垃圾识别术入门:如何找到需要的信息及如何辨别信息真伪如何搜索,如何获知调试“垃圾探测仪”信息力:对信息的注意力
如果说注意力素养的核心是关注你的意图,那么垃圾识别的关键就是时刻保持怀疑。
信息发布是不可逆的。
可靠的可信度检验跟巧妙的网络搜索一样,是一个过程,不能一蹴而就。要掌握专注地使用媒体的方法,第一步是关注注意力。而要想提高批判性地吸收信息的能力,第一步则是进行多次搜索,用多个搜索引擎搜索,以及突破搜索结果的第一页,去看更多的内容。
怎么能知道我在网上找的东西到底是真是假呢?
保持怀疑,查清作者,然后看看别人对作者的评论。
别把网站设计当成可信性的确凿证据,而应将它看做可能的线索。其他的线索包括语法错误、可疑的信息源、信息源缺失、他人对网站的负面评价。
可信度通常是一种感觉,而非人或者计算机产品的实际特性。应该将可信度看做你对于被评估的信息的信任程度。
如果信息源是有信誉的,或者从属于著名品牌,调查网络信息可信度的负担将有所减轻,但无法彻底消除。
即便是被普遍认为可靠的信息源也无法保持100%的权威。
判断网站是否符合可信度的评判标准:
网站的受欢迎程度,专业的声誉,线下的名声(包括网站是否聘请了拥有一定资源并能够收集到确实可信信息的员工),个人使用该网站的经验,与“中立”机构的联系(比如.gov、.edu和.org就分别表示与政府、教育机构和非盈利组织的联系),笔法(客观或偏激),风格(引用的方法,图片,对齐方式,报刊排版等),等等。
在大多数情况下,用可靠换取方便是合理的,但这并非绝对。有时,最好的策略是,问问自己是否有时间再调查一下,同时考虑一下不这么做的代价是什么。
以往人们将可信度同权威以及等级联系在一起,如今人们综合多种信息来对某条信息的可信度加以判断。网络化的数字媒体催生了参与的迫切需要,而综合信息的要求以及越来越多可供综合的信息正是这种需要的产物。
电子化的网络以及社会化的计算机应用,让个体更容易利用群体智慧来评估网上的信息以及信息源。
要想利用群体智慧,评估群体智慧的质量是一项必备技能。
PageRank:
一种为搜索结果排序的算法,对某个网页排序的依据是有多少其他网页链接到了该网页
中。在所有的搜索结果中,被其他网页引用次数最多的页面被排到了靠前的位置;如果两个搜索结果被引用次数同样多,那么被更受欢迎的网站所引用的搜索结果就会占据上风。
如果孩子们在更多的层面上对互联网参与得更多、更深入,他们可能会培养出一种健康的怀疑主义的态度,并且关注网上信息的可靠程度……他们会用更多的方法来评估可信度,并且对于这种评估一丝不苟,这也会让孩子们更加谨慎,不轻易信任陌生人。
要想获取新的、不熟悉的领域的信息,非常重要的第一步是浏览网络并进行搜索。
消费媒体的五条原则:
第一条原则是“保持怀疑”
第二条原则是“主动判断”
第三条原则是“开拓思维”
第四条原则是“不断追问”
第五条原则是“学习媒体技能”
SwiftRiver从Twitter、Flickr、YouTube以及其信息源实时地提取数据。自然语言处理程序自动地为文本贴上“人物”“主题”“地点”等标签;而拥有计算机或智能手机的虚拟社区成员能够实时地复核这些自动添加的标签,即用众包的方式实现信息筛选。
谷歌和必应等搜索引擎主页上有“高级搜索”链接,那些勤勉的用户能够借此实现多种高级的功能:查找包含数个词条的页面,而这些词条必须以某种特定的顺序出现;查找包含某个特定的词或者短语的页面;查找包含某一组词中任何一个或多个词语的页面;在搜索结果中删除包含某个词条的页面,等等。
有时候,用多个词条来搜索能让你锁定答案,但过于精确的词条有时也会让人误入歧途。添加词条的确增强了搜索的精度,但这也限制了搜索结果的范围。通常,在你刚开始寻找信息的时候,最好是宽泛地搜索。
揣摩作者的想法,然后选择你认为会出现在目标网页上的关键词。
充分地了解搜索结果页面的布局:
大多数有信誉的搜索引擎都会将赞助商链接和普通的搜索结果区分开来,赞助商链接通常显示在搜索结果页面的顶端或者右边。对每一项搜索结果,第一行通常用粗体显示,它是网页的标题,同时也是一个链接,点击它就能打开该页面。标题下方是网页的简要介绍,通常只有两行,是网页信息的“摘要”。最下方显示网页的地址,即URL。通过浏览摘要,你有时会找到想要的答案,有时会发现一些能够帮助你搜索的新词条。
搜索能打开一扇自学的大门。
立即识别的三点定位法:即从三个不同的、可信的信息源处验证信息的可靠性(记者,权威机构,著名,可信搜索引擎等)
网络信息可信度:(品牌、联系方式、信誉以及用户反馈等)。其他的影响因素包括使用网页的便捷性、网页设计的质量、有无错误信息、技术性问题(如掉线、无法登录网站等)、更新速度以及可靠性(更新的频率、信息的一致性和可验证性等)
调试“垃圾探测仪”
从本质上看,一个人在形成自我定位的时候,必然会进行垃圾识别。要形成对谎言的敏感度,我们必须或多或少地明白如何问问题,如何验证答案的正确性,以及如何探求意义。
培养信息素养是应对信息污染的可行对策。己所欲者,不忘施于人也。
互联网健康基金会(Health on the Net Foundation)是一个稳定的信息源,它提供可靠的在线医疗信息。它甚至还提供了一个浏览器插件,帮助你比对该基金会数据库和其他网站的信息。
“搜索引擎观察”(Search Engine Watch)网站是搜索引擎业界的专业网站,我认为它信息非常丰富。
谷歌搜索引擎排序网页原理:搜索结果排序的算法,对某个网页排序的依据是有多少其他网页链接到了该网中页。在所有的搜 索结果中,被其他网页引用次数最多的页面被排到了靠前的位置;如果 两个搜索结果被引用次数同样多,那么被更受欢迎的网站所引用的搜索 结果就会占据上风。(这种机制有效地集成了群体的判断)
在判断网络信息的可信度的时候,要像侦探一样思考。同样地,面对真实性存疑的网络新闻报道,你得像情报人员一样行动,才能求得真相。要当心谣传,面对某个信息源提供的消息,可以通过检查发布消息的地点来确认消息是否可靠。要审视自己设定的假设,看看有没有与假设相违背的信息。
News Trust.net则是一个网络审稿人的社区,至今集合了大约2.1 万名审稿人。News Trust的目标是深入的批判性分析,而其他针对新闻垃圾识别的社会化媒体应用则试图解决另一个问题,即如何在信息飞速流动的今天便捷地查清信息源是否可信。这要求我们从社会化的新闻生产方式,转向以众包方式运行的信息筛选工具。
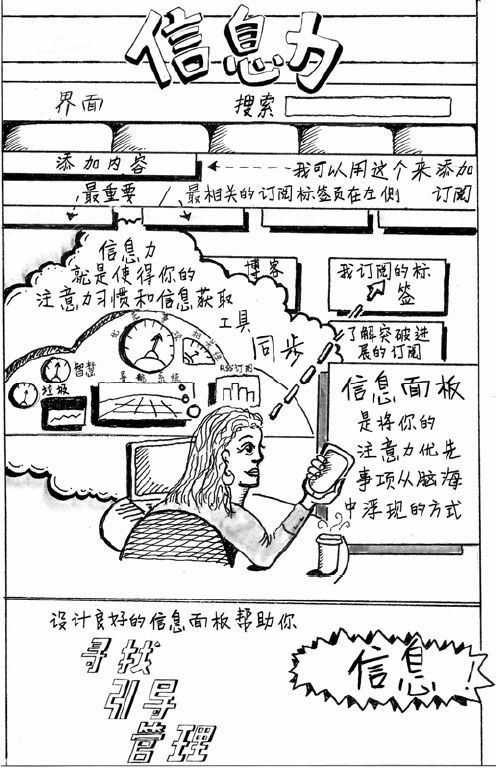
信息力:它描述了一种思维模式,这种模式结合了内在的注意力技能以及基于计算机技术的信息筛选工具。
信息力包含3个元素:
· 如果你希望通过合理地使用网络媒体找到有用的信息,并且掌控这些信息流,你就必须培养一种精神力量,它能够帮助你在适当的时候用适当的注意力模式来处理信息。
· 信息素养的第二个元素与外在的技术有关。你得懂得如何使用搜索和RSS等网络工具,建立自己的情报机关、“新闻雷达”以及信息筛选器。
· 除了自身的注意力技能以及在线工具的有效使用之外,信息力还包括了社会性—— 你需要和他人互动。如今,越来越多的针对信息的宝贵建议通过社会化媒体传输,有了这些建议,我们才能够在网络信息中沙里淘金,找到最新、最有用的信息。所谓的社会化媒体,指的就是协调社交互动和社会关系的在线网络。构建并不断丰富个人学习网络,必须将内在能力、外在技术以及社会化的能量结合起来。
信息力结合了注意力技能、有效的技术以及社会化互动,它的作用在于随时随地找到对你有用的信息。
新的大众传播工具出现,带来大量无序的信息,我们开发新的工具来筛选和整理信息,这促进了传播工具的发展,信息因此愈发丰富,这是一个循环。
专注,就是制定目标,并且形成意图;不时地对自己当下的所作所为施加关注,并且反思你当前的行为同完成目标有什么关系。
微决策是具体的技术,你要靠微决策来解决每时每刻的信息过载问题。
如今,人和机器发布信息的速度实在太快,而搜索引擎也飞快地整合各种信息,我们已然生存在“实时网络”当中,要迅速地找到最新、最可靠的信息流,这个过程的关键是“调试”和“信息流”。你得“调试”注意力,关注那些正确的信号,吸收对你有用的信息,避开不恰当的信息。这就要求你懂得选择恰当的工具,并且设置“持续搜索”的功能。
信息力的基础工具:RSS推送。
“新闻雷达”,即将不同RSS推送消息按某种逻辑捆绑在一起。
报纸的排版就是一种符合信息力要求的方法,它利用了人们原有的注意力习惯(并强化了这些习惯),实现了从纸质媒体到电子化信息的过渡。
分类是一种认知行为,正是这种行为将数字化信息管理工具和注意力联系起来,就像呼吸和大脑相联系,身体技能和意图相联系一样。
Wiki Trust是一个针对维基百科作者及加州大学圣克鲁斯分校所有信息的信誉评估系统。用户安装了Wiki Trust插件之后,维基百科的页面就会以多种颜色显示,不同的颜色代表文字的不同信誉度。
Wiki-Watch:它通过研究引用信息源的数量、作者的数量和剩余以及相关链接的数量来评估维基百科词条的可靠性。
互联网出现之前的信息发布模式是“先筛选后发布”,编辑和出版商会先审核文本,然后再发布合格的信息;而如今,“先发布后筛选”大行其道。
算法权威:一种认为自动的信息提取过程具有权威性的看法,这种过程通常是从广泛的、不一定值得信任的信息源中获取信息。这个过程完全自动化,涵盖数字化信息集成技术和人的意见的系统。
权威实际上有双重功能。
求助于权威,一方面能够增加获得正确信息的概率,另一方面能减少犯错的惩罚。权威的信息源不仅仅是你所信任的信息源;它还是你和你的‘参照系’中的人共同信任的信息源。
大众分类法,指的是许许多多的人用自己的分类方式(比如不同的标签)来为信息分类,而不是遵循某种预先设计好的分类规则。
“维基现实”(Wiki reality):让观众在维基百科上发布虚假消息,这样就能用维基百科创造出虚假的真实。
Truthy:探测政治诽谤、恶性营销、谣言以及其他社会信息污染。
局限:将需要推广的品牌名称和毫无意义的词语 或者从别的博客上摘抄下来的内容混合在一起发布,以便骗谷歌算法。
URL:包含的信息指出文件的位置以及浏览器应该怎么处理它。也就是说他告诉你这个文件的IP地址来自哪里,以及在浏览器上是用ftp(文件传输协议)还是http(超文本传输协议资源)等其他处理方式
并行学习:实践和学习同时进行,且在一定条件下相辅相成,相互促进。(边学边练)
门槛站点:为你提供一系列外部链接,帮助你能够入门的网站。维基百科通常是研究某个课题的绝佳起点。
守门人:来自“守门理论“用户平时所浏览的新闻,用来形容都筛选,加工和整理新闻信息的专业媒体从业人员。
回音壁效应:人们只关注那些符合自身已有信念的信息
RSS 简易信息聚合(也叫聚合内容):基于XML标准,在互联网上被广泛采用的是一种信息聚合的技术,都是为了提供一种更为方便、高效的互联网信息的发布和共享,用更少的时间分享更多的信息。内容包装和投递协议。RSS(Really Simple Syndication)是一种描述和同步网站内容的格式。
XML:可扩展标记语言,标准通用标记语言的子集,是一种用于标记电子文件使其具有结构性的标记语言。 将一些操作和人类语言所对应的属于计算机的语言
这仅代表我个人的想法,希望大家能给我一些建议。