Java爬虫进阶-HtmlUnit使用解析
大家在做爬虫、网页采集、通过网页自动写入数据时基本上都接触过这两个组件(权且称之为组件吧),网上入门资料已经很多了,我想从实际的应用角度谈谈我对于这两个组件的看法,并记录在博客中,以便日后翻阅,欢迎大家批评指正。
本文主要比较两者的优劣性以及介绍应用中的使用技巧,推荐一些入门资料以及非常实用的辅助工具,希望能对大家有所帮助。
大家有任何疑问或者建议希望留言给我,一起交流学习。
下面我们首先来看下2个组件的区别和优劣性:
HtmlUnit:
HtmlUnit本来是一款自动化测试的工具,它采用了HttpClient和Java自带的网络api结合来实现,它与HttpClient的不同之处在于,它比HttpClient更“人性化”。
在写HtmlUnit代码的时候,仿佛感觉到的就是在操作浏览器而非写代码,得到页面(getPage)– 寻找到文本框(getElementByID || getElementByName || getElementByXPath 等等)– 输入文字(type,setValue,setText等等)– 其他一些类似操作 – 找到提交按钮 – 提交 – 得到新的Page,这样就非常像一个人在后台帮你操作浏览器一样,而你要做的就是告诉他如何操作以及需要填入哪些值。
优点:
一、网页的模拟化
首先说说HtmlUnit相对于HttpClient的最明显的一个好处,HtmlUnit更好的将一个网页封装成了一个对象,如果你非要说HttpClient返回的接口HttpResponse实际上也是存储了一个对象那也可以,但是HtmlUnit不仅保存了这个网页对象,更难能可贵的是它还存有这个网页的所有基本操作甚至事件。这就是说,我们对于操作这个网页可以像在jsp中写js一样,这是非常方便的,比如:你想某个节点的上一个节点,查找所有的按钮,查找样式为“bt-style”的所有元素,对于某些元素先进行一些改造,然后再转成String,或者我直接得到这个网页之后操作这个网页,完成一次提交都是非常方便的。这意味着你如果想分析一个网页会来的非常的容易,比如我附上一段百度新闻高级搜索的代码:
// 得到浏览器对象,直接New一个就能得到,现在就好比说你得到了一个浏览器了
WebClient webclient = new WebClient();
// 这里是配置一下不加载css和javaScript,配置起来很简单,是不是
webclient.getOptions().setCssEnabled(false);
webclient.getOptions().setJavaScriptEnabled(false);
// 做的第一件事,去拿到这个网页,只需要调用getPage这个方法即可
HtmlPage htmlpage = webclient.getPage("http://news.baidu.com/advanced_news.html");
// 根据名字得到一个表单,查看上面这个网页的源代码可以发现表单的名字叫“f”
final HtmlForm form = htmlpage.getFormByName("f");
// 同样道理,获取”百度一下“这个按钮
final HtmlSubmitInput button = form.getInputByValue("百度一下");
// 得到搜索框
final HtmlTextInput textField = form.getInputByName("q1");
// 最近周星驰比较火呀,我这里设置一下在搜索框内填入”周星驰“
textField.setValueAttribute("周星驰");
// 输入好了,我们点一下这个按钮
final HtmlPage nextPage = button.click();
// 我把结果转成String
String result = nextPage.asXml();
System.out.println(result); 然后你可以把得到的result结果复制到一个文本,然后用浏览器打开该文本,是不是想要的东西(如图结),很简单对吧,为什么会感觉简单,因为它完全符合我们操作浏览器的习惯,当然最终它也是用HttpClient和其它一些工具类实现的,但是这样的封装是非常人性化和令人惊叹的。
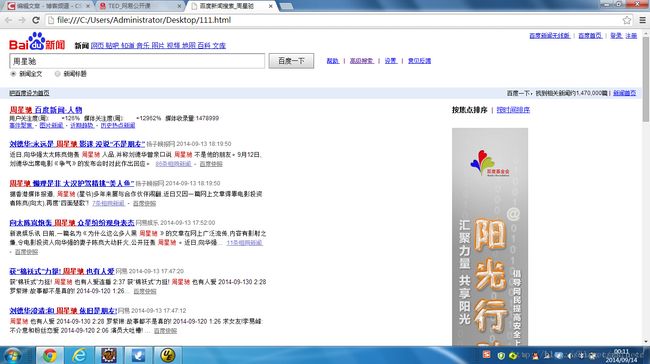
Htmlunit可以有效的分析出 dom标签,并且可以有效的运行页面上的js以便得到一些需要执行JS才能得到的值,你仅仅需要做的就是执行executeJavaScript()这个方法而已,这些都是HtmlUnit帮我们封装好,我们要做的仅仅是告诉它需要做什么。
WebClient webclient = new WebClient();
HtmlPage htmlpage = webclient.getPage("you url");
htmlpage.executeJavaScript("the function name you want to execute"); 对于使用Java程序员来说,对对象的操作就再熟悉不过了,HtmlUnit所做的正是帮我们把网页封装成一个对象,一个功能丰富的,透明的对象。
二、网络响应的自动化处理
HtmlUnit拥有强大的响应处理机制,我们知道:常见的404是找不到资源,100等是继续,300等是跳转…我们在使用HttpClient的时候它会把响应结果告诉我们,当然,你可以自己来判断,比如说,你发现响应码是302的时候,你就在响应头去找到新的地址并自动再跳过去,发现是100的时候就再发一次请求,你如果使用HttpClient,你可以这么去做,也可以写的比较完善,但是,HtmlUnit已经较为完整的实现了这一功能,甚至说,他还包括了页面JS的自动跳转(响应码是200,但是响应的页面就是一个JS),天涯的登录就是这么一个情况,让我们一起来看下。
/**
* @author CaiBo
* @date 2014年9月15日 上午9:16:36
* @version $Id$
*
*/
public class TianyaTest {
/**
*
*/
public static void main(String[] args) throws Exception {
// 这是一个测试,也是为了让大家看的更清楚,请暂时抛开代码规范性,不要纠结于我多建了一个局部变量等
// 得到认证https的浏览器对象
HttpClient client = getSSLInsecureClient();
// 得到我们需要的post流
HttpPost post = getPost();
// 使用我们的浏览器去执行这个流,得到我们的结果
HttpResponse hr = client.execute(post);
// 在控制台输出我们想要的一些信息
showResponseInfo(hr);
}
private static void showResponseInfo(HttpResponse hr) throws ParseException, IOException {
System.out.println("响应状态行信息:" + hr.getStatusLine());
System.out.println("---------------------------------------------------------------");
System.out.println("响应头信息:");
Header[] allHeaders = hr.getAllHeaders();
for (int i = 0; i < allHeaders.length; i++) {
System.out.println(allHeaders[i].getName() + ":" + allHeaders[i].getValue());
}
System.out.println("---------------------------------------------------------------");
System.out.println("响应正文:");
System.out.println(EntityUtils.toString(hr.getEntity()));
}
// 得到一个认证https链接的HttpClient对象(因为我们将要的天涯登录是Https的)
// 具体是如何工作的我们后面会提到的
private static HttpClient getSSLInsecureClient() throws Exception {
// 建立一个认证上下文,认可所有安全链接,当然,这是因为我们仅仅是测试,实际中认可所有安全链接是危险的
SSLContext sslContext = new SSLContextBuilder().loadTrustMaterial(null, new TrustStrategy() {
public boolean isTrusted(X509Certificate[] chain, String authType) throws CertificateException {
return true;
}
}).build();
SSLConnectionSocketFactory sslsf = new SSLConnectionSocketFactory(sslContext);
return HttpClients.custom().//
setSSLSocketFactory(sslsf)//
// .setProxy(new HttpHost("127.0.0.1", 8888))
.build();
}
// 获取我们需要的Post流,如果你是把我的代码复制过去,请记得更改为你的用户名和密码
private static HttpPost getPost() {
HttpPost post = new HttpPost("https://passport.tianya.cn/login");
// 首先我们初始化请求头
post.addHeader("Referer", "https://passport.tianya.cn/login.jsp");
post.addHeader("Host", "passport.tianya.cn");
post.addHeader("Origin", "http://passport.tianya.cn");
// 然后我们填入我们想要传递的表单参数(主要也就是传递我们的用户名和密码)
// 我们可以先建立一个List,之后通过post.setEntity方法传入即可
// 写在一起主要是为了大家看起来方便,大家在正式使用的当然是要分开处理,优化代码结构的
List paramsList = new ArrayList();
/*
* 添加我们要的参数,这些可以通过查看浏览器中的网络看到,如下面我的截图中看到的一样
* 不论你用的是firebut,httpWatch或者是谷歌自带的查看器也好,都能查看到(后面会推荐辅助工具来查看)
* 要把表单需要的参数都填齐,顺序不影响
*/
paramsList.add(new BasicNameValuePair("Submit", ""));
paramsList.add(new BasicNameValuePair("fowardURL", "http://www.tianya.cn"));
paramsList.add(new BasicNameValuePair("from", ""));
paramsList.add(new BasicNameValuePair("method", "name"));
paramsList.add(new BasicNameValuePair("returnURL", ""));
paramsList.add(new BasicNameValuePair("rmflag", "1"));
paramsList.add(new BasicNameValuePair("__sid", "1#1#1.0#a6c606d9-1efa-4e12-8ad5-3eefd12b8254"));
// 你可以申请一个天涯的账号 并在下两行代码中替换为你的用户名和密码
paramsList.add(new BasicNameValuePair("vwriter", "ifugletest2014"));// 替换为你的用户名
paramsList.add(new BasicNameValuePair("vpassword", "test123456"));// 你的密码
// 将这个参数list设置到post中
post.setEntity(new UrlEncodedFormEntity(paramsList, Consts.UTF_8));
return post;
}
} 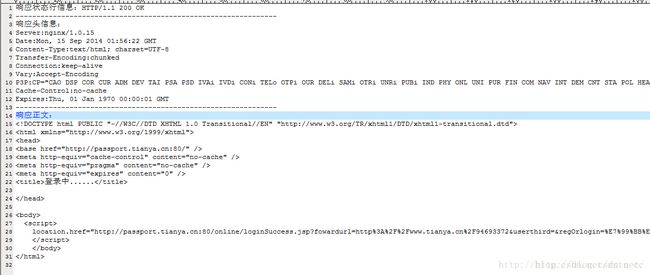
我们看到,响应码确实是200,表明成功了,其实这个响应相当于是302,它是需要跳转的,只不过它的跳转写到了body部分的js里面而已。