Iris鸢尾花卉数据集算法练习——PCA和K近邻分类器
本文章主要以sklearn中的Iris鸢尾花数据集为训练对象,练习了PCA和K-近邻算法的使用,以下为笔记内容:
Iris数据集也叫安德森鸢尾花卉数据集,通过测量了三种不同花卉(山鸢尾、变色鸢尾和维吉尼亚鸢尾)的萼片及花瓣的长、宽度得到该数据集,如下:
from sklearn import datasets
iris = datasets.load_iris()
iris.data
Out[1]:
array([[5.1, 3.5, 1.4, 0.2],
[4.9, 3. , 1.4, 0.2],
[4.7, 3.2, 1.3, 0.2],
[4.6, 3.1, 1.5, 0.2],
···················· # 数据集是包含150个元素的数组,每个元素包含4个数值,分别表示萼片的长度、宽度和花瓣的长度、宽度。iris.target
Out[2]:
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]) # 数据集包含三种花卉,分别用0,1,2表示
1、主成分分解PCA
任务:观察四个维度对花卉种类的影响
问题:四维空间图像无法展示
解决方案:利用主成分分解进行降维,将花卉的四个维度降至三个维度,利用3D散点图展示主成分对花卉种类的影响。
tip:主成分分析法(Principal Component Analysis)—— 从所有维度中提取出足以描述各数据点特征的新维度,该新维度称为主成分,该方法常用于数据降维。
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn import datasets
from mpl_toolkits.mplot3d import Axes3D
iris = datasets.load_iris()
species = iris.target
# 利用PCA函数降维
x_reduced = PCA(n_components=3).fit_transform(iris.data)
#绘制3D图
fig = plt.figure()
ax = Axes3D(fig)
ax.set_title('Iris Dataset By PCA',size=14)
ax.scatter(x_reduced[:,0],x_reduced[:,1],x_reduced[:,2],c=species)
ax.set_xlabel('First eigenvector')
ax.set_ylabel('Secnd eigenvector')
ax.set_zlabel('Third eigenvector')
ax.w_xaxis.set_ticklabels(())
ax.w_yaxis.set_ticklabels(())
ax.w_zaxis.set_ticklabels(())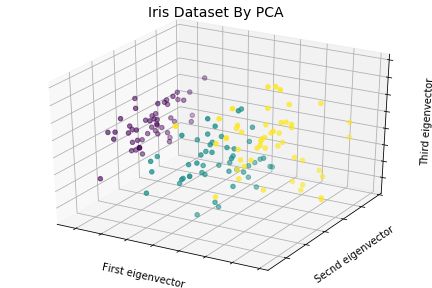
2、K-近邻分类器
任务:给定一种鸢尾花的数据,给这种花卉分类
解决方法:利用最简单的近邻分类器,近邻算法可搜索训练集,找到与测试集数据最相近的数据并予以匹配
import numpy as np
from sklearn import datasets
# 随机数组初始化
np.random.seed(0)
#利用random()函数将iris数据集顺序打乱,因为iris数据集是按照花卉种类顺序采集的
iris = datasets.load_iris()
x = iris.data
y = iris.target
i = np.random.permutation(len(iris.data))
#将数据集中前140条作为训练集,后10条作为测试集
x_train = x[i[:-10]]
y_train = y[i[:-10]]
x_test = x[i[-10:]]
y_test = y[i[-10:]]
# 导入分类器并用fit()函数训练
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
knn.fit(x_train,y_train)用predict()函数调用knn预测模型,并与实际值比较,结果如下,错误率为10%
knn.predict(x_test)
Out[41]: array([1, 2, 1, 0, 0, 0, 2, 1, 2, 0])
y_test
Out[42]: array([1, 1, 1, 0, 0, 0, 2, 1, 2, 0])3、决策边界
此外,还可以利用K-近邻分类分别以萼片的长、宽和花瓣的长、宽为轴画出相应的决策边界。以萼片长宽为轴的决策边界如下:
(若以花瓣的长宽为轴,除了x = iris.data[:,2:4] 外,其他代码相同)
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
iris = datasets.load_iris()
x = iris.data[:,:2] #表示萼片的长度和宽度
y = iris.target #表示花卉种类
x_min, x_max = x[:,0].min() - .5, x[:,0].max()+ .5
y_min, y_max = x[:,1].min() - .5, x[:,1].max()+ .5
# 绘制网格图
cmap_light = ListedColormap(['#AAAAFF','#AAFFAA','#FFAAAA'])
h = 0.02
xx, yy = np.meshgrid(np.arange(x_min,x_max,h),np.arange(y_min,y_max,h))
knn = KNeighborsClassifier()
knn.fit(x,y)
Z = knn.predict(np.c_[xx.ravel(),yy.ravel()])
Z = Z.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx,yy,Z,cmap=cmap_light)
#画出训练点
plt.scatter(x[:,0],x[:,1],c=y)
plt.xlim(xx.min(),xx.max())
plt.ylim(yy.min(),yy.max())
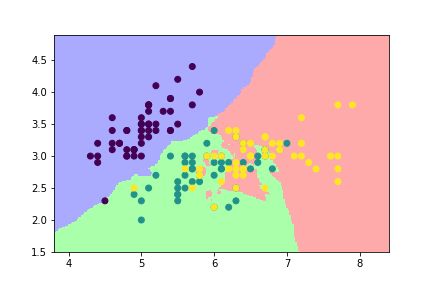
以萼片数据为轴的决策边界图
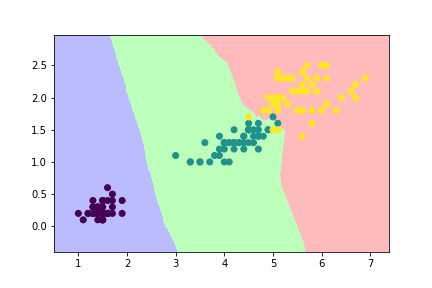
以花瓣为轴的决策边界图