从零开始搭建量化投资分析平台之二——从搭建量化投资数据库开始(2)
上一节我们已经得到了一个比较完整的数据库,但是这个数据库并不适用于量化投资的研究,这是为什么呢?
1)数据并没有经过清洗,比如还有一些"None"、“--”数据,会在后续模型搭建中影响正常的矩阵运算。

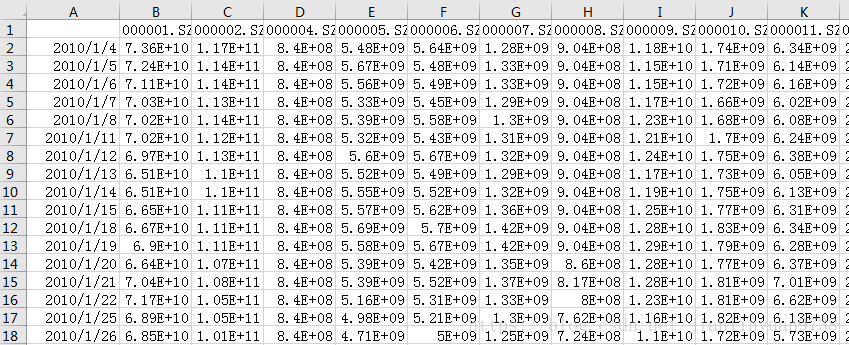
2)当前数据存储的方式并不适合量化分析。如图所示,金融数据是个三维数据,时间维度代表每个交易日,个股维度代表每只股票,指标维度代表每个具体的指标(如日涨跌幅、成交量、换手率、总资产、ROE等)。真正适合量化投资平台的数据存储方式是以时间和个股建立table,然后每个指标分别为一个table。原因有二:
a)量化投资分析的所需要使用数据的股票数量往往有上千只,交易日也往往也有上千个,而指标只有几十个,以指标为单位读取table效率更高。
b)单次量化分析所需要的指标数量往往有限,以Fama-French(1993)三因子模型为例,只需要用到beta,size,value,日收益率等极少数指标,因此这样做有利于最大限度地减少运算冗余,从而提升运算效率。
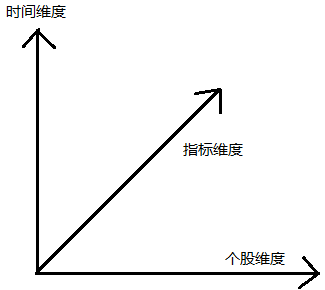
而我们得到的数据是这种形式:
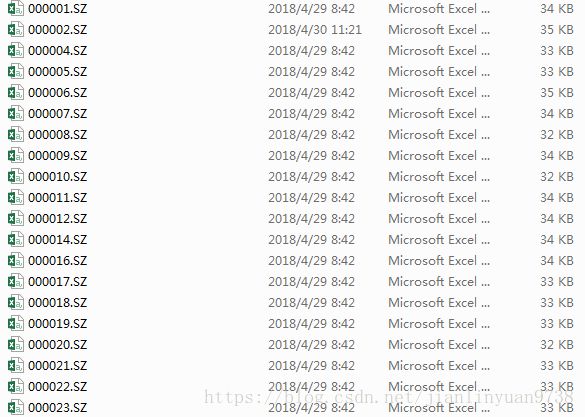
而我们需要的是这种形式:
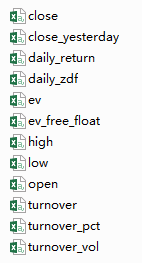
3)维度不统一。即历史行情数据是每日的数据而财务数据是季度数据,我们需要把财务数据变成每日的数据,即当日的财务数据等于当日最新发布财报的数据。
5)未来信息问题。比如年报的报告期为每年的十二月三十一日,但是年报往往要到第二年3月到4月才能公布,因此我们需要对数据进行调整,消除未来信息的影响。
本节主要解决前两个问题。二话不说,直接上代码
# -*- coding: utf-8 -*-
"""
Created on Mon Mar 12 17:32:18 2018
"""
import os
import pandas as pd
class gen_matrix(object):
def __init__ (self):
self.path = 'D:\\database\\history_data\\'
self.factor=['close','high','low','open','close_yesterday','daily_zdf','daily_return','turnover_pct','turnover','turnover_vol','ev','ev_free_float']
#转换为时间个股维度的数据形式
def gen_data(self):
result=[]
for i in range(2,14):
result.append(pd.DataFrame())
file_list=os.listdir(self.path+'shares')
for file in file_list:
try:
data=pd.read_csv(self.path+'shares\\'+file,index_col=0,encoding='GB18030')
c=list(data.columns)
for col in range(2,14):
d=data.loc[data.index>'2010-01-01',c[col]].rename(file[0:9])
if d.dtype=='O':
d[d=='None']=0
d=d.astype('float64')
result[col-2]=pd.concat([result[col-2],d],axis=1)
print(file)
except:
print(file,'error')
for i in range(2,14):#输出成csv
result[i-2].to_csv(self.path+'matrix\\'+self.factor[i-2]+'.csv',encoding='GB18030')
print(i-2, result[i-2])
return 0
#输出股价后复权数据(以2010年第一个交易日为起点后复权)
def gen_houfuquan(self):
result=pd.DataFrame()
file_list=os.listdir(self.path+'trading')
for file in file_list:
data=pd.read_csv(self.path+'trading\\'+file,index_col=0,encoding='GB18030').sort_index(ascending=True)
data=data[data.index>'2010-01-01']
price=(data['涨跌幅'].rename(file[0:9]))
price[price=='None' ]=0
price=price.astype('float64')
price=(price/100+1).cumprod()
start_price=data.iloc[0,6].astype('float64')
price=price*start_price
result=pd.concat([result,price])
print(file)
result.to_csv(self.path+'matrix\\close_houfuquan.csv',encoding='GB18030')
return 0
#前复权,以最近一个交易日为起点前复权
def qianfuquan(self):
result=pd.DataFrame()
file_list=os.listdir(self.path+'shares')
for file in file_list:
data=pd.read_csv(self.path+'shares\\'+file,index_col=0,encoding='GB18030').sort_index(ascending=True)
data=data[data.index>'2010-01-01']
price=(data['涨跌幅'].rename(file[0:9]))
price[price=='None' ]=0
price=price.astype('float64')
last_ret=price[-1]/100+1
price=(price/100+1).cumprod()
start_price=(data.iloc[-1,6].astype('float64')*last_ret)/price[-1]
price=price*start_price
result=pd.concat([result,price])
print(file)
result.to_csv(self.path+'matrix\\close_qianfuquan.csv',encoding='GB18030')
return 0 最输出是以下的形式: