机器学习对非数值对象的处理
计算机对于数据处理形式只能是数据,因此现在假设数据是非数值的形式,具体形式可能是不同的类别,这时我们需要将类别转化为独热编码的形式才能对数据进行进一步处理。
具体转化工具是利用机器学习的Scikit-learn的工具包,具体展示在下面:
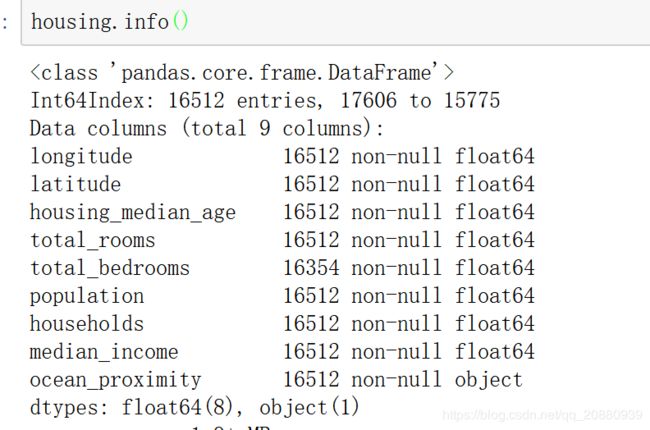
假设我们有一些列数据,暂且命名为housing,上面结果可以看出,在housing的所有属性上,ocean_proximity类型为object,并不是float类型,计算机最后只能处理数值类型数据,所以需要将这种数据转化为数值类型。
经过仔细的分析,我们发现ocean_proximity属性对应的实际上是类别数据,这样我们自然想到利用独热编码表示。
这里转化有两种思路:
思路1: 先将类别数据转换为整数类别,然后将整数类别转化为独热编码形式。需要用到Scikit-learn中LabelEncoder包与OneHotEncoder包。
思路2(一步到位) 利用Scikit-learn中的LabelBinarizer包。
针对思路1:
首先将数据转化为整数类别,利用LabelEncoder包
from sklearn.preprocessing import LabelEncoder
encoder=LabelEncoder()
housing_cat=housing["ocean_proximity"]
housing_cat_encode=encoder.fit_transform(housing_cat)
housing_cat_encodearray([0, 0, 4, ..., 1, 0, 3], dtype=int64)上面就是将对象类别转化为整数类别过程。
那么上述我们已经将对象类别类型转换为数字类型了,为什么还要转化为独热编码形式? 这样做的目的是机器学习算法会以为两个相近数字比两个离得远数字更相近一些,但是独热编码采用二进制方式表示类别,则可以避免这样的问题。
具体转化利用OneHotEncoder包
from sklearn.preprocessing import OneHotEncoder
encoder=OneHotEncoder()
housing_cat_1hot=encoder.fit_transform(housing_cat_encode.reshape(-1,1)) #基于整数类别进行转换
housing_cat_1hot.toarray()array([[1., 0., 0., 0., 0.],
[1., 0., 0., 0., 0.],
[0., 0., 0., 0., 1.],
...,
[0., 1., 0., 0., 0.],
[1., 0., 0., 0., 0.],
[0., 0., 0., 1., 0.]])思路2: 在Scikit-learn中,LabelBinarizer包将思路1的两个转化过程封装在一起了
from sklearn.preprocessing import LabelBinarizer
encoder=LabelBinarizer()
housing_cat_1hot=encoder.fit_transform(housing_cat)
housing_cat_1hotarray([[1., 0., 0., 0., 0.],
[1., 0., 0., 0., 0.],
[0., 0., 0., 0., 1.],
...,
[0., 1., 0., 0., 0.],
[1., 0., 0., 0., 0.],
[0., 0., 0., 1., 0.]])