Tensorflow2.0之自定义数据集
Tensorflow2.0之自定义数据集
Brief
在学习Deep Learning的过程中我们难免会因为需求而要使用自定义的DS,本文就简要的介绍如何自定义DS
PoKemon Dataset
这次我们使用的是PoKemon Dataset ,在自定义数据集之后会训练一下参数效果

数据集使用的是龙龙老师课上的数据集下面是百度网盘的链接:
▪
链接 : https://pan.baidu.com/s/1V_ZJ7ufjUUFZwD2NHSNMFw
▪
提取码: dsxl

Splitting
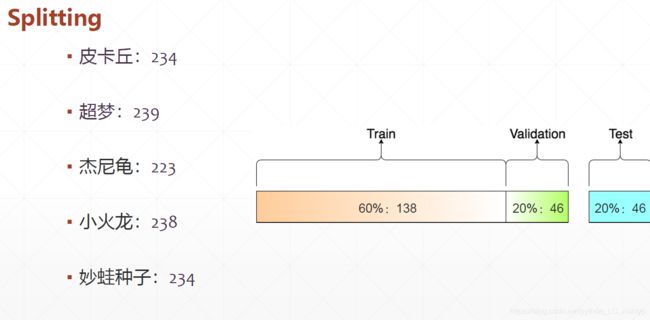
steps
Load data in csv
首先让我们来处理图片,下面是我们的数据集文件夹,每一个文件夹中对应了相应的PoKemo
现在我们想要把他们的数据集写在csv文件中,效果大约如下图:
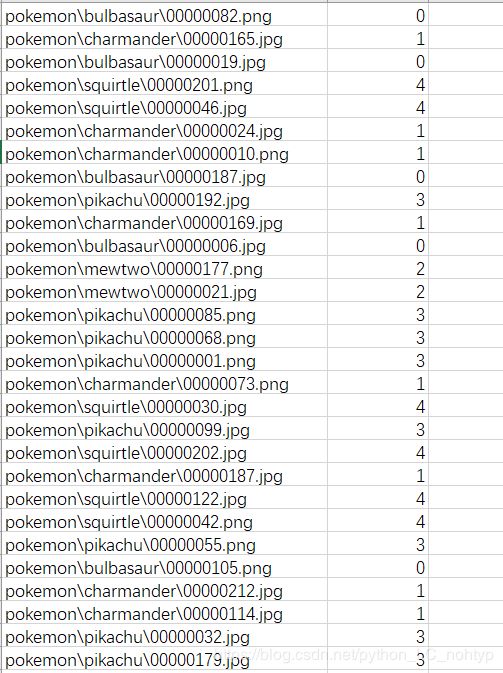
先让我们捋一下思路,首先我们应该读取有pokemon图片的文件夹,然后获取标签,然后写入csv文件
我们用字典来保存我们的图片地址和标签
def load_pokemon(root, model='train'):
"""
load pokemon dataset info
:param root: the root path of dataset
:param model: train val or test
:return: image,labels,name2able
"""
name2label = {}
for name in sorted(os.listdir(os.path.join(root))):
if not os.path.exists(os.path.join(root, name)):
continue
# code each category (use the length of the key)
name2label[name] = len(name2label.keys())
...
ok 现在我们获得了有宝可梦和标签的字典,下面将他们写入到csv文件中
def load_csv(root, filename, name2label):
# this will create a csv file when I first run it.
if not os.path.exists(os.path.join(root, filename)):
images = []
for name in name2label.keys():
# 'pokemon\\name\\00001.png
images += glob.glob(os.path.join(root, name, '*.png'))
images += glob.glob(os.path.join(root, name, '*.jpg'))
images += glob.glob(os.path.join(root, name, '*.jpeg'))
print(len(images), images)
random.shuffle(images)
with open(os.path.join(root, filename), mode='w', newline='') as f:
writer = csv.writer(f)
for img in images:
name = img.split(os.sep)[-2]
lable = name2label[name]
writer.writerow([img, lable])
print('written into csv file', filename)
这样我们就得到了有宝可梦图片地址和标签的地址
现在我们在load_csv 中读取csv文件
images, labels = [], []
# read from csv file
with open(os.path.join(root, filename), 'r') as f:
reader = csv.reader(f)
for row in reader:
img, label = row
label = int(label)
images.append(img)
labels.append(label)
assert len(images) == len(labels)
return images, labels
之后我们在load_pokemon中调用load_csv函数
images, labels = load_csv(root, 'image.csv', name2label)
if model == 'train': # 60%
images = images[:int(0.6 * len(images))]
labels = labels[:int(0.6 * len(labels))]
elif model == 'val': # 20%
images = images[:int(0.2 * len(images))]
labels = labels[:int(0.2 * len(labels))]
else: # 20%
images = images[:int(0.2 * len(images))]
labels = labels[:int(0.2 * len(labels))]
return images, labels
Preprocess the data
现在我们得到的只是图片的地址,并不能直接用来训练,所以我们需要进行预处理
Read and Resize
首先我们先读取图片信息并进行裁剪
定义一个preprocess函数
def preprocess(x, y):
"""
preprocess the data
:param x: the path of the images
:param y: labels
"""
# data augmentation, 0~255
x = tf.io.read_file(x)
x = tf.image.decode_jpeg(x, channels=3)
# resize the image,you can change the value in the another net
x = tf.image.resize(x, [224, 224])
# turn around images
x = tf.image.random_crop(x, [224, 224, 3])
Data Augmentation
# # x: [0,255]=> 0~1
x = tf.cast(x, dtype=tf.float32) / 255
Normalize
这里的img_mean和img_std 都是imgNet 中几百万张数据集中得到的值,我们直接拿过来用就好
img_mean = tf.constant([0.485, 0.456, 0.406])
img_std = tf.constant([0.229, 0.224, 0.225])
def normalize(x, mean=img_mean, std=img_std):
# x: [224, 224, 3]
# mean: [224, 224, 3], std: [3]
x = (x - mean) / std
return x
好的现在我们可以在preprocess后面加上:
# 0~1 => D(0,1)
x = normalize(x)
y = tf.convert_to_tensor(y)
return x,y
现在我们就可以加载了
if __name__ == '__main__':
image_train, lab_train = load_pokemon('pokemon', model='train')
image_val, lab_val = load_pokemon('pokemon', model='val')
image_test, lab_test = load_pokemon('pokemon', model='test')
train_db = tf.data.Dataset.from_tensor_slices((image_train, lab_train))
train_db = train_db.shuffle(1000).map(preprocess).batch(32)
val_db = tf.data.Dataset.from_tensor_slices((image_val, lab_val))
val_db = val_db.map(preprocess).batch(32)
test_db = tf.data.Dataset.from_tensor_slices((image_test, lab_test))
test_db = test_db.map(preprocess).batch(32)
print(train_db)
print(val_db)
print(test_db)
完整的代码可以去我的github上下载:
https://github.com/Jupiter-king/tf2.0-Custom-data-set
参考书籍: TensorFlow 深度学习 — 龙龙老师