天池比赛实践——阿里云安全恶意程序检测(基于机器学习算法XGBoost)
比赛链接:https://tianchi.aliyun.com/competition/entrance/231694/introduction?spm=5176.12281949.1003.10.72ad76d8Azb5Xq
赛题背景
恶意软件是一种被设计用来对目标计算机造成破坏或者占用目标计算机资源的软件,传统的恶意软件包括蠕虫、木马等,这些恶意软件严重侵犯用户合法权益,甚至将为用户及他人带来巨大的经济或其他形式的利益损失。近年来随着虚拟货币进入大众视野,挖矿类的恶意程序也开始大量涌现,黑客通过入侵恶意挖矿程序获取巨额收益。当前恶意软件的检测技术主要有特征码检测、行为检测和启发式检测等,配合使用机器学习可以在一定程度上提高泛化能力,提升恶意样本的识别率。
赛题说明
本题目提供的数据来自文件(windows 可执行程序)经过沙箱程序模拟运行后的API指令序列,全为windows二进制可执行程序,经过脱敏处理。
本题目提供的样本数据均来自于从互联网。其中恶意文件的类型有感染型病毒、木马程序、挖矿程序、DDOS木马、勒索病毒等,数据总计6亿条。
数据说明
1)训练数据(train.zip):调用记录近9000万次,文件1万多个(以文件编号汇总),字段描述如下:

注1:一个文件调用的api数量有可能很多,对于一个tid中调用超过5000个api的文件,我们进行了截断,按照顺序保留了每个tid前5000个api的记录。
注2:不同线程tid之间没有顺序关系,同一个tid里的index由小到大代表调用的先后顺序关系。
注3:index是单个文件在沙箱执行时的全局顺序,由于沙箱执行时间有精度限制,所以会出现一个index上出现同线程或者不同线程都在执行多次api的情况,可以保证同tid内部的顺序,但不保证连续。
2)测试数据(test.zip):调用记录近8000万次,文件1万多个。
说明:格式除了没有label字段,其他数据规格与训练数据一致。
评测指标
1.选手的结果文件包含9个字段:file_id(bigint)、和八个分类的预测概率prob0, prob1, prob2, prob3, prob4, prob5 ,prob6,prob7 (类型double,范围在[0,1]之间,精度保留小数点后5位,prob<=0.0我们会替换为1e-6,prob>=1.0我们会替换为1.0-1e-6)。选手必须保证每一行的|prob0+prob1+prob2+prob3+prob4+prob5+prob6+prob7-1.0|<1e-6,且将列名按如下顺序写入提交结果文件的第一行,作为表头:file_id,prob0,prob1,prob2,prob3,prob4,prob5,prob6,prob7。
2.分数采用logloss计算公式如下:
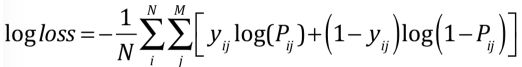
M代表分类数,N代表测试集样本数,yij代表第i个样本是否为类别j(是1,否0),Pij代表选手提交的第i个样本被预测为类别j的概率(prob),最终公布的logloss保留小数点后6位。
解题思路:参考文章https://xz.aliyun.com/t/3704#toc-0(有改动)
具体步骤:
(1)数据预处理:
1.1)CSV数据集数据量太大,无法一次性纳入内存,通过pandas对象的iterator选项以及get_chunk实现分批次读入内存,最后将数据集concat起来
import pandas as pd
import time
path1 ='C:/Users/Administrator/Desktop/天池比赛实践/阿里云安全恶意程序检测/security_train.csv'
path2 ='C:/Users/Administrator/Desktop/天池比赛实践/阿里云安全恶意程序检测/security_test.csv'
# iterator=True,得到一个迭代器,还有一个nrows指定读取的数目,还有一个chunksize每一次读多少.
# 文件预处理
def FileChunker(path):
temp=pd.read_csv(path,engine='python',iterator=True)
loop=True
chunkSize = 10000
chunks = []
while loop:
try:
chunk = temp.get_chunk(chunkSize)
chunks.append(chunk)
except StopIteration:
loop = False
print("Iteration is stopped.")
data = pd.concat(chunks, ignore_index= True,axis=0)
return data
1.2)把每个样本根据file_id进行分组,对每个分组把多个线程内部的API CALL调用序列排好,再把每个线程排好后的序列拼接成一个超长的字符串
def read_train_file(path):
labels = []
files = []
data=FileChunker(path)
#for data in data1:
goup_fileid = data.groupby('file_id') # 不同的文件file_id
for file_name, file_group in goup_fileid:
#print(file_name)
file_labels = file_group['label'].values[0] # 获取label
result = file_group.sort_values(['tid', 'index'], ascending=True) # 根据线程和顺序排列
api_sequence = ' '.join(result['api'])
labels.append(file_labels)
files.append(api_sequence)
#print(labels)
#print(files)
with open(path.split('/')[-1] + ".txt", 'a+') as f:
for i in range(len(labels)):
f.write(str(labels[i]) + ' ' + files[i] + '\n')
read_train_file(path1)
1.3)label和超长文本特征的转化为PKL文件,方便读入
import pandas as pd
import numpy as np
import pickle
path1="C:/Users/Liuwj/Desktop/天池比赛实践/阿里云安全恶意程序检测/security_train.txt"
def load_train2h5py(path):
labels = []
files = []
with open(path) as f:
for i in f.readlines():
i = i.strip('\n')
labels.append(i[0])
files.append(i[1:])
labels = np.asarray(labels)
with open("security_train.pkl", 'wb') as f:
pickle.dump(labels, f)
pickle.dump(files, f)
load_train2h5py(path1)
(2)利用sklearn中的TfidfTransformer统计文本中每个单词或相连词语(n-gram)的tf-idf权值,以评估词对于一个文档集或一个语料库中的其中一个文档的重要程度:

这里选择3-gram,且忽略低于0.1,高于0.8的文档频率的词条,最后选择高斯映射实现降维,因为传统的机器学习方法XGBoost在高维稀疏的数据集上表现不如神经网络。
import pickle
from sklearn.feature_extraction.text import TfidfVectorizer
import time
import numpy as np
from sklearn.decomposition import PCA
from sklearn.random_projection import GaussianRandomProjection
from sklearn.random_projection import SparseRandomProjection
from sklearn import manifold
start = time.clock()
with open("security_train.pkl", "rb") as f: # 加载PKL文件,训练数据
labels = pickle.load(f)
files = pickle.load(f)
print("start tfidf...")
vectorizer = TfidfVectorizer(ngram_range=(1, 3), min_df=0.100000, max_df=0.800000, ) # tf-idf特征抽取ngram_range=(1,5)
train_features = vectorizer.fit_transform(files) # 将api长序列进行TFIDF,作为样本特征
print(" TFIDF Finish!")
# 降维
#执行映射,我们把维度降为500
print("demension reduction start!")
print("phase 1")
transformer = GaussianRandomProjection(n_components=500)
train_features = transformer.fit_transform(train_features)
#transformer = SparseRandomProjection(n_components=500, random_state=0)
#train_features = transformer.fit_transform(train_features )
#transformer=PCA(n_components=500)
#train_features=transformer.fit(train_features)
print("phase 2")
print("demension reduction start!")
print(train_features.shape) # 打印出转换后的向量形态
with open("tfidf_feature_no_limit.pkl", 'wb') as f: # pickle
pickle.dump(train_features, f)
with open("tfidf_feature_no_limit.pkl", 'rb') as f:
train_features = pickle.load(f)
print(train_features.shape)
print(" PKL Finish!")
end = time.clock()
print("time is:",int(end-start))
(3)XGBoost实现多分类
import pickle
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
import time
import csv
import xgboost as xgb
from sklearn.model_selection import StratifiedKFold
import numpy as np
from sklearn.externals import joblib
start = time.clock()
with open("security_train.pkl", "rb") as f: # 加载PKL文件,训练数据
labels = pickle.load(f)
with open("tfidf_feature_no_limit.pkl", 'rb') as f: # 加载
train_features = pickle.load(f)
print(train_features.shape)
print(labels.shape)
print("File Loading Finish")
# 5-Fold Cross
skf = StratifiedKFold(n_splits=5, random_state=0, shuffle=True)
print("StratifiedKFold Finish ")
for i, (tr_ind, te_ind) in enumerate(skf.split(train_features, labels)): # 迭代训练
X_train, X_train_label = train_features[tr_ind], labels[tr_ind]
X_val, X_val_label = train_features[te_ind], labels[te_ind]
print('FOLD: {}'.format(str(i))) # 训练第几次
print( len(tr_ind),len(te_ind))
# XGB
dtrain = xgb.DMatrix(X_train, label=X_train_label) # XGBoost自定义了一个数据矩阵类DMatrix,优化了存储和运算速度
dtest = xgb.DMatrix(X_val, label=X_val_label)
# dout = xgb.DMatrix(out_features)
## 参数设置
#max_depth: 树的最大深度。缺省值为6,取值范围为:[1,∞]
#eta:为了防止过拟合,更新过程中用到的收缩步长。在每次提升计算之后,算法会直接获得新特征的权重。
#eta通过缩减特征的权重使提升计算过程更加保守。缺省值为0.3,取值范围为:[0,1]
#silent:取0时表示打印出运行时信息,取1时表示以缄默方式运行,不打印运行时信息。缺省值为0
#objective: 定义学习任务及相应的学习目标,“binary:logistic” 表示二分类的逻辑回归问题,输出为概率。
param = {'max_depth': 5, 'eta': 0.1, 'eval_metric': 'mlogloss', 'silent': 1, 'objective': 'multi:softmax','num_class': 8, 'subsample': 0.8,'colsample_bytree': 0.85}
evallist = [(dtrain, 'train'), (dtest, 'val')] # 测试 , (dtrain, 'train')
num_round = 300 # 循环次数
print('XGB begin')
bst = xgb.train(param, dtrain, num_round, evallist, early_stopping_rounds=50)
print("XGB finish")
# dtr = xgb.DMatrix(train_features)????
pred_val = bst.predict(dtest) # 验证集预测错误概率
print ('predicting, classification error=%f' % (sum( int(pred_val[i]) != int(X_val_label[i]) for i in range(len(X_val_label))) /len(X_val_label)))
print("start saving model")
joblib.dump(bst, "train_model.m")
print("done!")
end = time.clock()
print("time is:",int(end- start))
本文仅给出模型调参用到的交叉验证结果,上交文件的代码可参考原作者文章:https://xz.aliyun.com/t/3704#toc-0
本文代码:https://github.com/wait1ess/TianChi
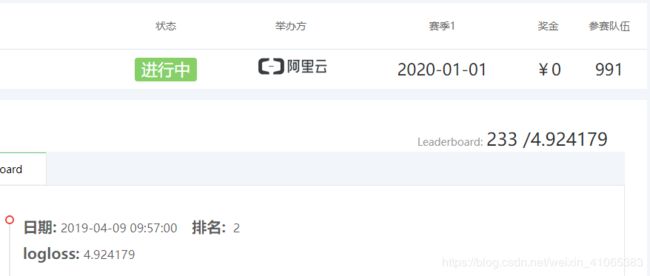
成绩如下(未经调参):