lsd-slam源码解读第二篇:DataStructures
lsd-slam源码解读第二篇:DataStructures
第一篇: lsd-slam源码解读第一篇:Sophus/sophus
在进入具体算法之前,我觉得有必要先明白内部数据是怎样储存的,所以第一篇之后的内容自然是数据结构,这些这些数据包括图像,深度预测,帧的ID,以及变换矩阵等等,如果你不太清楚变换矩阵(包括平移,旋转等)是什么,请看我写的源码解读第一篇的内容
最科学的欣赏源码方式,必然是先看内存管理,即进入文件夹下的第二个文件FrameMemory.h
这个文件只有一个类FrameMemory,接口也不多,如下:
class FrameMemory
{
public:
EIGEN_MAKE_ALIGNED_OPERATOR_NEW
static FrameMemory& getInstance();
float* getFloatBuffer(unsigned int size);
void* getBuffer(unsigned int sizeInByte);
void returnBuffer(void* buffer);
boost::shared_lock activateFrame(Frame* frame);
void deactivateFrame(Frame* frame);
void pruneActiveFrames();
void releaseBuffes();
private:
FrameMemory();
void* allocateBuffer(unsigned int sizeInByte);
boost::mutex accessMutex;
std::unordered_map< void*, unsigned int > bufferSizes;
std::unordered_map< unsigned int, std::vector< void* > > availableBuffers;
boost::mutex activeFramesMutex;
std::list activeFrames;
};
这个类偷偷地管理了每一帧的所有内存,第一个函数是getINstance();
注意到构造函数被私有化,显然这是初始化对象的函数,转到实现
FrameMemory& FrameMemory::getInstance()
{
static FrameMemory theOneAndOnly;
return theOneAndOnly;
}
这个函数实现就两行,你会发现内部维护的是一个static的对象,然后返回这个对象,也就是说,一个进程里面,有且仅有一个FrameMemory的对象
void* FrameMemory::getBuffer(unsigned int sizeInByte)
{
boost::unique_lock lock(accessMutex);
if (availableBuffers.count(sizeInByte) > 0)
{
std::vector< void* >& availableOfSize = availableBuffers.at(sizeInByte);
if (availableOfSize.empty())
{
void* buffer = allocateBuffer(sizeInByte);
// assert(buffer != 0);
return buffer;
}
else
{
void* buffer = availableOfSize.back();
availableOfSize.pop_back();
// assert(buffer != 0);
return buffer;
}
}
else
{
void* buffer = allocateBuffer(sizeInByte);
// assert(buffer != 0);
return buffer;
}
}
float* FrameMemory::getFloatBuffer(unsigned int size)
{
return (float*)getBuffer(sizeof(float) * size);
}
void* FrameMemory::allocateBuffer(unsigned int size)
{
void* buffer = Eigen::internal::aligned_malloc(size);
bufferSizes.insert(std::make_pair(buffer, size));
return buffer;
}
这都是类中的函数,明显的是这三个函数是同一组的,因为getFloatBuffer明显调用了getBuffer这个函数
下面详细介绍一下getBuffer
首先进入这个函数的时候,直接调用boost里面的互斥锁,把这段函数里面的这段内存锁上了
这里会用到两个成员变量:
std::unordered_map< void*, unsigned int > bufferSizes;
std::unordered_map< unsigned int, std::vector< void* > > availableBuffers;
从字面上来说,这是两个无序映射
我上c++官网上查了下,实际上就是hash映射(http://www.cplusplus.com/referece/unordered_map/unordered_map/)
判断可用buffer中是否有sizeInByte这个大小的内存,如果有,那么返回1,没有返回0,所以,搜索到会进入if内部,否则进入else内部
进入if内部:首先是获取sizeInByte所对应的value的引用,也就是需要的内存的首地址,之后会判断
- 如果是空的,那么会调用allocateBUffer申请一段内存,注意在allocateBuffer内部调用了Eigen的内存管理函数(底层实际上还是malloc,如果失败会抛出一个throw_std_bad_alloc),之后做一个映射,把buffer的首地址和尺寸映射起来,之后返回buffer的首地址,这样便可以得到一个buffer
- 如果不是空,那么直接得到一个那个尺寸的内存,然后返回
进入else : 如果没有这个尺寸的内存,就调用allocateBuffer申请一段,之后返回
void FrameMemory::releaseBuffes()
{
boost::unique_lock lock(accessMutex);
int total = 0;
for(auto p : availableBuffers)
{
if(printMemoryDebugInfo)
printf("deleting %d buffers of size %d!\n", (int)p.second.size(), (int)p.first);
total += p.second.size() * p.first;
for(unsigned int i=0;i lock(accessMutex);
unsigned int size = bufferSizes.at(buffer);
//printf("returnFloatBuffer(%d)\n", size);
if (availableBuffers.count(size) > 0)
availableBuffers.at(size).push_back(buffer);
else
{
std::vector< void* > availableOfSize;
availableOfSize.push_back(buffer);
availableBuffers.insert(std::make_pair(size, availableOfSize));
}
}
有申请就有释放,以上两个函数是用来释放内存的,returnBuffer只是把内存还回去(放入map中),而真正释放是releaseBuffer,这里就不细讲了
还有三个函数,分别是
boost::shared_lock activateFrame(Frame* frame);
void deactivateFrame(Frame* frame);
void pruneActiveFrames();
他们都是对成员std::list
Frame
帧这玩意儿贯穿始终,是slam中最基本的数据结构,我觉得想要理解这个类,应该从类中的结构体Data开始
struct Data
{
int id;
int width[PYRAMID_LEVELS], height[PYRAMID_LEVELS];
Eigen::Matrix3f K[PYRAMID_LEVELS], KInv[PYRAMID_LEVELS];
float fx[PYRAMID_LEVELS], fy[PYRAMID_LEVELS], cx[PYRAMID_LEVELS], cy[PYRAMID_LEVELS];
float fxInv[PYRAMID_LEVELS], fyInv[PYRAMID_LEVELS], cxInv[PYRAMID_LEVELS], cyInv[PYRAMID_LEVELS];
double timestamp;
float* image[PYRAMID_LEVELS];
bool imageValid[PYRAMID_LEVELS];
Eigen::Vector4f* gradients[PYRAMID_LEVELS];
bool gradientsValid[PYRAMID_LEVELS];
float* maxGradients[PYRAMID_LEVELS];
bool maxGradientsValid[PYRAMID_LEVELS];
bool hasIDepthBeenSet;
// negative depthvalues are actually allowed, so setting this to -1 does NOT invalidate the pixel's depth.
// a pixel is valid iff idepthVar[i] > 0.
float* idepth[PYRAMID_LEVELS];
bool idepthValid[PYRAMID_LEVELS];
// MUST contain -1 for invalid pixel (that dont have depth)!!
float* idepthVar[PYRAMID_LEVELS];
bool idepthVarValid[PYRAMID_LEVELS];
// data needed for re-activating the frame. theoretically, this is all data the
// frame contains.
unsigned char* validity_reAct;
float* idepth_reAct;
float* idepthVar_reAct;
bool reActivationDataValid;
// data from initial tracking, indicating which pixels in the reference frame ware good or not.
// deleted as soon as frame is used for mapping.
bool* refPixelWasGood;
};
Data data;
这就是结构体的源码了,从程序上可以看出,定义了一个金字塔,PYRAMID_LEVELS这个宏在setting.h头文件中
#define SE3TRACKING_MIN_LEVEL 1
#define SE3TRACKING_MAX_LEVEL 5
#define SIM3TRACKING_MIN_LEVEL 1
#define SIM3TRACKING_MAX_LEVEL 5
#define QUICK_KF_CHECK_LVL 4
#define PYRAMID_LEVELS (SE3TRACKING_MAX_LEVEL > SIM3TRACKING_MAX_LEVEL ? SE3TRACKING_MAX_LEVEL : SIM3TRACKING_MAX_LEVEL)
根据上面那一段,目测是等于5了,data里面,定义了帧的id,宽度高度等各种各样的参数,这些参数在函数中都有所访问,浏览完了这些参数后,实际上你会看到帧里面还有两个互斥锁,是否活的flag,以及大量公有变量,这些变量之后我都会有所介绍
构造函数有两个,主要是最后一个参数给的有所不同,实际上它代表的是两种不同格式的图片数据
进入构造函数之后,会调用initialize函数
void Frame::initialize(int id, int width, int height, const Eigen::Matrix3f& K, double timestamp)
{
data.id = id;
pose = new FramePoseStruct(this);
data.K[0] = K;
data.fx[0] = K(0,0);
data.fy[0] = K(1,1);
data.cx[0] = K(0,2);
data.cy[0] = K(1,2);
data.KInv[0] = K.inverse();
data.fxInv[0] = data.KInv[0](0,0);
data.fyInv[0] = data.KInv[0](1,1);
data.cxInv[0] = data.KInv[0](0,2);
data.cyInv[0] = data.KInv[0](1,2);
data.timestamp = timestamp;
data.hasIDepthBeenSet = false;
depthHasBeenUpdatedFlag = false;
referenceID = -1;
referenceLevel = -1;
numMappablePixels = -1;
for (int level = 0; level < PYRAMID_LEVELS; ++ level)
{
data.width[level] = width >> level;
data.height[level] = height >> level;
data.imageValid[level] = false;
data.gradientsValid[level] = false;
data.maxGradientsValid[level] = false;
data.idepthValid[level] = false;
data.idepthVarValid[level] = false;
data.image[level] = 0;
data.gradients[level] = 0;
data.maxGradients[level] = 0;
data.idepth[level] = 0;
data.idepthVar[level] = 0;
data.reActivationDataValid = false;
if (level > 0)
{
data.fx[level] = data.fx[level-1] * 0.5;
data.fy[level] = data.fy[level-1] * 0.5;
data.cx[level] = (data.cx[0] + 0.5) / ((int)1<在这个initialize函数中,对图像内存,位姿参数,相机参数,相机逆参等进行了初始化
相机参数
data.K[0] = K;
data.fx[0] = K(0,0);
data.fy[0] = K(1,1);
data.cx[0] = K(0,2);
data.cy[0] = K(1,2);
相机逆参
data.KInv[0] = K.inverse();
data.fxInv[0] = data.KInv[0](0,0);
data.fyInv[0] = data.KInv[0](1,1);
data.cxInv[0] = data.KInv[0](0,2);
data.cyInv[0] = data.KInv[0](1,2);
初始化金字塔
data.width[level] = width >> level;
data.height[level] = height >> level;
data.imageValid[level] = false;
data.gradientsValid[level] = false;
data.maxGradientsValid[level] = false;
data.idepthValid[level] = false;
data.idepthVarValid[level] = false;
data.image[level] = 0;
data.gradients[level] = 0;
data.maxGradients[level] = 0;
data.idepth[level] = 0;
data.idepthVar[level] = 0;
data.reActivationDataValid = false;
初始化相机金字塔
if (level > 0)
{
data.fx[level] = data.fx[level-1] * 0.5;
data.fy[level] = data.fy[level-1] * 0.5;
data.cx[level] = (data.cx[0] + 0.5) / ((int)1<初始化函数结束之后,自然会在构造函数中将图像拷贝到Frame中来,注意存储格式为float
data.image[0] = FrameMemory::getInstance().getFloatBuffer(data.width[0]*data.height[0]);
float* maxPt = data.image[0] + data.width[0]*data.height[0];
for(float* pt = data.image[0]; pt < maxPt; pt++)
{
*pt = *image;
image++;
}
data.imageValid[0] = true;
privateFrameAllocCount++;
值得注意的是,这里的内存管理是之前讲过的FrameMemory的对象管理的,在这里就调用了getFloatBuffer函数,同样的,析构函数也是如此,内存管理是靠FrameMemory,这里只是回收内存,以后不特别说明,都默认为回收内存
FrameMemory::getInstance().deactivateFrame(this);
if(!pose->isRegisteredToGraph)
delete pose;
else
pose->frame = 0;
for (int level = 0; level < PYRAMID_LEVELS; ++ level)
{
FrameMemory::getInstance().returnBuffer(data.image[level]);
FrameMemory::getInstance().returnBuffer(reinterpret_cast(data.gradients[level]));
FrameMemory::getInstance().returnBuffer(data.maxGradients[level]);
FrameMemory::getInstance().returnBuffer(data.idepth[level]);
FrameMemory::getInstance().returnBuffer(data.idepthVar[level]);
}
FrameMemory::getInstance().returnBuffer((float*)data.validity_reAct);
FrameMemory::getInstance().returnBuffer(data.idepth_reAct);
FrameMemory::getInstance().returnBuffer(data.idepthVar_reAct);
由于有5层金字塔,所以需要循环回收,最后再释放permaRef_colorAndVarData和permaRef_posData,这两个参数是位置,颜色和方差的引用,用于重定位,注意:这个参数只是在initialize中初始化为空指针
在介绍其他函数之前,我觉得应该县说明一下几个辅助函数,因为这些函数总是在很多函数中被调用
void Frame::require(int dataFlags, int level)
{
if ((dataFlags & IMAGE) && ! data.imageValid[level])
{
buildImage(level);
}
if ((dataFlags & GRADIENTS) && ! data.gradientsValid[level])
{
buildGradients(level);
}
if ((dataFlags & MAX_GRADIENTS) && ! data.maxGradientsValid[level])
{
buildMaxGradients(level);
}
if (((dataFlags & IDEPTH) && ! data.idepthValid[level])
|| ((dataFlags & IDEPTH_VAR) && ! data.idepthVarValid[level]))
{
buildIDepthAndIDepthVar(level);
}
}
void Frame::release(int dataFlags, bool pyramidsOnly, bool invalidateOnly)
{
for (int level = (pyramidsOnly ? 1 : 0); level < PYRAMID_LEVELS; ++ level)
{
if ((dataFlags & IMAGE) && data.imageValid[level])
{
data.imageValid[level] = false;
if(!invalidateOnly)
releaseImage(level);
}
if ((dataFlags & GRADIENTS) && data.gradientsValid[level])
{
data.gradientsValid[level] = false;
if(!invalidateOnly)
releaseGradients(level);
}
if ((dataFlags & MAX_GRADIENTS) && data.maxGradientsValid[level])
{
data.maxGradientsValid[level] = false;
if(!invalidateOnly)
releaseMaxGradients(level);
}
if ((dataFlags & IDEPTH) && data.idepthValid[level])
{
data.idepthValid[level] = false;
if(!invalidateOnly)
releaseIDepth(level);
}
if ((dataFlags & IDEPTH_VAR) && data.idepthVarValid[level])
{
data.idepthVarValid[level] = false;
if(!invalidateOnly)
releaseIDepthVar(level);
}
}
}
bool Frame::minimizeInMemory()
{
if(activeMutex.timed_lock(boost::posix_time::milliseconds(10)))
{
buildMutex.lock();
if(enablePrintDebugInfo && printMemoryDebugInfo)
printf("minimizing frame %d\n",id());
release(IMAGE | IDEPTH | IDEPTH_VAR, true, false);
release(GRADIENTS | MAX_GRADIENTS, false, false);
clear_refPixelWasGood();
buildMutex.unlock();
activeMutex.unlock();
return true;
}
return false;
}
即这三个函数,第一个是某种请求函数,第二个是某种释放函数,最后一个是最小化储存函数
首先是require(int, int),这个函数实际上在判断需要怎样的数据,如果这个数据没有,就调用相应的构建函数build*
以buildImage为例
void Frame::buildImage(int level)
{
if (level == 0)
{
printf("Frame::buildImage(0): Loading image from disk is not implemented yet! No-op.\n");
return;
}
require(IMAGE, level - 1);
boost::unique_lock lock2(buildMutex);
if(data.imageValid[level])
return;
if(enablePrintDebugInfo && printFrameBuildDebugInfo)
printf("CREATE Image lvl %d for frame %d\n", level, id());
int width = data.width[level - 1];
int height = data.height[level - 1];
const float* source = data.image[level - 1];
if (data.image[level] == 0)
data.image[level] = FrameMemory::getInstance().getFloatBuffer(data.width[level] * data.height[level]);
float* dest = data.image[level];
int wh = width*height;
const float* s;
for(int y=0;y 这个就是buildImage函数,首先是递归构建底层金字塔,因为上层金字塔是以底层为基础的
if (level == 0)
{
printf("Frame::buildImage(0): Loading image from disk is not implemented yet! No-op.\n");
return;
}
require(IMAGE, level - 1);
递归到底层后,调用buildMutex互斥锁,之后才是判断这个等级的金字塔是否已经构建,然后向内存管理的对象申请内存,之后构建整个金字塔
float* dest = data.image[level];
int wh = width*height;
const float* s;
for(int y=0;y方案是下层金字塔的四个像素的值的平均值合并成一个(同样的,实际上releaseImage也是相应的写法),我想另外说明的一个构建函数是buildGradients(int)函数
这个函数前面部分和所有build函数是一样的,值得注意的是梯度的计算
const float* img_pt = data.image[level] + width;
const float* img_pt_max = data.image[level] + width*(height-1);
Eigen::Vector4f* gradxyii_pt = data.gradients[level] + width;
// in each iteration i need -1,0,p1,mw,pw
float val_m1 = *(img_pt-1);
float val_00 = *img_pt;
float val_p1;
for(; img_pt < img_pt_max; img_pt++, gradxyii_pt++)
{
val_p1 = *(img_pt+1);
*((float*)gradxyii_pt) = 0.5f*(val_p1 - val_m1);
*(((float*)gradxyii_pt)+1) = 0.5f*(*(img_pt+width) - *(img_pt-width));
*(((float*)gradxyii_pt)+2) = val_00;
val_m1 = val_00;
val_00 = val_p1;
}
第一个维度存储的是左右两个像素点的梯度,是中心差分,第二个维度储存了上下两个像素点的梯度,也是中心差分,第三个维度存储了当前图像的值,最后一个维度没有存储数据
最后一个介绍一个build函数应当好好介绍buildIDepthAndIDepthVar(int level)
这个函数一次性build了深度的均值和方差(高斯分布)
int sw = data.width[level - 1];
const float* idepthSource = data.idepth[level - 1];
const float* idepthVarSource = data.idepthVar[level - 1];
float* idepthDest = data.idepth[level];
float* idepthVarDest = data.idepthVar[level];
for(int y=0;y 0)
{
ivar = 1.0f / var;
ivarSumsSum += ivar;
idepthSumsSum += ivar * idepthSource[idx];
num++;
}
var = idepthVarSource[idx+1];
if(var > 0)
{
ivar = 1.0f / var;
ivarSumsSum += ivar;
idepthSumsSum += ivar * idepthSource[idx+1];
num++;
}
var = idepthVarSource[idx+sw];
if(var > 0)
{
ivar = 1.0f / var;
ivarSumsSum += ivar;
idepthSumsSum += ivar * idepthSource[idx+sw];
num++;
}
var = idepthVarSource[idx+sw+1];
if(var > 0)
{
ivar = 1.0f / var;
ivarSumsSum += ivar;
idepthSumsSum += ivar * idepthSource[idx+sw+1];
num++;
}
if(num > 0)
{
float depth = ivarSumsSum / idepthSumsSum;
idepthDest[idxDest] = 1.0f / depth;
idepthVarDest[idxDest] = num / ivarSumsSum;
}
else
{
idepthDest[idxDest] = -1;
idepthVarDest[idxDest] = -1;
}
}
}
这一整块就是构建过程的计算,你会发现各种倒数还有各种加权平均数,看起来特别繁琐,实际上这里的深度是”逆深度”(论文上翻译而来),简单说就是深度的倒数,为啥用”逆深度”,这个实际上在论文里面有详细说明,我就不想多做解释(反正对阅读代码没有太多障碍),简单说他这是怎么算的呢?
首先计算所有的方差的倒数,并把他们加起来,同时用这个倒数乘以逆深度得到一种加权数据,也把这些数据加起来 也就是上面的4个if部分,然后如果这个四个点有可用的num>0,
那么深度就等于float depth = ivarSumsSum / idepthSumsSum,取倒数得到逆深度
最后的不确定度(方差)为idepthVarDest[idxDest] = num / ivarSumsSum
讲了这么多和require有关的函数,也应该讲讲release相关函数了,但实际上这些函数都是成对出现的,所以请读者自行解读
最后一个函数是bool Frame::minimizeInMemory()
这最后这个函数,实际上也比较简单,就是释放一些内存,调用了release()以及clear_refPixelWasGood(),这些函数请自行阅读
void Frame::setDepth(const DepthMapPixelHypothesis* newDepth)
{
boost::shared_lock lock = getActiveLock();
boost::unique_lock lock2(buildMutex);
if(data.idepth[0] == 0)
data.idepth[0] = FrameMemory::getInstance().getFloatBuffer(data.width[0]*data.height[0]);
if(data.idepthVar[0] == 0)
data.idepthVar[0] = FrameMemory::getInstance().getFloatBuffer(data.width[0]*data.height[0]);
float* pyrIDepth = data.idepth[0];
float* pyrIDepthVar = data.idepthVar[0];
float* pyrIDepthMax = pyrIDepth + (data.width[0]*data.height[0]);
float sumIdepth=0;
int numIdepth=0;
for (; pyrIDepth < pyrIDepthMax; ++ pyrIDepth, ++ pyrIDepthVar, ++ newDepth) //, ++ pyrRefID)
{
if (newDepth->isValid && newDepth->idepth_smoothed >= -0.05)
{
*pyrIDepth = newDepth->idepth_smoothed;
*pyrIDepthVar = newDepth->idepth_var_smoothed;
numIdepth++;
sumIdepth += newDepth->idepth_smoothed;
}
else
{
*pyrIDepth = -1;
*pyrIDepthVar = -1;
}
}
meanIdepth = sumIdepth / numIdepth;
numPoints = numIdepth;
data.idepthValid[0] = true;
data.idepthVarValid[0] = true;
release(IDEPTH | IDEPTH_VAR, true, true);
data.hasIDepthBeenSet = true;
depthHasBeenUpdatedFlag = true;
}
这是对深度估计值进行设定,我现在不想过多的说明DepthMapPixelHypothesis这个类型,一会儿用到成员变量的时候,再简单介绍一下
进入这个函数之后,首先调用了锁,把数据都锁了起来,然后申请金字塔第一层的内存,之后对金字塔第一层进行拷贝,注意在lsd-slam中,深度是在用高斯分布进行逼近的,所以拷贝的时候,自然会拷贝一个均值和一个方差
/** Smoothed Gaussian Distribution.*/
float idepth_smoothed;
float idepth_var_smoothed;
以上是高斯分布平滑后的均值和方差(这个是DepthMapPixelHypothesis类型的成员变量),如果某点是缺失的(也就是说没有估计值),那么那一点的值填为-1,最后计算这一帧的平均深度和总共有多少个点被估计出了深度
meanIdepth = sumIdepth / numIdepth;
numPoints = numIdepth;
然后把第一层的深度设置为有效,最后调用release,释放第0层以上层的深度估计值
void Frame::setDepthFromGroundTruth(const float* depth, float cov_scale)
{
boost::shared_lock lock = getActiveLock();
const float* pyrMaxGradient = maxGradients(0);
boost::unique_lock lock2(buildMutex);
if(data.idepth[0] == 0)
data.idepth[0] = FrameMemory::getInstance().getFloatBuffer(data.width[0]*data.height[0]);
if(data.idepthVar[0] == 0)
data.idepthVar[0] = FrameMemory::getInstance().getFloatBuffer(data.width[0]*data.height[0]);
float* pyrIDepth = data.idepth[0];
float* pyrIDepthVar = data.idepthVar[0];
int width0 = data.width[0];
int height0 = data.height[0];
for(int y=0;y 0 && x < width0-1 && y > 0 && y < height0-1 && // pyramidMaxGradient is not valid for the border
pyrMaxGradient[x+y*width0] >= MIN_ABS_GRAD_CREATE &&
!isnanf(*depth) && *depth > 0)
{
*pyrIDepth = 1.0f / *depth;
*pyrIDepthVar = VAR_GT_INIT_INITIAL * cov_scale;
}
else
{
*pyrIDepth = -1;
*pyrIDepthVar = -1;
}
++ depth;
++ pyrIDepth;
++ pyrIDepthVar;
}
}
data.idepthValid[0] = true;
data.idepthVarValid[0] = true;
// data.refIDValid[0] = true;
// Invalidate higher levels, they need to be updated with the new data
release(IDEPTH | IDEPTH_VAR, true, true);
data.hasIDepthBeenSet = true;
}
这个函数是把真实的深度设置给当前帧,循环中判断的意义在于,判断这个点深度是否告知,如果没有,设置为-1
void Frame::prepareForStereoWith(Frame* other, Sim3 thisToOther, const Eigen::Matrix3f& K, const int level)
{
Sim3 otherToThis = thisToOther.inverse();
//otherToThis = data.worldToCam * other->data.camToWorld;
K_otherToThis_R = K * otherToThis.rotationMatrix().cast() * otherToThis.scale();
otherToThis_t = otherToThis.translation().cast();
K_otherToThis_t = K * otherToThis_t;
thisToOther_t = thisToOther.translation().cast();
K_thisToOther_t = K * thisToOther_t;
thisToOther_R = thisToOther.rotationMatrix().cast() * thisToOther.scale();
otherToThis_R_row0 = thisToOther_R.col(0);
otherToThis_R_row1 = thisToOther_R.col(1);
otherToThis_R_row2 = thisToOther_R.col(2);
distSquared = otherToThis.translation().dot(otherToThis.translation());
referenceID = other->id();
referenceLevel = level;
}
这个函数是用来设置变换的,第一个参数传入是哪一帧,第二个参数是这一帧的相似变换矩阵,相机参数,以及金字塔等级
第一行通过求逆得到传入帧到当前帧的变换矩阵(实际上是四元数,在第一篇我已经讲过)
然后算出带有相机的旋转矩阵,以及不带相机和带相机的平移矩阵
我稍微说明一下有没有带相机的区别,根据多视角几何
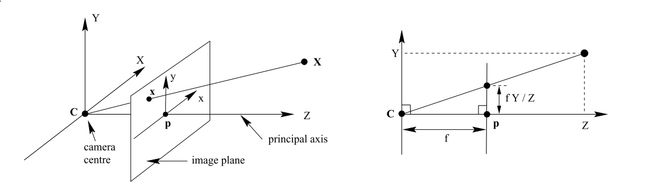
如图所示,实际上相机就是把空间中的点投影到了图像平面(图中image plane)
投影方程如下:

但实际上相机有个相机中心,可能没有和坐标系中心重合,如下图

所以方程会改写为一个投影加上一个平移
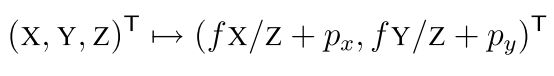
用矩阵表示为

实际上那个又有f又有p的矩阵就是相机矩阵,或者叫做相机内参矩阵,不同的相机有不同的参数
但是往往空间坐标系也和你相机拍摄的坐标系不是重合的,那么自然而然会通过平移和旋转,使得两个坐标系重合
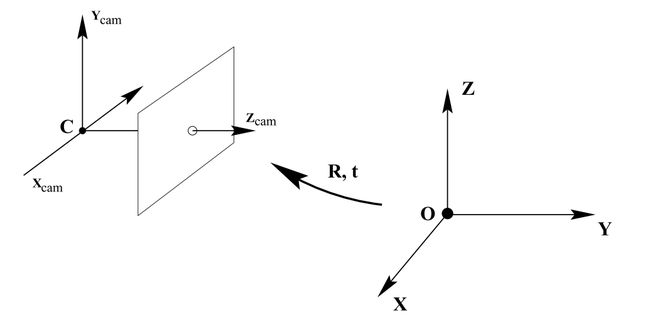
最终你就得到了从空间坐标系到图像坐标系的变换(就是上文提到的带相机的旋转和平移)

后面的工作都是记录传入帧到这一帧的变换矩阵,然后记录传入帧ID,以及两帧之间相机移动的距离,最后记录金字塔等级
FramePoseStruct
FramePoseStruct.hpp和.cpp文件相对来说是最简单的两个文件了
这里面主要定义的是和优化相关的一些数据,比如说和tracking相关的trackingParent,和g2o相关的bool isRegisteredToGrap,bool isOptimizedi,bool isInGraph以及VertexSim3* graphVertex,还有一些设置变换的方法,希望读者自行解读