【MySQL学习日志】MySQL基本语句及函数
MySQL基本语句及函数
1.SQL到底是什么?MySQL呢?
SQL(发音为字母 S-Q-L或 sequel)是 Structured Query Language,即结构化查询语言的缩写。SQL是一种专门用来与数据库沟通的语言。
- 以上是在SQL必知必会(第4版)中的解释,可以将其理解为一种特殊的语言 (而不是应用程序) ,它的特点是简单方便,能够快速读写数据库中的数据。熟练掌握SQL,可以帮助我们更好地进行数据库的增删查改等工作。
- MySQL是一个关系型数据库管理系统,是由瑞典MySQL AB公司开发的应用软件,目前属于 Oracle 旗下产品,MySQL 是最流行的关系型数据库管理系统之一。
2.查询语句
select语句的作用是从一个或多个表中检索信息。可以分为以下几种情况(以yiibaidb中的表格customers为例):
1)检索单个列:
select phone from customers;
上图是运行后的结果,共检索出122行数据。
注意:
-
SQL语句不区分大小写,但是在写select语句时,为了便于阅读,可以将关键字大写,列名、表名等小写,更好识别;
-
多条语句时,每条语句之间必须用(;)分隔,所以养成每条语句后都以(;)结尾的习惯;
-
一条 SQL语句可以分行写,也可以写在一行,分行可能更便于阅读。
2)检索多个列
select phone,city
from customers;
注意:
在写多个列名时,要以(,)进行分隔。
3)检索所有列
select *
from customers;

注意:
如果给定一个通配符(*),则会返回所有列的内容。但实际上,返回所有列其实并没有什么意义,也会降低检索性能。
3)检索不同值
select distinct city
from customers;
注意:
经过DISTINCT过滤后,显示95行数据,这是因为筛选掉了相同城市的数据。
4)返回限制结果
select city
from customers
limit 5;
上图是仅显示前5行内容的结果。
注意:
- 要实现这一结果,在不同的DBMS中,需要不同语句来实现。上面是在MySQL中的实现方式。
- 假如需要得到后面的5行数据,LIMIT5指示 MySQL等DBMS返回不超过 5行的数据。为了得到后面的 5行数据,需要指定从哪儿开始以及检索的行数:
select city
from customers
limit 5 offset 5;

- LIMIT 5 OFFSET 5指示 MySQL等 DBMS返回从第 5行起的 5行数据。第一个数字是指检索的行数,第二个数字是从哪儿开始。因为第一个被检索的行是第0行,所以LIMIT 5 OFFSET 5会从第6行开始检索。
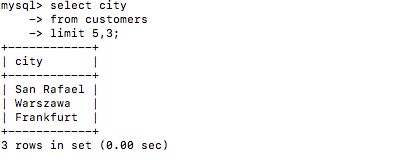
- MySQL还可以使用简化语言:
select city
from customers
limit 5,3;
limit 与后面数字要有空格,否则会报错。
小结1:
在上述检索语句的返回结果中,SQL语句一般返回原始的、无格式的数据。而如果需要将结果进行排序,则要用到下面的排序语句(ORDER RY)。
3.排序语句
order by 语句的所用是将检索出的诗句进行排序。
1)按单列排序
select city
from customers
order by customerNumber;
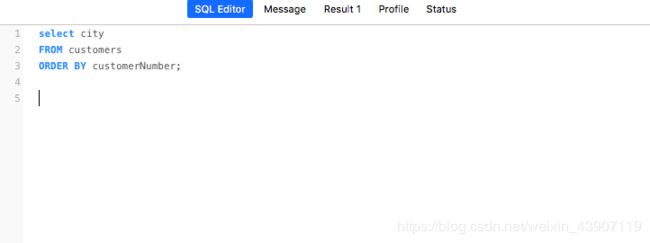
图为在Navicat Premium中的运行情况
注意:
- 在指定一条 ORDER BY子句时,应该保证它是 SELECT语句中最后一条子句。如果它不是最后的子句,将会出现错误消息。
2)按多列排序
select city
from customers
order by customerNumber,city;

注意:
- 在按多个列排序时,排序的顺序先按第一列进行排列,然后在第一列值相同的情况下,才按第二列排。
3)按列位置排序
select city
from customers
order by 2,3;
4)指定排序方向
默认按照升序排列,降序需用DESC语句。
select city
from customers
order by customerNumber desc;

如果想用多列排序:
select city
from customers
order by 1 desc, city;
注意:
- DESC关键字只应用到直接位于其前面的列名。
- 如果想在多个列上进行降序排序,必须对每一列指定DESC关键字。
小结2:
利用order by语句可以按照单列、多列进行排序,也可以按照列位置、升序(默认)、降序进行排列。
4.过滤语句
1)检查单个值
通过where语句设立检索条件,对返回条件进行过滤。
select city
from customers
where phone=‘40.32.2555’;
注意:
语句中的数字要加引号,否则会报错。这是因为将值与数值列进行比较时不用引号,而与字符串列进行比较时则需要加引号。
同样,除了相等条件,还可以使用!=,<=,>=等操作符进行筛选。
2)检查范围值

3)检查空值

4)组合过滤语句
- AND操作符

- or操作符

注意:
SQL(像 多数语言一样)在处理OR操作符前,优先处理AND操作符。所以在进行过滤操作时,需要引入圆括号。
5)用通配符进行过滤
如like,%,_,[]等。
5.分组语句
“Group By”从字面意义上理解就是根据“By”指定的规则对数据进行分组,所谓的分组就是将一个“数据集”划分成若干个“小区域”,然后针对若干个“小区域”进行数据处理。常见的应用是进行分类汇总:
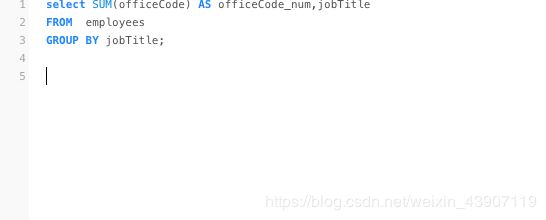
注意:
在select指定的字段,要么就要包含在Group By语句的后面,作为分组的依据;要么就要被包含在聚合函数中,否则会报错。
HAVING语句通常与GROUP BY语句联合使用,用来过滤由GROUP BY语句返回的记录集。rHAVING语句的存在弥补了WHERE关键字不能与聚合函数联合使用的不足。
语法:
SELECT column1, column2, … column_n, aggregate_function (expression)
FROM tables
WHERE predicates
GROUP BY column1, column2, … column_n
HAVING condition1 … condition_n;
参考:在这篇文中讲得比较详细: GROUP BY使用
6.使用函数处理数据
1)常用的文本处理函数

2)时间和日期函数
参考:MySQL 获得当前日期时间函数
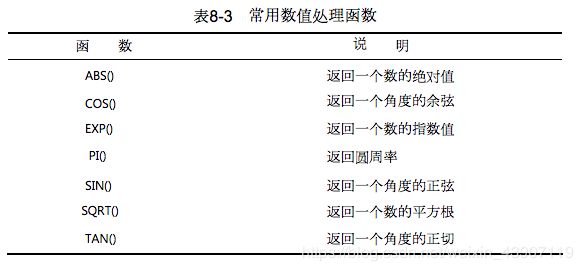
3)数值处理函数
7.使用注释
SQL语句是由 DBMS处理的指令。如果希望包括不进行处理和执行的文本,可以使用注释来达到这一效果。
作用有如下几点:
- 增加描述性注释,便于阅读复杂语句;
- 暂时停止要执行的 SQL代码,便于测试部分语句功能。
8.作业
1)

2)
