一、关系数据库概述
20世纪80年代后,在商用数据库管理系统中,( 关系模型 )逐渐取代早 期的网状模型和层次模型,成为主流数据模型

SQL3(SQL-99):1999年
SQL2(SQL-92):1992年
SQL(SQL-89) :1989年
关系数据库的基本特征是使用关系数据模型组织数据,这种思想来源于数学。
关系数据库的优点:高级的分过程语言接口、较好的数据独立性,为商品化的关系数据库管理系统的研制做好了技术上的准备
二、关系数据模型
数据模型的要素包括:数据结构、数据操作、数据约束
关系数据模型的组成要素:关系数据结构、关系操作集合、关系完整性约束
********************************1、关系数据结构***************************

表(Table): 也称为关系,是一个二维的数据结构,由表名、列、若干行数据组成;每个表有唯一的表名,表中每一行数据描述一条具体的记录值
关系(Relation): 一个关系逻辑上对应一张二维表,可以为每个关系取一个名称进行表示。基本关系 (基本表、 基表)、 查询表、 视图表(导出的虚表)
列(Column) :也称为字段(Field)或属性(Attribute)。属性的个数称为关系的元或度;列的值称为属性值,其取值范围称为值域
行(Row): 也称为元组(Tuple)或记录(Record)。表中的数据按行存储。
分量(Component):(具体的数据项) :元组(行)中的一个属性值,称为分量。
域(Domain) :表示属性的取值范围
数据类型(Data Type): 每个列都有相应的数据类型,它用于限制(或容许)该列中存储的数据。
码或键(Key): 属性(或属性组)的值都能用来唯一标识该关系的元组,则称这些属性( 或属性组)为该关系的码或键
超码或超键(Super Key): 在码中去除某个属性,它仍然是这个关系的码
候选码或候选键(Candidate Key): 在码中不能从中移去任何一个属性,否则它就不再是这个关系的码或键;候选码或候选键是这个关系的最小超码或超键。
主属性(Primary Attribute)或非主属性(Nonprimary Attribute): 包含在任何一个候选码中的属性称为主属性或码属性
主码或主键(Primary Key): 在若干个候选码中指定一个唯一标识关系的元组(行)
全码或全键(All Key) :一个关系模式的所有属性集合是 这个关系的主码或主键,这样的 主码或主键称为全码或全键。
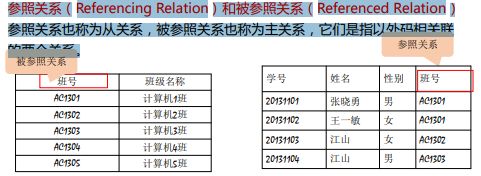
外码或外键(Foreign Key): 某个属性(或属性组)不是这个关系的主码或候选码,而是另一个关系的 主码
参照关系(Referencing Relation)和被参照关系(Referenced Relation): 参照关系也称为从关系,被参照关系也称为主关系,它们是指以外码相关联 的两个关系。
关系模式(Relation Schema): 关系模式是型(type),关系是 值(value),即关系模式是对关 系的描述;关系模式是静态的、稳定的; 关系是动态的、随时间不断变化 的。
关系数据库(Relation Database) 所有关系的集合,构成一个关系数据库。 以关系模型作为数据的逻辑模型,并采用关系作为数据组织方式的一类数 据库,其数据库操作建立在关系代数的基础上。
关系数据库对关系的限定/要求:
1)每一个属性都是不可分解的(不允许表中有表);
2)每一个关系仅仅有一种关系模式;
3)每一个关系模式中的属性必须命名,属性名不同;
4)同一个关系中不允许出现候选码或候选键值完全相同的元组;
5)在关系中元组的顺序(即行序)是无关紧要的,可以任意交换;
6)在关系中属性的顺序(即列序)是无关紧要的,可以任意交换。
******************************2、关系操作集合**************************************
基本的关系操作:
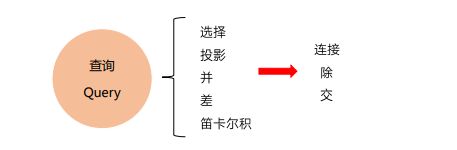
查询 Query (集合的操作方式(一次一集合))
插入 Insert
删除 Delete
修改 Update
****************************************************************************
关系数据语言的分类
关系代数语言:任何一种操作都包含三大要素: 操作对象、 操作符 、操作结果
SQL:结构化查询语言
关系演算语言: 元组关系演算 、域关系演算
共同特点:具有完备的表达能力,是非过程化的集合操作语言,功能强, 能够独立使用也可以嵌入高级语言中使用。
传统的集合运算:
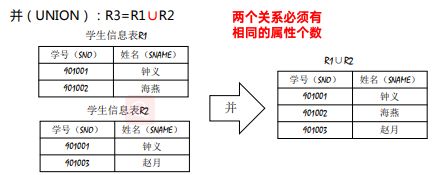
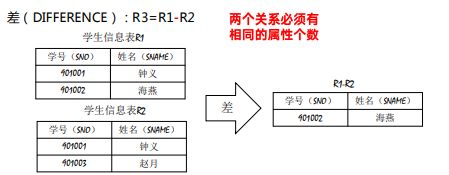
*************************差(DIFFERENCE):R3=R1-R2******************************
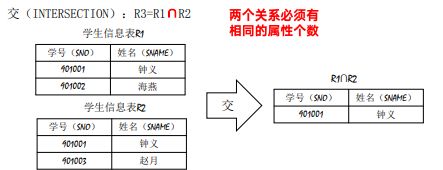
**********************交(INTERSECTION):R3=R1∩R2**************************
********************笛卡尔积(CARTESIAN PRODUCT):R3=R1×R2********************

专门的关系运算
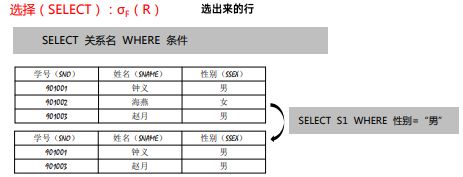
***************************投影(PROJECTION):πA(R)**************************************
A:是属性序列
关系代数中投影运算是对关系进行的垂直分解

*************************连接(JOIN),也称θ连接:**************************************

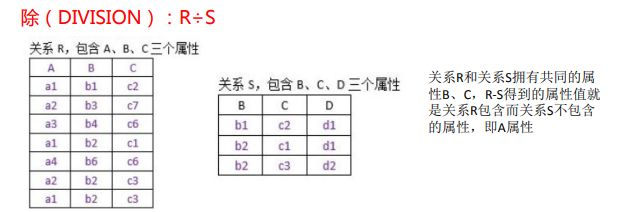
***********************除(DIVISION):R÷S************************************************
************************************************例题**********************************************************

******************************3、关系的完整性约束**************************************
数据库的数据完整性是指数据库中数据的正确性、相容性、一致性
关系的完整性约束分类:
- 实体完整性约束:主码的组成不能为空,主属性不能是空值NULL
- 参照完整性约束:定义外码和主码之间的引用规则 要么外码等于主码中某个元组的主码值,要么为空值(NULL)
- 用户定义完整性约束:域完整性约束(针对某一应用环境的完整性约束)、其他
执行插入操作的检验

执行删除操作
一般只需要对被参照关系检查参照完整性约束(是否被引用)
执行更新操作
上述两种情况的综合
三、关系数据库的规范化理论
关系模式中可能存在的冗余和异常问题
- 数据冗余:指同一数据被反复存储的情况
- 更新异常:数据冗余造成的,多个内容更改使操作错误
- 插入异常
- 删除异常
函数依赖与关键字
函数依赖:关系中属性间的对应关系
X→Y:设R为任一给定关系,如果对于R中属性X的每一个值,R中的属性Y只有唯一 值与之对应,则称X函数决定Y或称Y函数依赖于X,记作X→Y。其中X称为决 定因素。

X /→ Y:![]()
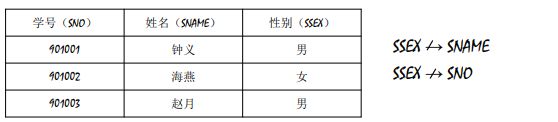
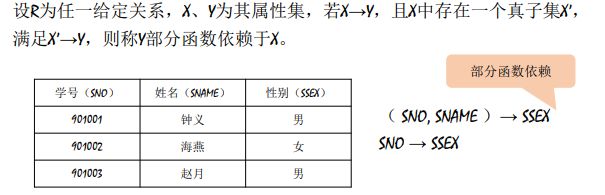
函数依赖分类:完全函数依赖 、部分函数依赖 、传递函数依赖
*****************完全函数依赖************************

*****************部分函数依赖************************
*****************传递函数依赖************************

关键字

范式与关系规范化过程
规范化(Normalization):一个低一级范式的关系模式通过模式分解(Schema Decomposition)可以转换为若干个高一级范式的关系模式 的集合,这种过程就叫规范化(Normalization)
*****************第一范式1NF***********************

第一范式的缺点:

*********************第二范式2NF*************************
设R为任一给定关系,若R为1NF, 且其所有非主属性都完全函数依赖于候选关键字,则R为第二范式。
*************************第三范式3NF*******************
设R为任一给定关系,若R为2NF, 且其每一个非主属性都不传递函数依赖于候选关键字,则R为第三范式
********************第三范式的改进形式BCNF******************

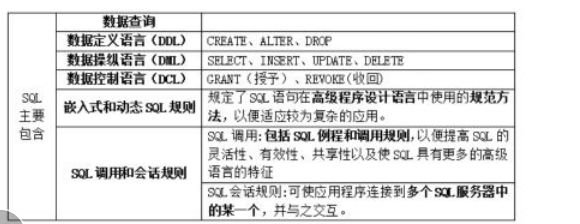
SQL的主要构成: