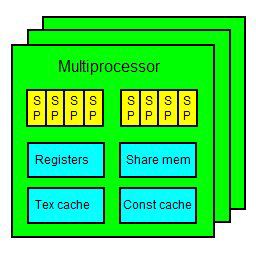
在 CUDA 中,大部份基本的运算动作,都可以由 stream processor 进行。每个 stream processor 都包含一个 FMA(fused-multiply-add)单元,可以进行一个乘法和一个加法。比较复杂的运算则会需要比较长的时间。
在执行 CUDA 程序的时候,每个 stream processor 就是对应一个 thread。每个 multiprocessor 则对应一个 block。但是我们一个block往往有很大量的线程,之前我们用到了256个和1024个,远超一个 multiprocessor 所有的8个 stream processor 。
实际上,虽然一个 multiprocessor 只有八个 stream processor,但是由于 stream processor 进行各种运算都有 latency,更不用提内存存取的 latency,因此 CUDA 在执行程序的时候,是以warp 为单位。
比如一个 warp 里面有 32 个 threads,分成两组 16 threads 的 half-warp。由于 stream processor 的运算至少有 4 cycles 的 latency,因此对一个 4D 的stream processors 来说,一次至少执行 16 个 threads(即 half-warp)才能有效隐藏各种运算的 latency。也因此,线程数达到隐藏各种latency的程度后,之后数量的提升就没有太大的作用了。
还有一个重要的原因是,由于 multiprocessor 中并没有太多别的内存,因此每个 thread 的状态都是直接保存在multiprocessor 的寄存器中。所以,如果一个 multiprocessor 同时有愈多的 thread 要执行,就会需要愈多的寄存器空间。例如,假设一个 block 里面有 256 个 threads,每个 thread 用到20 个寄存器,那么总共就需要 256x20 = 5,120 个寄存器才能保存每个 thread 的状态。
而一般每个 multiprocessor 只有 8,192 个寄存器,因此,如果每个 thread 使用到16 个寄存器,那就表示一个 multiprocessor 的寄存器同时最多只能维持 512 个 thread 的执行。如果同时进行的 thread 数目超过这个数字,那么就会需要把一部份的数据储存在显卡内存中,就会降低执行的效率了。
总结:
这篇博客主要使用block进行了进一步增大了线程数,进行进一步的并行,最终的结果还是比较令人满意的,至少对于我这块显卡来说已经很不错了,因为我的显卡主频比较低,如果用一块1.5Ghz的显卡,用的时间就会是我的一半,而这时候内存带宽也就基本达到45GB/s左右了。
同时也回答了很多人都会有的疑问,即为什么我们不搞几万个线程。
但是我们也看到了新的问题,我们在CPU端的加和压力变得很大,那么我们能不能从GPU上直接完成这个工作呢?我们知道每个block内部的Thread之间是可以同步和通讯的,下一步我们将让每个block把每个thread的计算结果进行加和。
希望我的博客能帮助到大家~
参考资料:《深入浅出谈CUDA》