ORB特征提取详解
网上虽然出现了很多讲解ORB特征提取和描述的方法,但都不够详尽。为了搞明白到底是怎么回事,只能结合别人的博客和原著对ORB的详细原理做一个研究和学习。哪里有不对的地方,请多多指教
1、算法介绍
ORB(Oriented FAST and Rotated BRIEF)是一种快速特征点提取和描述的算法。这个算法是由Ethan Rublee, Vincent Rabaud, Kurt Konolige以及Gary R.Bradski在2011年一篇名为“ORB:An Efficient Alternative to SIFTor SURF”的文章中提出。ORB算法分为两部分,分别是特征点提取和特征点描述。特征提取是由FAST(Features from Accelerated Segment Test)算法发展来的,特征点描述是根据BRIEF(Binary Robust IndependentElementary Features)特征描述算法改进的。ORB特征是将FAST特征点的检测方法与BRIEF特征描述子结合起来,并在它们原来的基础上做了改进与优化。据说,ORB算法的速度是sift的100倍,是surf的10倍。
1.1 Fast特征提取
ORB算法的特征提取是由FAST算法改进的,这里成为oFAST(FASTKeypoint Orientation)。也就是说,在使用FAST提取出特征点之后,给其定义一个特征点方向,以此来实现特征点的旋转不变形。FAST算法是公认的最快的特征点提取方法。FAST算法提取的特征点非常接近角点类型。oFAST算法如下:

图1 FAST特征点判断示意图
步骤一:粗提取。该步能够提取大量的特征点,但是有很大一部分的特征点的质量不高。下面介绍提取方法。从图像中选取一点P,如上图1。我们判断该点是不是特征点的方法是,以P为圆心画一个半径为3pixel的圆。圆周上如果有连续n个像素点的灰度值比P点的灰度值大或者小,则认为P为特征点。一般n设置为12。为了加快特征点的提取,快速排出非特征点,首先检测1、9、5、13位置上的灰度值,如果P是特征点,那么这四个位置上有3个或3个以上的的像素值都大于或者小于P点的灰度值。如果不满足,则直接排出此点。
步骤二:机器学习的方法筛选最优特征点。简单来说就是使用ID3算法训练一个决策树,将特征点圆周上的16个像素输入决策树中,以此来筛选出最优的FAST特征点。
步骤三:非极大值抑制去除局部较密集特征点。使用非极大值抑制算法去除临近位置多个特征点的问题。为每一个特征点计算出其响应大小。计算方式是特征点P和其周围16个特征点偏差的绝对值和。在比较临近的特征点中,保留响应值较大的特征点,删除其余的特征点。
步骤四:特征点的尺度不变形。建立金字塔,来实现特征点的多尺度不变性。设置一个比例因子scaleFactor(opencv默认为1.2)和金字塔的层数nlevels(pencv默认为8)。将原图像按比例因子缩小成nlevels幅图像。缩放后的图像为:I’= I/scaleFactork(k=1,2,…, nlevels)。nlevels幅不同比例的图像提取特征点总和作为这幅图像的oFAST特征点。
步骤五:特征点的旋转不变性。ORB算法提出使用矩(moment)法来确定FAST特征点的方向。也就是说通过矩来计算特征点以r为半径范围内的质心,特征点坐标到质心形成一个向量作为该特征点的方向。矩定义如下:

其中,I(x,y)为图像灰度表达式。该矩的质心为:
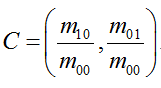
假设角点坐标为O,则向量的角度即为该特征点的方向。计算公式如下:

1.2 rBRIEF特征描述
rBRIEF特征描述是在BRIEF特征描述的基础上加入旋转因子改进的。下面先介绍BRIEF特征提取方法,然后说一说是怎么在此基础上修改的。
BRIEF算法描述
BRIEF算法计算出来的是一个二进制串的特征描述符。它是在一个特征点的邻域内,选择n对像素点pi、qi(i=1,2,…,n)。然后比较每个点对的灰度值的大小。如果I(pi)> I(qi),则生成二进制串中的1,否则为0。所有的点对都进行比较,则生成长度为n的二进制串。一般n取128、256或512,opencv默认为256。另外,值得注意的是为了增加特征描述符的抗噪性,算法首先需要对图像进行高斯平滑处理。在ORB算法中,在这个地方进行了改进,在使用高斯函数进行平滑后,又用了其他操作,使其更加的具有抗噪性。具体方法下面将会描述。
关于在特征点SxS的区域内选取点对的方法,BRIEF论文(附件2)中测试了5种方法:
1)在图像块内平均采样;
2)p和q都符合(0,S2/25)的高斯分布;
3)p符合(0,S2/25)的高斯分布,而q符合(0,S2/100)的高斯分布;
4)在空间量化极坐标下的离散位置随机采样;
5)把p固定为(0,0),q在周围平均采样。
五种采样方法的示意图如下:

论文指出,第二种方法可以取得较好的匹配结果。在旋转不是非常厉害的图像里,用BRIEF生成的描述子的匹配质量非常高,作者测试的大多数情况中都超越了SURF。但在旋转大于30°后,BRIEF的匹配率快速降到0左右。BRIEF的耗时非常短,在相同情形下计算512个特征点的描述子时,SURF耗时335ms,BRIEF仅8.18ms;匹配SURF描述子需28.3ms,BRIEF仅需2.19ms。在要求不太高的情形下,BRIEF描述子更容易做到实时。
改进BRIEF算法—rBRIEF(Rotation-AwareBrief)
(1)steered BRIEF(旋转不变性改进)
在使用oFast算法计算出的特征点中包括了特征点的方向角度。假设原始的BRIEF算法在特征点SxS(一般S取31)邻域内选取n对点集。

经过旋转角度θ旋转,得到新的点对
![]()
在新的点集位置上比较点对的大小形成二进制串的描述符。这里需要注意的是,在使用oFast算法是在不同的尺度上提取的特征点。因此,在使用BRIEF特征描述时,要将图像转换到相应的尺度图像上,然后在尺度图像上的特征点处取SxS邻域,然后选择点对并旋转,得到二进制串描述符。
(2)rBRIEF-改进特征点描述子的相关性
使用steeredBRIEF方法得到的特征描述子具有旋转不变性,但是却在另外一个性质上不如原始的BRIEF算法。是什么性质呢,是描述符的可区分性,或者说是相关性。这个性质对特征匹配的好坏影响非常大。描述子是特征点性质的描述。描述子表达了特征点不同于其他特征点的区别。我们计算的描述子要尽量的表达特征点的独特性。如果不同特征点的描述子的可区分性比较差,匹配时不容易找到对应的匹配点,引起误匹配。ORB论文中,作者用不同的方法对100k个特征点计算二进制描述符,对这些描述符进行统计,如下表所示:

图2 特征描述子的均值分布.X轴代表距离均值0.5的距离,y轴是相应均值下的特征点数量统计
我们先不看rBRIEF的分布。对BRIEF和steeredBRIEF两种算法的比较可知,BRIEF算法落在0上的特征点数较多,因此BRIEF算法计算的描述符的均值在0.5左右,每个描述符的方差较大,可区分性较强。而steeredBRIEF失去了这个特性。至于为什么均值在0.5左右,方差较大,可区分性较强的原因,这里大概分析一下。这里的描述子是二进制串,里面的数值不是0就是1,如果二进制串的均值在0.5左右的话,那么这个串有大约相同数目的0和1,那么方差就较大了。用统计的观点来分析二进制串的区分性,如果两个二进制串的均值都比0.5大很多,那么说明这两个二进制串中都有较多的1时,在这两个串的相同位置同时出现1的概率就会很高。那么这两个特征点的描述子就有很大的相似性。这就增大了描述符之间的相关性,减小之案件的可区分性。
下面我们介绍解决上面这个问题的方法:rBRIEF。
原始的BRIEF算法有5中去点对的方法,原文作者使用了方法2。为了解决描述子的可区分性和相关性的问题,ORB论文中没有使用5种方法中的任意一种,而是使用统计学习的方法来重新选择点对集合。
首先建立300k个特征点测试集。对于测试集中的每个点,考虑其31x31邻域。这里不同于原始BRIEF算法的地方是,这里在对图像进行高斯平滑之后,使用邻域中的某个点的5x5邻域灰度平均值来代替某个点对的值,进而比较点对的大小。这样特征值更加具备抗噪性。另外可以使用积分图像加快求取5x5邻域灰度平均值的速度。
从上面可知,在31x31的邻域内共有(31-5+1)x(31-5+1)=729个这样的子窗口,那么取点对的方法共有M=265356种,我们就要在这M种方法中选取256种取法,选择的原则是这256种取法之间的相关性最小。怎么选取呢?
1)在300k特征点的每个31x31邻域内按M种方法取点对,比较点对大小,形成一个300kxM的二进制矩阵Q。矩阵的每一列代表300k个点按某种取法得到的二进制数。
2)对Q矩阵的每一列求取平均值,按照平均值到0.5的距离大小重新对Q矩阵的列向量排序,形成矩阵T。
3)将T的第一列向量放到R中。
4)取T的下一列向量和R中的所有列向量计算相关性,如果相关系数小于设定的阈值,则将T中的该列向量移至R中。
5)按照4)的方式不断进行操作,直到R中的向量数量为256。
通过这种方法就选取了这256种取点对的方法。这就是rBRIEF算法。
2、ORB特征提取实验
实验代码用opencv中的
2.1ORB特征提取和匹配实验

(1)

(2)

(3)

(4)
2-1 ORB特征匹配
从上图(1)(2)(3)可以看出,ORB算法的特征匹配效果比较理想,并且具有较稳定的旋转不变性。但是通过(4)看出,ORB算法在尺度方面效果较差,在增加算法的尺度变换的情况下仍然没有取得较好的结果。
ORB是一种快速的特征提取和匹配的算法。它的速度非常快,但是相应的算法的质量较差。和sift相比,ORB使用二进制串作为特征描述,这就造成了高的误匹配率。