CNN-tracking-文章导读
1.MDnet:learning multi-domain convolution neural networks for visual tracking
MDnet是vot2015的冠军paper,由韩国Postech的Bohyung Han发表,测试了代码,在多个benchMark上的测试结果都比较好,但是速度比较慢,1fps,下面就开始介绍这篇paper的整体思路。
1.1 文章特点
a) shared layer 为offline train, unshared layer的parameter为online train.
b) 在offline阶段,fc6层有多个branches,每一个branch对应一种video/sequence[paper 中取名叫 domain-specific layers],即在进行train iteration时,每一次iteration,只有一个branch的fc6响应,所以需要每一次迭代的data-batch[文中叫mini-batch]要与相应的fc6_K相对应[原文为:Each domain in MDNet is trained separately and iteratively while the shared layers are updated in every iteration]。
c) online阶段,将fc6_1~fc6_K换为一个fc6,然后固定conv的参数不变,训练fc6的权重,病fine-tune fc4~fc5的权重。
d) online阶段,训练数据利用到hard negative的思想,将negative samples 排序,选取其中score大的样本(更接近正样本的negative samples).
1.2 details
a) shared layer的训练流程[offline train]如下图:
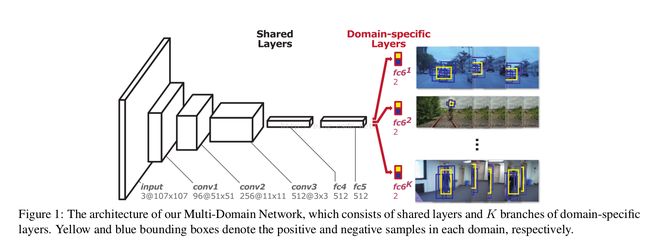
红色部分为domain-specific layers,offline train 时,选取positive&negative的规则见paper的4.4节[也是根据IoU来选]。network并不深,文章分析了采用这种VGG-M network的原因:deep为高级的语义特征,浅层为具有区分的特征。
b) 对于mini-batch迭代时与fc6对应问题:每次iteration只利用一个sequence[假设时第k个sequence]来生成mini-batch,并激活对应的fc6_k,其他的fc6_i被抑制,所以特别注意有这么一个对应关系。
c) online 阶段网络调整:将Figure1中的红色fc6_1 ~fc6_k统一换成一个fc6,因为在tracking时,只用一个sequence。训练时,固定conv的参数不变,训练fc6的参数,并fine-tune fc4,fc5的参数。因为原文中将conv3的输出作为特征,并不是fc5的输出作为特征,因为fc5输出的特征更具有语义性。最后网络输出score
d) online
阶段数据选取规则[hard minibatch]:原文The hard negative examples are identified by testing M− (>> M_h − ) negative samples and selecting the ones with top M_h- positive scores.利用Gaussion 分布来选取候选框[translation],并做一定的scale处理[具体设置见paper]
update策略:采用Long-term(T_l) & short-term(T_s)更新,原文:Long-term updates are performed in regular intervals using the positive samples collected for a long period of time while short-term updates are conducted whenever potential tracking failures are detected—when the estimated target is classified as background—using the positive samples in a short-term period。
Bounding box regression:利用conv3出来的特征做regression.paper 只是利用了first frame来train regressor[time cosuming].
parameter details: T_l=100,T_s=20[其他参数设置见原paper]
2. Fcnt:Visual Tracking with Fully Convolutional Networks
由港中文王晓刚发表,调试了代码,速度比MDnet快3倍左右,3fps.效果比MDnet差点,比一般的传统算法较好。
2.1 文章特点
a) 同样时offline pre-trained
b) 主要探索了不同Layer的特征具有不同的表达[基于VGG-net],toper layers 更多的时语义特征,而lower更多的discriminative information。
c) 然后在b)的基础上,运用不同的layers的feature map来做tracking.选择某些层的feature map可以去掉一些干扰[原文这么说得]
2.2 details
a)首先作者进行实验说明不同layers的feature map 有不同的意义,toper layers 更多的类别信息[对应选取conv5_3的特征],lower更多间内差别的信息[对应选取conv4_3的特征]。并且发现特征是稀疏的[很多背景的响应为zores,所以用稀疏矩阵更好],所以作者利用第一帧的mask和卷积的特征F,来计算稀疏矩阵C,之后,C固定,在之后的帧中,利用F和C来反求mask,公式如下:
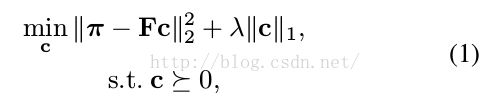
b) paper中提出的方法如下:

步骤为:
根据conv5_3和conv4_3筛选feature map(paper中4.1节有公式,更具对loss function的贡献来选择).因为conv4_3和conv5_3有很多个channels的feature map 它要选择一个最好的feature map 最为对应Gnet和Snet的输入。
利用conv5_3的特定feature map生成Gnet,conv4_3的特定feature map生成Snet,在Figure5中(c),(d)的两层卷积是一样的,Snet和Gnet的update策略不同(4.3节有update的策略,fix Gnet, update Snet very 20 frames,在更新Snet时,加入第一帧作为监督,因为只有第一帧是可信的)。
对于input,将候选区域(既有前景又有背景)crop后feed给VGG Net.
根据Snet和Gnet来确定跟踪的结果(4.2节有Location的策略,mentor paper sharing时提到,其实就是求概率score的最大,写paper时直接这么写太low)。
3. Learning to Track at 100 FPS with Deep Regression Networks
这篇文章也是基于cnn的tracking,貌似这篇文章没有被收录。思想很简单,下面说一下基本思想
3.1 文章特点
a) 针对以前有online的cnn-tracking,本问提出offline-cnn-tracking[就连最后的fc都是offline-cnn,可以看出此处会有些效果不好],由于时offline,所以速度很快,100fps.
b) 网络的输出:t_frame 相对 t-1_frame的位移坐标(相当于已经回归后的position)。
3.2 details
a) 训练的流程图如下:

图中,current frame 的crop会比 previous frame的object region大一些(paper中有一个策略),Conv Layers采用的是AlexNet的minor版,卷积后,将current和previous的特征输出合在一起为n*1的向量,然后fc层,最后以相对previous frame的center位置的评议向量(坐标)为输出。由于很简单,就不多说了。
4.Online Tracking by Learning Discriminative Saliency Map with Convolutional Neural Network
cnn-tracking的思路大同小异.
4.1 文章特点
a) paper采用RCNN特征学习为offline,以fc6输出为特征,然后online的SVM分出正负sample。
b) 定位:利用SVM的weight和SVM分类出来的positive samples反投影为Target-specific features,进而得到saliency map,利用Generative model来定位。
c) update SVM&Generative model.
4.2 details
a) 流程图:

图中,sample features是fc6层出来的特征,这一步为offline,在SVM时,正负样本也是利用IoU来选取。
那么怎么利用SVM weights 和分类后的positive sample来获取显著图呢,显著图的直观意义为:The class-specific saliency map of a given image I is the gradient of class score Sc(I) with respect to the image as:

上式求解过程见原paper,求解会用到SVM weight.最后利用概率求最佳位置。
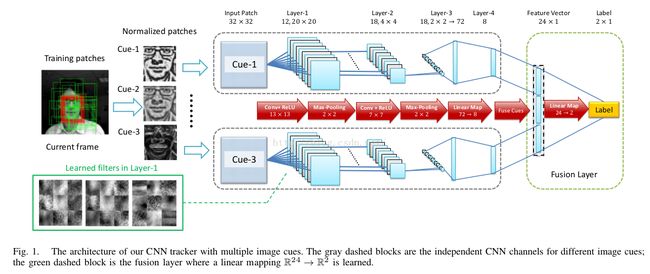
5.DeepTrack: Learning Discriminative Feature Representations Online for Robust Visual Tracking
由于时间关系,先上传流程图,有时间在补充每一步的细节。fps1.5~4.0
5.1 文章特点
a) CNN online:注意有positive samples pool,从中挑选样本来训练,以及模型更新的策略,生成不同的cues
b) boss funtion
c) SGD.
5.2 details(以后补充)
输出:2D,表示正负score,利用指数函数来增加score的差距
cues之后的特征合在一起
输入图像灰度归一化到[0,10]
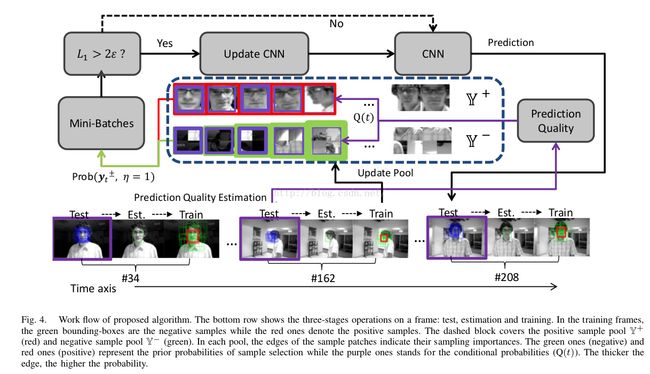
online 更新的策略:long-term和short-term,long-term从positive sample pool 中按照一定概率抽取,负样本同理。
最后按照mini-batch的误差大小来确定是否更新模型。