【人脸识别】FaceNet(一)---Triplet Loss
本文分以下三个部分来讲解: siamese network、Triplet loss、FaceNet中的Triplet Selection
(一)siamese network孪生网络
对于两个不同的输入,运行相同的卷积神经网络,然后比较它们,这一般叫做 Siamese network。
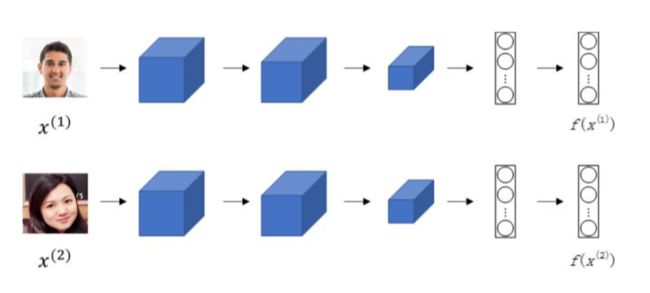
若一张图片经过一般的CNN网络(包括CONV层、POOL层、FC层),最终得到全连接层FC,该FC层可以看成是原始图片的编码,表征了原始图片的关键特征。
图片之间的相似度可以用图片的空间距离来表征,将两张图片的距离定义为这两张图片的编码之差的范数
d ( x 1 , x 2 ) = ∣ ∣ f ( x 1 ) − f ( x 2 ) ∣ ∣ 2 d(x_{1},x_{2} )= ||f(x_{1})-f(x_{2})||^{2} d(x1,x2)=∣∣f(x1)−f(x2)∣∣2
**如何训练?**利用梯度下降算法,不断更新网络参数,使得属于同一人的图片之间 d d d值很小,而不同人的图片之间 d d d值很大。
(二)Triplet loss(三元组损失函数)
Triplet Loss需要每个样本包含三张图片:
目标(Anchor)、正例(Positive)、反例(Negative)

loss函数推导过程:
d ( A , P ) = ∣ ∣ f ( A ) − f ( P ) ∣ ∣ 2 d(A,P)=||f(A)-f(P)||^{2} d(A,P)=∣∣f(A)−f(P)∣∣2 、 d ( A , N ) = ∣ ∣ f ( A ) − f ( N ) ∣ ∣ 2 d(A,N)=||f(A)-f(N)||^{2} d(A,N)=∣∣f(A)−f(N)∣∣2
d ( A , P ) 和 d ( A , N ) d(A,P)和d(A,N) d(A,P)和d(A,N)之间存在如下关系:
$d(A,P) 存在一个参数 α , α > 0 \alpha,\alpha>0 α,α>0 ⇒ d ( A , P ) − d ( A , N ) ≤ − α ⇒ d ( A , P ) − d ( A , N ) + α ≤ 0 \Rightarrow d(A,P)-d(A,N) \leq -\alpha \Rightarrow d(A,P)-d(A,N) +\alpha \leq 0 ⇒d(A,P)−d(A,N)≤−α⇒d(A,P)−d(A,N)+α≤0 Triplet Loss定义如下: l ( A , P , N ) = m a x ( ∣ ∣ f ( A ) − f ( P ) ∣ ∣ 2 − ∣ ∣ f ( A ) − f ( N ) ∣ ∣ 2 + α , 0 ) l(A,P,N)=max(||f(A)-f(P)||^{2}-||f(A)-f(N)||^{2}+\alpha,0) l(A,P,N)=max(∣∣f(A)−f(P)∣∣2−∣∣f(A)−f(N)∣∣2+α,0) 为了更好地训练网络,我们需要选择那些训练有“难度”的三元组,也就是选择的三元组满足: 最后模型效果: (三)谷歌人脸识别系统FaceNet Triplet Selection 在线生成triplets,即在每个mini-batch中进行筛选positive/negative样本。每个mini-batch中,我们对单个个体选择40张图片作为正样本,随机筛选其它图片作为负样本。 样本选取的理想情况: a minimal number of exemplars of any one identity is present in each mini-batch 单个类别的全部样本必须在一个mini-batch中 In our experiments we sample the training data such that around 40 faces are selected per identity per minibatch. Additionally, randomly sampled negative faces are added to each mini-batch. 一个mini-batch中,每个类别有40张图片,先组成A-P对,然后再随机抽取满足条件的N组成(A,P,N)三元组。 Instead of picking the hardest positive, we use all anchor-positive pairs in a mini-batch while still selecting the hard negatives. We found in practice that the all anchor-positive method was more stable and converged slightly faster(收敛更快) at the beginning of training 具体过程: 每个batch有多类图,每类图有多张 (A,N)需满足的条件: 实现如下: 1、从数据集中选择图片,组成一个batch 2、三元组的选取
d ( A , P ) ≃ d ( A , N ) d(A,P)\simeq d(A,N) d(A,P)≃d(A,N)
人为选择A与P相差较大,A与N相差较小。
如果两个图片是同一个人,那么它们的d就会很小,如果两个图片不是同一个人,它们的d会很大。
FaceNet采用的方法是通过卷积神经网络学习将图像映射到欧几里得空间。空间距离直接和图片相似度相关:同一个人的不同图像在空间距离很小,不同人的图像在空间中有较大的距离。
![]()
![]()
模型想要达到的效果:
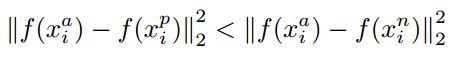
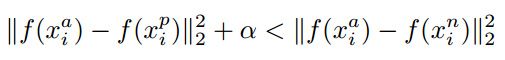
1、调用sample_people()方法从训练数据集中抽取一组图片
2、计算得到这组图片在当时的网络模型中的embedding,保存在emb_array当中。
3、调用select_triplets()得到(A,P,N)三元组all_neg = np.where(neg_dists_sqr-pos_dist_sqr<alpha)[0] # VGG Face
#从数据集中进行抽样图片,参数为训练数据集,每一个batch抽样多少人,每个人抽样多少张
def sample_people(dataset, people_per_batch, images_per_person):
#总共应该抽样多少张 默认:people_per_batch:45 images_per_person:40
nrof_images = people_per_batch * images_per_person
#数据集中一共有多少人的图像
nrof_classes = len(dataset)
#每个人的索引
class_indices = np.arange(nrof_classes)
#随机打乱一下
np.random.shuffle(class_indices)
i = 0
#保存抽样出来的图像的路径
image_paths = []
#抽样的样本是属于哪一个人的,作为label
num_per_class = []
sampled_class_indices = []
# Sample images from these classes until we have enough
# 不断抽样直到达到指定数量
while len(image_paths)<nrof_images:
#从第i个人开始抽样
class_index = class_indices[i]
#第i个人有多少张图片
nrof_images_in_class = len(dataset[class_index])
#这些图片的索引
image_indices = np.arange(nrof_images_in_class)
np.random.shuffle(image_indices)
#从第i个人中抽样的图片数量
nrof_images_from_class = min(nrof_images_in_class, images_per_person, nrof_images-len(image_paths))
idx = image_indices[0:nrof_images_from_class]
#抽样出来的人的路径
image_paths_for_class = [dataset[class_index].image_paths[j] for j in idx]
#图片的label
sampled_class_indices += [class_index]*nrof_images_from_class
image_paths += image_paths_for_class
#第i个人抽样了多少张
num_per_class.append(nrof_images_from_class)
i+=1
return image_paths, num_per_class
def select_triplets(embeddings, nrof_images_per_class, image_paths, people_per_batch, alpha):
""" Select the triplets for training
"""
trip_idx = 0
#某个人的图片的embedding在emb_arr中的开始的索引
emb_start_idx = 0
num_trips = 0
triplets = []
# VGG Face: Choosing good triplets is crucial and should strike a balance between
# selecting informative (i.e. challenging) examples and swamping training with examples that
# are too hard. This is achieve by extending each pair (a, p) to a triplet (a, p, n) by sampling
# the image n at random, but only between the ones that violate the triplet loss margin. The
# latter is a form of hard-negative mining, but it is not as aggressive (and much cheaper) than
# choosing the maximally violating example, as often done in structured output learning.
#遍历每一个人
for i in xrange(people_per_batch):
#这个人有多少张图片
nrof_images = int(nrof_images_per_class[i])
#遍历第i个人的所有图片
for j in xrange(1,nrof_images):
#第j张图的embedding在emb_arr 中的位置
a_idx = emb_start_idx + j - 1
#第j张图跟其他所有图片的欧氏距离
neg_dists_sqr = np.sum(np.square(embeddings[a_idx] - embeddings), 1)
#遍历每一对可能的(anchor,postive)图片,记为(a,p)吧
for pair in xrange(j, nrof_images): # For every possible positive pair.
#第p张图片在emb_arr中的位置
p_idx = emb_start_idx + pair
#(a,p)之前的欧式距离
pos_dist_sqr = np.sum(np.square(embeddings[a_idx]-embeddings[p_idx]))
#同一个人的图片不作为negative,所以将距离设为无穷大
neg_dists_sqr[emb_start_idx:emb_start_idx+nrof_images] = np.NaN
#all_neg = np.where(np.logical_and(neg_dists_sqr-pos_dist_sqr