smmu实现分析
1.概述
1.1 SMMU产生背景
了解SMMU产生背景之前,首先要了解DMA工作原理。因为SMMU的产生主要是为了解决虚拟化平台下的DMA重映射问题。
DMA,外设和内存的连接件,用于解放CPU。外设可以通过DMA,将搜集的数据批量传输到内存,然后再发送一个中断通知CPU去内存取。这样减少了CPU被中断的次数,提高了系统的效率。DMA要能够正常工作,首先要进行正确的配置(包括通道选择、DMA源外设地址、DMA目的内存地址及尺寸等信息);其次,一般需要连续的一段或多段物理内存。由于DMA不能像CPU一样通过MMU操作虚拟地址,所以DMA需要的是连续的物理地址。
这对Hypervisor+GuestOS的虚拟化系统来说必须解决一个问题:GuestOS看到的内存并非真实的物理内存,Guest OS的驱动无法正常地把连续的物理内存分配给硬件。于是,现代计算机设计了引入了IOMMU(ARM架构叫SMMU)架构,来对非CPU的外部设备,也提供一个MMU部件,对这些设备发出的地址请求进行翻译。DMA设备是其中最重要的应用。
1.2 SMMU工作原理
SMMU其实就是一个MMU部件,只是它不供CPU用,而是供外设使用。它也提供虚拟地址的管理、映射和翻译工作。其通用流程如下图:

可以发现上图中有多处“Bypass”判断,因为其可以设置为全局Bypass,也可以设置为部分Bypass。因为整个翻译过程有多个步骤,所以可以设置多个Bypass选项。下图则结合具体寄存器,来更详细的说明这个过程:

SMMU_sCR0.CLIENTPD是client port disable的意思,如果设置为1,则相当于全局Bypass了。否则,则开始搜索stream mapping table(SMMU_SMRn寄存器)进行streamID的匹配。
异常情况:
- 如果没有匹配上,同时又设置了SMMU_sCR0.USFCFG=1则报告Unidentified stream fault;而如果设置SMMU_sCR0.USFCFG=0,则Bypass。
- 如果有多个匹配,且设置SMMU_SCR0.SMCFCFG=1,则报告Stream match conflict fault;而如果设置SMMU_SCR0.SMCFCFG=0,则Bypass。
正常情况下,只有一个匹配,则找到对应的SMMU_S2CRn寄存器进行后续判断处理(匹配的具体过程参照附录“stream mapping”)。
首先如果SMMU_S2CRn.TYPE=1,则表示Bypass,同时应用SMMU_S2CRn中设置的相关属性;而如果SMMU_S2CRn.TYPE=2,则表示没有有效的context可用,报错;默认情况下SMMU_S2CRn.TYPE=0,表示正常翻译。
接着会依据SMMU_CBARn.TYPE域来决定后续流程走向,其值与功能对照如下表:
| 0b00:Stage 2 context; ——① 0b01:Stage 1 context with stage 2 bypass ——① 0b10:Stage 1 context with stage 2 fault 0b11:Stage 1 followed by stage 2 translation context ——② |
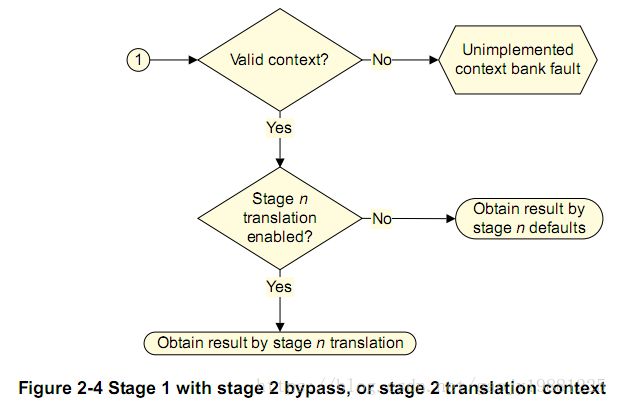
上图说明一点:对于“Stage 2 context”情形,n=2;对于“Stage 1 context with stage 2 bypass”情形,n=1。

对“Stage 1 followed by stage 2 translation context”情形,只有两个stage的context都有效,才属于正常流程。这时,首先判断stage1的MMU翻译功能是否开启?
如果开启(SMMU_CBn_SCTLR.M=1),在判断stage2的MMU翻译功能是否开启?
如果开启,则会正常完成两个stage的翻译,获取结果。
如果没开,则stage1正常查表翻译,stage2采用默认值和属性,获取结果。
如果没开(SMMU_CBn_SCTLR.M=0),仍要判断stage2的MMU翻译功能是否开启?
如果开启,则stage1采用默认值和属性,stage2正常查表翻译,获取结果。
如果没开,则stage1、stage2均采用默认值和属性,获取结果。
注:图中上标——“a,b”,是因为stage1和stage2都有相同格式的SMMU_CBn_SCTLR寄存器。默认值为Bypass的值,默认属性从SMMU_CBn_SCTLR寄存器相应位域获取。
2.初始化
在fiasco内核中,设计了3个类来支持SMMU。其中,Dmar类向应用层提供bind和unbind接口,以便支持SMMU操作的设备能够启用SMMU能力。Io_mmu类主要用于初始化和配置SMMU设备,以便实现设备DMA地址重映射的能力。Dmar_space类为Io_mmu类提供了一个地址空间,以便UVMM能够配置DMA地址重映射所需的页表。
2.1 fiasco内核对smmu初始化
内核对smmu的初始化,主要通过静态类变量方式,在程序运行前就初始化好了。
2.1.1 Dmar类及Dmar_space类初始化
入口为STATIC_INITIALIZE(Dmar),我们可以展开这个宏,翻译一下,就可以得到如下代码段:
| class static_init_class_Dmar{ public: static_init_class_Dmar() FIASCO_INIT; }; static_init_class_Dmar::static_init_class_Dmar(){ Dmar::init(); } static static_init_class_Dmar __static_construction_of_class_Dmar__; |
也就是定义了一个“static_init_class_Dmar”类型的类,同时定义了一个静态实例——“__static_construction_of_class_Dmar__”,并在构造函数里调用Dmar::init()。下面,我们看一下Dmar::init()函数:
| void Dmar::init() { Dmar_space::init(); //调用Dmar_space的init函数初始化——2
_glbl_iommu.construct(); //详见下面分析——1 initial_kobjects.register_obj(_glbl_iommu, Initial_kobjects::Iommu); //注册iommu能力权限 } |
1.我们先来看_glbl_iommu的定义:
| static Static_object |
| kernel/fiasco/src/types/types.h文件中
template< typename T > class Static_object { public: …… operator T * () const { return get(); } T *operator -> () const { return get(); }
T *construct() { return new (_i) T; }
template< typename... A > T *construct(A&&... args) { return new (_i) T(cxx::forward(args)...); }
private: mutable char __attribute__((aligned(sizeof(Mword)*2))) _i[sizeof(T)]; }; |
可以看出,其实就是在_glbl_iommu的私有变量“_i”中保存了一份Dmar的实例。
2.Dmar_space的init函数
| void Dmar_space::init(unsigned max_did) { _max_did = max_did > (unsigned)Max_nr_did ? (unsigned)Max_nr_did : max_did; _free_dids = new Boot_object _initialized = true; } |
而_max_did、_free_dids、_initialized都是static型的,所以这里主要初始化了Dmar_space的静态变量。
2.1.2 Io_mmu类初始化
内核定义了Startup类来初始化启动早期需要的串口、内存、时钟等资源:
| class Startup { public: static void stage1(); static void stage2(); };
STATIC_INITIALIZEX_P(Startup, stage1, STARTUP1_INIT_PRIO); STATIC_INITIALIZEX_P(Startup, stage2, STARTUP_INIT_PRIO); |
“STATIC_INITIALIZEX_P”的定义跟前面“STATIC_INITIALIZE”的定义类似,也是定义了一个静态类,不过增加了“_P”后缀,展开后定义如下:
| class static_init_class_Startup_func { public: static_init_class_Startup_func () FIASCO_INIT; }; static_init_class_Startup_func ::static_init_class_Startup_func () { Startup::stage2(); //这里也可以是Startup::stage1,看传入的func参数 } static static_init_class_Startup_func __static_construction_of_class_Startup_func__ \ __attribute__((init_priority(prio))) |
可以发现,这里增加了一个attribute属性——init_priority(prio)。
注:init_priority是GNU C++用于判断初始化顺序的一个属性,取值范围为101~65535,数值越小,优先级越高(越先初始化)。
在stage2()中会调用Platform_control::init()——》iommu_init()——》Io_mmu::init()
| bool Io_mmu::init(Cpu_number cpu) { iommus.setup(cpu); //Setup函数——1 iommus.reset(cpu); //Reset函数——2
return true; } |
| static Io_mmu iommus; //定义的静态变量iommus |
1.Setup函数
| void Io_mmu::setup(Cpu_number cpu) { …… _version = ARM_SMMU_V2; //SMMU版本 _model = ARM_MMU500; //SMMU硬件架构
_base = Kmem::mmio_remap(Mem_layout::Mc_phys_base); //设置SMMU基地址
/* SMMU_IDR0~2,获取系统能力(包括stage1、2的支持情况、stream matching/indexing支持情况、寄存器空间占用大小、页大小配置及VA和IPA位宽等信息)*/ …… }
|
2.Reset函数
| void Io_mmu::reset(Cpu_number cpu) { …… //具体代码略过 } |
Reset函数所做的动作包括:
- 清全局错误状态寄存器——SMMU_sGFSR
- 初始化Stream Mapping相关寄存器
- 清SMMU_sACR寄存器
- 禁能所有CB,并清CB错误状态寄存器——SMMU_CBn_FSR
- 禁能TLB
- 全局配置寄存器——SMMU_sCR0(使能错误报告、使能错误中断、使能全局配置错误报告、使能全局配置错误中断、禁能TLB广播、允许client接入及其他一些配置)
2.2 uvmm对smmu初始化
Uvmm中对smmu的初始化主要包括两个方面:一是通过IPC调用内核相应的factory方法创建Dmar_space对象;二是映射DMA空间。如下,uvmm在启动Guest OS之前会调用Ram_ds::map_kern_dma_space来完成smmu相关初始化。
| int Ram_ds::map_kern_dma_space(l4_mword_t reserve_size) { …… //获取Task的能力权限 _kern_dmar = ZCore::chkcap(ZCore::Util::cap_alloc.alloc
//创建Dmar_space内核对象 ZCore::chksys(ZCore::Env::env()->factory()->create(_kern_dmar, l4_PROTO_DMA_SPACE)); …… if(add_mem_region(local_map_addr, remote_map_addr, size) == ~0ul) //映射dma空间 return -1; return 0; } |
2.2.1 创建Dmar_space内核对象
“ZCore::Env::env()->factory()->create(_kern_dmar, l4_PROTO_DMA_SPACE)”,就是通过IPC获取Task可用的工厂能力权限,然后调用其create函数创建对象。这里传入的msgtag为l4_PROTO_DMA_SPACE=-17L。
系统中通过“register_factory()”静态构造函数来收集Kobject_iface的工厂对象,类似于static类实例功能,在main函数执行之前就初始化好了。目前系统中有如下地方进行工厂注册:
| kernel/fiasco/src/kern/arm/64/arm_dmar_space.cpp:728:register_factory() kernel/fiasco/src/kern/arm/bsp/jetsontx1/dmar_space.cpp:417:register_factory() kernel/fiasco/src/kern/arm/vm.cpp:246:register_factory() kernel/fiasco/src/kern/factory.cpp:183:register_factory() kernel/fiasco/src/kern/ia32/dmar_space.cpp:551:register_factory() kernel/fiasco/src/kern/ia32/vm_svm.cpp:741:register_factory() kernel/fiasco/src/kern/ipc_gate.cpp:431:register_factory() kernel/fiasco/src/kern/irq.cpp:933:register_factory() kernel/fiasco/src/kern/semaphore.cpp:234:register_factory() kernel/fiasco/src/kern/task.cpp:613:register_factory() kernel/fiasco/src/kern/thread_object.cpp:819:register_factory() kernel/fiasco/src/jdb/kinfo.cpp:213:register_factory() |
其中,“arm_dmar_space.cpp”文件中的“register_factory”定义如下:
| static inline void __attribute__((constructor)) FIASCO_INIT register_factory() { Kobject_iface::set_factory(L4_msg_tag::Label_dma_space, //enum Protocol中定义=”-17L” &Task::generic_factory } |
注:gcc为函数提供了几种类型的属性,其中包含:构造函数(constructors)和析构函数(destructors)。
__attribute__((constructor)) // 在main函数被调用之前调用
__attribute__((destructor)) // 在main函数被调用之后调
所以,通过IPC会调用到内核“Task::generic_factory
| template int UTCB_AREA_MR> TASK_TYPE * FIASCO_FLATTEN Task::create(Ram_quota *q, L4_msg_tag t, Utcb const *u, int *err) { …… typedef Kmem_slab_t *err = L4_err::ENomem; cxx::unique_ptr …… if (EXPECT_FALSE(!v->initialize())) //调用其initialize方法 return 0; …… return v.release(); //释放智能指针的控制权,返回指针 } |
initialize方法
| bool Dmar_space::initialize() { …… //具体代码略过 } |
Initialize方法主要做了如下动作:
- VA、IPA、PA的size大小设置
- Pageshift、level、pgd_size的计算赋值
- 分配pgd所需空间,并将基地址保存在_dmarpt中
2.2.2 映射DMA空间
Uvmm通过add_mem_region函数对DMA空间进行映射。系统实现中传入了整个uvmm地址空间,并以4K为单位,循环调用l4::Task::map()方法来进行虚拟机的IPA地址和物理地址之间的映射。这一步完成了SMMU所需页表的构造过程。
3.绑定
UVMM中透传设备在create阶段会进行smmu 的绑定:
| struct F : Factory { cxx::Ref_ptr Dt_node const &node) override { …… auto prop_start = node.get_prop if(prop_start) { auto src_id = node.get_prop_val(prop_start, prop_sz, 0); devs->ram()->bind_kern_iommu(src_id); } …… } |
| int Ram_ds::bind_kern_iommu(l4_uint64_t src_id) { l4::Cap …… int r = l4_error(iommu->bind(src_id, _kern_dmar)); …… } |
| namespace l4 { class Iommu : public Kobject_x { public: l4_INLINE_RPC( l4_msgtag_t, bind, (l4_uint64_t src_id, Ipc::Cap …… }; } |
| #define l4_INLINE_RPC(res, name, args...) \ l4_INLINE_RPC_NF(res, name, args); l4::Ipc::Msg::Call |
| #define l4_INLINE_RPC_NF(res, name, args...) \ struct name##_t : l4::Ipc::Msg::Rpc_inline_call { \ typedef Rpc_inline_call type; \ l4_INLINE_RPC_SRV_FORWARD(name); \ } |
| #define l4_INLINE_RPC_SRV_FORWARD(name) \ template { \ OBJ *o; \ fwd(OBJ *o) : o(o) {} \ template { return o->op_##name(a...); } \ } |
可以发现,最终它会调用op_bind函数进行绑定,对应到内核对象就是:Dmar::op_bind
| L4_msg_tag Dmar::op_bind(Ko::Rights, Unsigned64 src_id, Ko::Cap { …… iommu->set_context_entry(src_id, space.obj); //初始化一个CB相关寄存器 …… } |
这里会调用set_context_entry函数来初始化一个CB相关寄存器,其主要步骤为:
- 取出src_id,低16位作为StreamID,高16位作为mask
- 通过sid、mask找到对应stream match组的index(初始化阶段会直接返回一个free的组)
- 在SMMU_SMRn寄存器中写入sid和mask信息,在SMMU_S2CRn寄存器中填写默认的type(bypass模式)和cbindex信息,其中n为第2步返回的index
- 获取空闲CB的index
- 初始化此CB的相关寄存器
- 修改SMMU_S2CRn寄存器,将type设置为translation模式,cbindex设置为上面初始话的CB的index
注:一个stream match组为一个SMMU_SMRn寄存器和一个SMMU_S2CRn寄存器,其中n相等。如SMMU_SMR1和SMMU_S2CR1为一组。
上面第5步——“初始化此CB的相关寄存器”可以细分如下:
- 根据CB的index获取对应CB的基地址
- 设置SMMU_CBA2Rn寄存器,字段VMID设置为cb_index+1
- 初始化SMMU_CBARn寄存器的type、MemAttr、BPSHCFG等参数
- 页表首地址赋值给SMMU_CBn_TTBRm寄存器,并设置ASID位
- 获取页粒度、属性、ipa位数
及va空间大小等,填充SMMU_CBn_TCR和SMMU_CBn_TCR2寄存器 - 设置内存属性寄存器SMMU_CBn_MAIRm
- 设置SMMU_CBn_SCTLR寄存器,使能关联CB的MMU功能
4.附录:
Stream mapping
如何通过streamID找到对应的CB。这里有两种模式:
Stream matching:
利用StreamID在 Stream Match registers(SMMU_SMRn)中查找,如果找到唯一的匹配(假设是SMMU_SMRx),则对应的 Stream-to-Context register(SMMU_S2CRx)中保存的CB index就是要找的CB。
Stream indexing:
如果Stream indexing被使用,则StreamID直接指示SMMU_S2CRn的索引。比如,StreamID=m,则对应的CB index保存在SMMU_S2CRm中。
以上两种模式的支持情况可以从SMMU_IDR0.SMS位域读取。
上图中SMMU_SMRn、SMMU_S2CRn及SMMU_CBARn一一对应,配对成组。类似于cpu的mmu,Translation context bank中的TTBR0和TTBR1分别指向高低2段虚拟地址空间的页表。自然的,stage2的context bank没有TTBR1属性。
另外,共享地址空间的设备属于同一个Domain。不同StreamID可以通过映射到同一Translation context bank来共享地址空间,即实现Domain的概念,因而可使用Translation context bank在CBT中的index作为Domian ID。