机器学习算法笔记Ⅳ——主成分分析原理及应用
文章目录
- PCA 算法简介
- 相关矩阵原理
- 特征值与特征向量
- 正定矩阵与正交向量
- PCA 原理推导
- 函数求解
- PCA 算法流程
- PCA matlab计算
- PCA 实现鸢尾花分类
- PCA 数据降维处理
- KNN实现分类效果
- 总结
PCA 算法简介
主成分分析(英语:Principal components analysis,PCA)是在不损失或者不很损失原始数据信息的情况下将一个多维数据进行降维处理,其中降维有两个目的:
◆减少输入信息,突出特征信息,提高运算效率
◆在一定程度上能消除数据中的冗余信息,增强数据的鲁棒性
解释一:
主成分分析是一种统计方法,通过正交变换将一组可能存在相关性的变量转换成一组线性不相关的变量,达到压缩的目的。【解释来源MOOC】
解释二
主成分分析可以看成一种坐标变换,在原始的坐标基上数据与数据之间存在一定相关性,通过主成分分析,将这些数据映射在一个新的坐标系中(即变换出一种新的正交基,新的正交基的维度往往小于原始坐标系中的正交基,因此在新的坐标系中能达到降维的目的),在新的坐标系中数据与数据之间线性无关。通过数据之间的无关性便能更好的进行分类,例如下图中,原始坐标系为二维笛卡尔坐标系,正交基为 i → \overrightarrow i i、 j → \overrightarrow j j即传统的 x x x、 y y y轴的单位向量,而新的坐标系为单个轴(可以看为数轴),其正交基只有一个即 e → \overrightarrow e e。【解释来源我自己】



举个栗子:在学生的考试中,往往有很多门功课的成绩。最简单的比较成绩好坏的方式就是算总分并进行排名。因此这就是一种最常见的降维方式,将多门功课的成绩降为一个总分成绩。但是,通过降维后的数据也有一个特点就是不能知晓原始信息之间的关系,比如看到一份总成绩的排名名单我们是无法推敲其各科成绩的。当然这里对降维算法的描述并不是特别准确和科学,具体的理解应在后面的原理解析中。这里只是简单介绍一下降维的优点。降维是PCA不可缺少的部分。
相关矩阵原理
特征值与特征向量
一般地,设A为 n n n阶方阵,如果存在数 λ \lambda λ和 n n n维非零向量 α \alpha α,使 A α = λ α A\alpha = \lambda \alpha Aα=λα
则称 λ \lambda λ为方阵A的一个特征值, α \alpha α为方阵A对应于特征值 λ \lambda λ的一个特征向量。
例如:
A = ( 3 − 2 1 0 ) , α 1 = ( 1 1 ) , α 2 = ( 2 1 ) , β = ( − 1 1 ) A =\begin{pmatrix} 3 & -2 \\ 1 & 0 \\ \end{pmatrix} ,\alpha_1=\begin{pmatrix} 1 \\ 1 \\\end{pmatrix},\alpha_2=\begin{pmatrix} 2 \\ 1 \\\end{pmatrix},\beta=\begin{pmatrix} -1 \\ 1 \\\end{pmatrix} A=(31−20),α1=(11),α2=(21),β=(−11)有 A α 1 = ( 3 − 2 1 0 ) ( 1 1 ) = ( 1 1 ) = 1 ( 1 1 ) = 1 α 1 , A\alpha_1=\begin{pmatrix} 3 & -2 \\ 1 & 0 \\ \end{pmatrix}\begin{pmatrix} 1 \\ 1 \\\end{pmatrix}=\begin{pmatrix} 1 \\ 1 \\\end{pmatrix}=1\begin{pmatrix} 1 \\ 1 \\\end{pmatrix}=1\alpha_1, Aα1=(31−20)(11)=(11)=1(11)=1α1, A α 2 = ( 3 − 2 1 0 ) ( 2 1 ) = ( 4 2 ) = 2 ( 2 1 ) = 2 α 2 , A\alpha_2=\begin{pmatrix} 3 & -2 \\ 1 & 0 \\ \end{pmatrix}\begin{pmatrix} 2 \\ 1 \\\end{pmatrix}=\begin{pmatrix} 4 \\ 2\\\end{pmatrix}=2\begin{pmatrix} 2 \\ 1\\\end{pmatrix}=2\alpha_2, Aα2=(31−20)(21)=(42)=2(21)=2α2, A β = ( 3 − 2 1 0 ) ( − 1 1 ) = ( − 5 − 1 ) ≠ λ ( − 1 1 ) ≠ λ β , A\beta=\begin{pmatrix} 3 & -2 \\ 1 & 0 \\ \end{pmatrix}\begin{pmatrix} -1 \\ 1 \\\end{pmatrix}=\begin{pmatrix} -5 \\ -1\\\end{pmatrix}\ne\lambda\begin{pmatrix} -1 \\ 1\\\end{pmatrix}\ne\lambda\beta, Aβ=(31−20)(−11)=(−5−1)=λ(−11)=λβ,
●由定义可知,1和2就是A的两个特征值, α 1 \alpha_1 α1和 α 2 \alpha_2 α2就是A分别对应于特征值1与2的特征向量;而\beta则不是A的特征向量。
●从几何的角度观察可以发现如果 α \alpha α是A的特征向量,那么 A α A\alpha Aα相当于对 α \alpha α做一定的“伸缩变换”。

正定矩阵与正交向量
定义1:如果任一非零实向量X,都使得二次型 f ( X ) = X T A X > 0 f(X)=X^TAX>0 f(X)=XTAX>0,则称 f ( X ) f(X) f(X)为正定二次型, f ( X ) f(X) f(X)的矩阵A为正定矩阵,其中还有以下延申:
如果 f ( X ) = X T A X < 0 f(X)=X^TAX<0 f(X)=XTAX<0,则称 f ( X ) f(X) f(X)是负定二次型;
如果 f ( X ) = X T A X ≥ 0 f(X)=X^TAX\ge0 f(X)=XTAX≥0,则称 f ( X ) f(X) f(X)是半正定二次型;
如果 f ( X ) = X T A X ≤ 0 f(X)=X^TAX\le0 f(X)=XTAX≤0,则称 f ( X ) f(X) f(X)是半负定二次型;
不是正定,半负定,负定,半负定的二次型统称为不定二次型。
推论1:如果A为正定矩阵,那么其特征值全部为正数,如果A为非负定矩阵即A为正定矩阵或半正定矩阵,其特征值全部非负。同理,如果如果A为非正定矩阵即A为负定矩阵或半负定矩阵,其特征值全部非正。
两个向量正交,则两个向量的乘积为零向量
PCA 原理推导
设 X 1 , X 2 , . . . X M X_1,X_2,...X_M X1,X2,...XM为训练样本,每个为 N N N维。寻找一个 ❓ × N ❓×N ❓×N维的矩阵 A A A,使 Y = A ( X − X ‾ ) Y=A(X-\overline X) Y=A(X−X),将 X X X的维度由 N N N降到❓维,❓是自己设定的维度,其值要小于 M M M。
PCA要求:
① A = ( a 1 a 2 . . . a M ) A =\begin{pmatrix} a_1 \\ a_2 \\ ...\\ a_M \end{pmatrix} A=⎝⎜⎜⎛a1a2...aM⎠⎟⎟⎞,其中 a i a_i ai为 1 × N 1×N 1×N维。
② a i a j T = { 0 i ≠ j 1 i = j a_i{a_j}^T=\left\{ \begin{array}{rcl} 0 & & {i \ne j}\\ 1 & & {i=j} \end{array} \right. aiajT={01i=ji=j,即满足正交性。
③方差最大。寻找 a 1 a_1 a1,使 ∑ i = 1 p ∣ ∣ a 1 ( x i − x ‾ ) ∣ ∣ 2 \sum\nolimits_{i = 1}^p {||{a_1}({x_i} - \overline x )|{|^2}} ∑i=1p∣∣a1(xi−x)∣∣2最大。即 m a x m i z e maxmize maxmize ∑ i = 1 p ∣ ∣ a 1 ( x i − x ‾ ) ∣ ∣ 2 \sum\nolimits_{i = 1}^p {||{a_1}({x_i} - \overline x )|{|^2}} ∑i=1p∣∣a1(xi−x)∣∣2,下面讨论如何最大化目标函数 ∑ i = 1 p ∣ ∣ a 1 ( x i − x ‾ ) ∣ ∣ 2 \sum\nolimits_{i = 1}^p {||{a_1}({x_i} - \overline x )|{|^2}} ∑i=1p∣∣a1(xi−x)∣∣2。
函数求解
Ⅰ、 a 1 a_1 a1求解
∑ i = 1 p ∣ ∣ a 1 ( x i − x ‾ ) ∣ ∣ 2 = ∑ i = 1 p a 1 ( x i − x ‾ ) ( x i − x ‾ ) T a 1 T = a 1 ∑ a 1 T \sum\nolimits_{i = 1}^p {||{a_1}({x_i} - \overline x )|{|^2}}=\sum\limits_{i = 1}^p {{a_1}({x_i} - \overline x ){{({x_i} - \overline x )}^T}} a_1^T={a_1}\sum {a_1^T} ∑i=1p∣∣a1(xi−x)∣∣2=i=1∑pa1(xi−x)(xi−x)Ta1T=a1∑a1T,其中 ∑ = ∑ i = 1 p ( x i − x ‾ ) ( x i − x ‾ ) T \sum=\sum\nolimits_{i = 1}^p {({x_i} - \overline x )({x_i} - \overline x )^T} ∑=∑i=1p(xi−x)(xi−x)T为协方差矩阵,其中约束条件为 a 1 a 1 T = 1 a_1{a_1}^T=1 a1a1T=1,因此我们采用拉格朗日乘数法。构造如下:
o b j e c t = { E ( a 1 ) = a 1 ∑ a 1 T − λ ( a 1 a 1 T − 1 ) = m i n v a l u e ① ∂ E ∂ a 1 = ∑ a 1 T − λ a 1 T = 0 ② ∂ E ∂ a 1 T = ∑ a 1 − λ a 1 = 0 ③ ∂ E ∂ λ = 1 − a 1 a 1 T = 0 ④ object=\left\{ \begin{aligned} E(a_1)&=&{a_1}\sum {a_1^T}-\lambda(a_1{a_1}^T-1)&=&minvalue & &①\\ \frac{{\partial E}}{{\partial {a_1}}} &= &\sum {a_1^T}-{\lambda a_1}^T&=&0 & &②\\ \frac{{\partial E}}{{\partial {a_1^T}}} &= &\sum {a_1}-{\lambda a_1}&=&0 & &③\\ \frac{{\partial E}}{{\partial {\lambda}}}& = &1-a_1a_1^T&=&0 & &④ \end{aligned} \right. object=⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧E(a1)∂a1∂E∂a1T∂E∂λ∂E====a1∑a1T−λ(a1a1T−1)∑a1T−λa1T∑a1−λa11−a1a1T====minvalue000①②③④
易知④成立,由① ∂ E ∂ a 1 = ∑ a 1 T − λ a 1 T = 0 \frac{{\partial E}}{{\partial {a_1}}} = \sum {a_1^T}-{\lambda a_1}^T=0 ∂a1∂E=∑a1T−λa1T=0可得 ∑ a 1 T = λ a 1 T \sum {a_1^T}=\lambda a_1^T ∑a1T=λa1T即有 a 1 ∑ a 1 T = a 1 ( λ a 1 T ) = λ a 1 a 1 T = λ {a_1}\sum {a_1^T}=a_1(\lambda a_1^T)=\lambda a_1a_1^T=\lambda a1∑a1T=a1(λa1T)=λa1a1T=λ因此, λ \lambda λ为最大的特征值, a 1 T {a_1^T} a1T为最大特征值对应的特征向量。
Ⅰ、 a 2 a_2 a2求解
与 a 1 a_1 a1求解不同的是 a 2 a_2 a2求解具有两个约束条件: a 2 a 2 T = 1 a_2{a_2}^T=1 a2a2T=1、 a 2 a 1 T = 0 a_2{a_1}^T=0 a2a1T=0
构造如下:
o b j e c t = { E ( a 2 ) = a 2 ∑ a 2 T − λ ( a 2 a 2 T − 1 ) − β a 2 a 1 T = m i n v a l u e ① ∂ E ∂ a 2 = ∑ a 2 T − λ a 2 T − β a 1 T = 0 ② ∂ E ∂ a 2 T = ∑ a 2 − λ a 2 = 0 ③ ∂ E ∂ a 1 T = − β a 2 = 0 ④ ∂ E ∂ λ = 1 − a 2 a 2 T = 0 ⑤ ∂ E ∂ β = − a 2 a 1 T = 0 ⑥ object=\left\{ \begin{aligned} E(a_2)&=&{a_2}\sum {a_2^T}-\lambda(a_2{a_2}^T-1) - \beta a_2a_1^T&=&minvalue & &①\\ \frac{{\partial E}}{{\partial {a_2}}} &= &\sum {a_2^T}-{\lambda a_2}^T - \beta a_1^T&=&0 & &②\\ \frac{{\partial E}}{{\partial {a_2^T}}}& =& \sum {a_2}-{\lambda a_2}&=&0 & &③\\ \frac{{\partial E}}{{\partial {a_1^T}}} &=& -\beta a_2 &=&0 & &④\\ \frac{{\partial E}}{{\partial {\lambda}}} &=& 1-a_2a_2^T&=&0 & &⑤\\ \frac{{\partial E}}{{\partial {\beta}}} &=& -a_2a_1^T&=&0 & &⑥ \end{aligned} \right. object=⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧E(a2)∂a2∂E∂a2T∂E∂a1T∂E∂λ∂E∂β∂E======a2∑a2T−λ(a2a2T−1)−βa2a1T∑a2T−λa2T−βa1T∑a2−λa2−βa21−a2a2T−a2a1T======minvalue00000①②③④⑤⑥
易知⑤,⑥成立,由④ ∂ E ∂ a 1 T = − β a 2 = 0 \frac{{\partial E}}{{\partial {a_1^T}}} = -\beta a_2 =0 ∂a1T∂E=−βa2=0又 a 2 a_2 a2为矩阵A的一个向量,A为满秩矩阵,因此 a 2 a_2 a2明显不为零,所以 β = 0 \beta=0 β=0。又由③ ∂ E ∂ a 2 T = ∑ a 2 − λ a 2 = 0 \frac{{\partial E}}{{\partial {a_2^T}}} = \sum {a_2}-{\lambda a_2}=0 ∂a2T∂E=∑a2−λa2=0可推出 λ \lambda λ为 ∑ \sum ∑的第二大特征值, a 2 T {a_2^T} a2T为第二大特征值对应的特征向量。
Ⅰ、 a i a_i ai求解
由上述两种方式,我们可以以此解得, a i a_i ai为 ∑ \sum ∑的第 i i i大特征值, a i T {a_i^T} aiT为第 i i i大特征值对应的特征向量。因此我们可知矩阵A是由协方差矩阵 ∑ \sum ∑的特征向量组成,其所包含的特征向量的个数极为我们所需要降到的维度值。
PCA 算法流程
一、对于输入的 N N N维向量 X 1 、 X 2 、 X 3 . . . 、 X p X_1、X_2、X_3...、X_p X1、X2、X3...、Xp,求协方差矩阵 ∑ = ∑ i = 1 p ( x i − x ‾ ) ( x i − x ‾ ) T \sum=\sum\limits_{i = 1}^p {({x_i} - \overline x ){{({x_i} - \overline x )}^T}} ∑=i=1∑p(xi−x)(xi−x)T
二、求 ∑ \sum ∑的特征值和特征向量,按照从特征值从大到小分别是(我们假定所降至维度为 M M M维) λ 1 、 λ 2 、 λ 3 . . . 、 λ M 、 \lambda_1、\lambda_2、\lambda_3...、\lambda_M、 λ1、λ2、λ3...、λM、由于协方差矩阵是半正定矩阵,它的特征值都是非负的,因此它们对应的特征向量分别为 a 1 T 、 a 2 T 、 a 3 T . . . 、 a M T {a_1^T}、{a_2^T}、{a_3^T}...、{a_M^T} a1T、a2T、a3T...、aMT
三、设 A = ( a 1 a 2 . . . a M ) A =\begin{pmatrix} a_1 \\ a_2 \\ ...\\ a_M \end{pmatrix} A=⎝⎜⎜⎛a1a2...aM⎠⎟⎟⎞,它是一个 M × N M×N M×N维矩阵。 Y i = A ( X i − X ‾ ) Y_i=A(X_i-\overline X) Yi=A(Xi−X),即 X ‾ = 1 p ∑ i = 1 p X i \overline X=\frac{{1}}{{p}}\sum\nolimits_{i = 1}^p X_i X=p1∑i=1pXi,这样即将 N N N维向量 X i X_i Xi变为 M M M维向量 Y i ( M < N ) Y_i(M
附:
①在周志华主编的机器学习书中对PCA算法流程描述如下:

②降维后是不能知晓降维后的数据与原始数据之间的关系,并且有一定的数据损失,因此定义了主成分的贡献率,定义式如下:
{ λ k ∑ i = 1 n λ i 第 k 个 主 成 分 的 贡 献 率 ∑ i = 1 r λ i ∑ i = 1 n λ i 前 r 个 主 成 分 的 贡 献 率 \left\{ \begin{aligned} \frac{{{\lambda _k}}}{{\sum\limits_{i = 1}^n {{\lambda _i}} }} & &第k个主成分的贡献率\\ \\ \frac{{\sum\limits_{i = 1}^r {{\lambda _i}} }}{{\sum\limits_{i = 1}^n {{\lambda _i}} }} & &前r个主成分的贡献率\\ \end{aligned} \right. ⎩⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎧i=1∑nλiλki=1∑nλii=1∑rλi第k个主成分的贡献率前r个主成分的贡献率
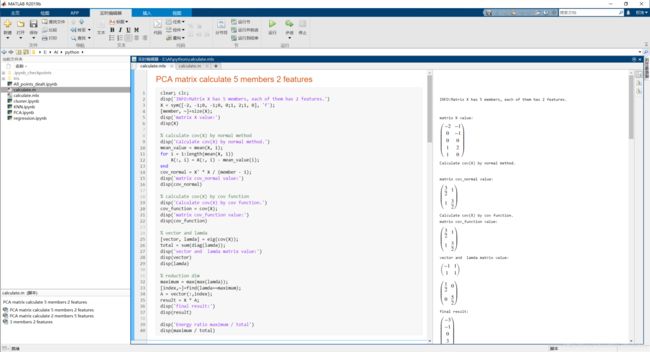
PCA matlab计算
本次对单个矩阵得PCA计算采用版本为MATLABR2019b(9.7.01190202),MATLAB对于矩阵中向量的排列规则是,一行代表一个成员,每一行内的值则是成员的值。在所给出的代码文件中,不仅用MATLAB自带的函数写了PCA算法,还严格按照PCA的算法流程用基本MATLAB语法完成PCA算法,两者输出的值是相同的。MATLAB代码如下:
%% PCA matrix calculate 5 members 2 features
clear; clc;
disp('INFO:Matrix X has 5 members, each of them has 2 features.')
X = sym([-2, -1;0, -1;0, 0;1, 2;1, 0], 'f');
[member, ~]=size(X);
disp('matrix X value:')
disp(X)
% calculate cov(X) by normal method
disp('Calculate cov(X) by normal method.')
mean_value = mean(X, 1);
for i = 1:length(mean(X, 1))
X(:, i) = X(:, i) - mean_value(i);
end
cov_normal = X' * X / (member - 1);
disp('matrix cov_normal value:')
disp(cov_normal)
% calculate cov(X) by cov function
disp('Calculate cov(X) by cov function.')
cov_function = cov(X);
disp('matrix cov_function value:')
disp(cov_function)
% vector and lamda
[vector, lamda] = eig(cov(X));
total = sum(diag(lamda));
disp('vector and lamda matrix value:')
disp(vector)
disp(lamda)
% reduction dim
maximum = max(max(lamda));
[index,~]=find(lamda==maximum);
A = vector(:,index);
result = X * A;
disp('final result:')
disp(result)
disp('Energy ratio maximum / total')
disp(maximum / total)
%% PCA matrix calculate 2 members 5 features
clear; clc;
disp('INFO:Matrix X has 2 members, each of them has 5 features.')
X = sym([-2,0,0,1,1;-1,-1,0,2,0], 'f');
[member, ~]=size(X);
disp('matrix X value:')
disp(X)
% calculate cov(X) by normal method
disp('Calculate cov(X) by normal method.')
mean_value = mean(X, 1);
for i = 1:length(mean(X, 1))
X(:, i) = X(:, i) - mean_value(i);
end
cov_normal = X' * X / (member - 1);
disp('matrix cov_normal value:')
disp(cov_normal)
% calculate cov(X) by cov function
disp('Calculate cov(X) by cov function.')
cov_function = cov(X);
disp('matrix cov_function value:')
disp(cov_function)
% vector and lamda
[vector, lamda] = eig(cov(X));
disp('vector and lamda matrix value:')
disp(vector)
disp(lamda)
% reduction dim
maximum = max(max(lamda));
[index,~]=find(lamda==maximum);
A = vector(:,index);
result = X * A;
disp('final result:')
disp(result)
%% 3 members 2 features
clear; clc;
disp('INFO:Matrix X has 3 members, each of them has 2 features.')
X = sym([1, 4;2, 5;3, 6], 'f');
[member, ~]=size(X);
disp('matrix X value:')
disp(X)
% calculate cov(X) by normal method
disp('Calculate cov(X) by normal method.')
mean_value = mean(X, 1);
for i = 1:length(mean(X, 1))
X(:, i) = X(:, i) - mean_value(i);
end
cov_normal = X' * X / (member - 1);
disp('matrix cov_normal value:')
disp(cov_normal)
% calculate cov(X) by cov function
disp('Calculate cov(X) by cov function.')
cov_function = cov(X);
disp('matrix cov_function value:')
disp(cov_function)
% vector and lamda
[vector, lamda] = eig(cov(X));
disp('vector and lamda matrix value:')
disp(vector)
disp(lamda)
% reduction dim
maximum = max(max(lamda));
[index,~]=find(lamda==maximum);
A = vector(:,index);
result = X * A;
disp('final result:')
disp(result)
在此版本中可以将MATLAB代码转换成实时运行脚本文件,并且可以观察打印输出,具体的输出可自行运行代码文件。截图如下:
PCA 实现鸢尾花分类
PCA 数据降维处理
导入必要的包
import pandas as pd
import numpy as np
from sklearn.decomposition import PCA
from factor_analyzer import FactorAnalyzer
import matplotlib.pyplot as plt
数据处理
def datafram_dealt(data):
df_data = pd.read_csv(data)
df = df_data.drop(['Unnamed: 0'], axis=1)
class_name = list(df['Species'].drop_duplicates())
df['Species'] = df['Species'].map({class_name[0]:0, class_name[1]:1, class_name[2]:2}).astype(int)
df = df.sample(frac=1)
dick_map = {class_name[0]:0, class_name[1]:1, class_name[2]:2}
return df, dick_map
df, dick_map = datafram_dealt('Iris/iris.csv')
df
| Sepal.Length | Sepal.Width | Petal.Length | Petal.Width | Species | |
|---|---|---|---|---|---|
| 108 | 6.7 | 2.5 | 5.8 | 1.8 | 2 |
| 93 | 5.0 | 2.3 | 3.3 | 1.0 | 1 |
| 5 | 5.4 | 3.9 | 1.7 | 0.4 | 0 |
| 33 | 5.5 | 4.2 | 1.4 | 0.2 | 0 |
| 95 | 5.7 | 3.0 | 4.2 | 1.2 | 1 |
| ... | ... | ... | ... | ... | ... |
| 109 | 7.2 | 3.6 | 6.1 | 2.5 | 2 |
| 9 | 4.9 | 3.1 | 1.5 | 0.1 | 0 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | 0 |
| 86 | 6.7 | 3.1 | 4.7 | 1.5 | 1 |
| 35 | 5.0 | 3.2 | 1.2 | 0.2 | 0 |
150 rows × 5 columns
dick_map
{'setosa': 0, 'versicolor': 1, 'virginica': 2}
获取训练集
train_x = df.iloc[0:120, 0:4]
train_y = df.iloc[0:120, 4]
降维为四个维度,以便查看原始维度中贡献最大的成分,可以发现四个维度贡献分别为0.92011969, 0.05660178, 0.01812305, 0.00515547
model = PCA(n_components=4)
model.fit(train_x)
PCA(copy=True, iterated_power='auto', n_components=4, random_state=None,
svd_solver='auto', tol=0.0, whiten=False)
model.explained_variance_ratio_
array([0.92096378, 0.05528745, 0.01805879, 0.00568998])
降维为三个维度,在三维坐标系绘图可视化
model = PCA(n_components=3)
model.fit(train_x)
model.explained_variance_ratio_, model.explained_variance_
(array([0.92096378, 0.05528745, 0.01805879]),
array([4.13008788, 0.24793812, 0.08098514]))
train_x_2D = model.transform(train_x)
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(train_x_2D[:, 0], train_x_2D[:, 1], train_x_2D[:, 2], c=train_y)
plt.show()

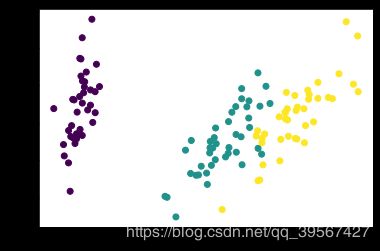
降维为两个维度,在二维坐标系可视化
model = PCA(n_components=2)
model.fit(train_x)
model.explained_variance_ratio_, model.explained_variance_
(array([0.92096378, 0.05528745]), array([4.13008788, 0.24793812]))
train_x_2D = model.transform(train_x)
plt.scatter(train_x_2D[:, 0], train_x_2D[:, 1], c=train_y)
plt.show()
自定义保留95%成分,计算机自动计算保留维度,从前面四个维度不难看出,两个维度则占比超过95%,与预期结果相符合
model = PCA(n_components=0.95)
model.fit(train_x)
model.explained_variance_ratio_, model.n_components_
(array([0.92096378, 0.05528745]), 2)
利用mle参数让计算机自动计算保留的维度,结果为三个维度,其成分保留约为99.5%
model = PCA(n_components='mle')
model.fit(train_x)
model.explained_variance_ratio_, model.n_components_
(array([0.92096378, 0.05528745, 0.01805879]), 3)
sum(model.explained_variance_ratio_)
0.9943100204228477
利用因子分析实现组间方差极大化,将数据分隔更开,以三维为例
model = FactorAnalyzer(n_factors=3, rotation='promax')
model.fit(train_x)
model.loadings_
array([[ 1.06466005, 0.07180062, -0.08841903],
[ 0.00898918, 0.77820767, 0.03874046],
[ 0.70969381, -0.19615596, 0.26522617],
[ 0.50775203, 0.0731516 , 0.63305601]])
train_x_2D = model.transform(train_x)
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(train_x_2D[:, 0], train_x_2D[:, 1], train_x_2D[:, 2], c=train_y)
plt.show()

利用因子分析实现组间方差极大化,将数据分隔更开,以二维为例
model = FactorAnalyzer(n_factors=2, rotation='promax')
model.fit(train_x)
model.loadings_
array([[ 0.93854453, 0.16348874],
[ 0.0110667 , 1.00086531],
[ 0.95945583, -0.12708808],
[ 0.92380573, -0.07361529]])
train_x_2D = model.transform(train_x)
plt.scatter(train_x_2D[:, 0], train_x_2D[:, 1], c=train_y)
plt.show()
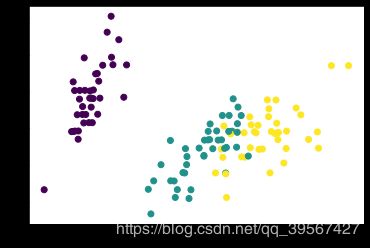
KNN实现分类效果
导入必要的包
from sklearn import neighbors
模型建立,利用上一步中最后处理完成的二维数据
model_KNN = neighbors.KNeighborsClassifier()
model_KNN.fit(train_x_2D, train_y)
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=5, p=2,
weights='uniform')
test_x = model.transform(df.iloc[120:150, 0:4])
test_p = model_KNN.predict(test_x)
test_y = df.iloc[120:150, 4].values
print('predict value:', test_p,
'\nlabel value :', test_y)
predict value: [1 0 0 1 2 0 1 2 1 0 2 0 1 2 0 1 1 0 2 2 1 0 0 1 1 2 0 0 1 0]
label value : [1 0 0 1 2 0 2 2 2 0 2 0 1 2 0 1 1 0 2 1 2 0 0 1 2 2 0 0 1 0]
查看准确率
model_KNN.score(test_x, test_y)
0.8333333333333334
总结
PCA算法能够降低维度,减少数据,其作用与卷积操作类似。最后将处理完成的数据用于神经网路以及传统机器学习算法例如KNN等,都能取得较好的效果