回归问题一般解决方法
1. 回归问题
Given a labeled training set learn a general mapping which associates previously unseen independent test data with their correct continuous prediction.
回归问题和分类问题很相似,区别在于回归问题的输出是一个连续值。

上图是训练数据 和 对应的连续值的一个实例。训练数据用黑色点表示,数据对应的连续值由它在y轴上的位置体现。这个例子中,输入是一维的:x是自变量,y是因变量。
图中灰色点表示的是一个没有在训练数据中出现的数据,回归任务的目标就是根据训练数据得到自变量和因变量之间的关系。得到这个关系之后,对于没有出现在训练集中的数据,可根据其自变量,估计其因变量的值。
2. 一般步骤
要寻找数据和对应连续值之间的关系,实际就是要找到一个函数,能够将数据映射到连续值上。
回归问题一般通过以下三步解决:
1. Model: function set
选择一个模型。模型实际就是函数的集合,线性回归模型,就是所有线性函数组成的集合
2. Goodness of function
需要有一个评判标准,能够判断函数的好坏
3. Best function
利用上一步中评判标准,在函数集合中找到最好的函数
对于不同的模型,寻找最好的函数的方法,很有可能是不一样的。但是对于同一个问题,判断函数好坏的方法往往是相同的
3. Goodness of function
评价函数好坏的函数称作loss function(损失函数),一般loss function的值越大,该函数表现得越差
它由loss term(损失项)和regularizerm(正则化项)两项相加构成:
1. loss term反映的是预测值与实际值之间的误差。对于回归问题,常用的loss term是均方误差
2. regularizer反映的是函数的复杂程度,函数越复杂,该项的值越大。
3.1. regularizer
正则化项是为了控制函数的复杂程度,它的思想符合奥卡姆剃刀原理:
在所有可能选择的函数中,能够很好地解释已知数据并且十分简单才是最好的函数
参数向量的范数是一种常用的正则化项:
以 L1 L 1 范数为例,参数的绝对值之和越小,正则化项越小,函数越简单。极端情况,某个 wi w i 为0时,相当于某个参数没有作用。
4. Model & Best function
4.1. 线性回归模型
线性回归模型,表示的是线性函数的集合, y=wTx+b y = w T x + b 。其中x和y都是向量。
4.1.1. 最小二乘法
当loss function为均方误差时,用最小二乘法可以直接计算出 w w 和 b b 的解析解。
最小二乘法找到的是误差平方和最小的函数:
这里 ŷ i y ^ i 表示的实际值, N N 是样本个数
最小二乘法实际是对 w w 和 b b 分别求偏导,令导数等于0
由于 xi,ŷ i x i , y ^ i 都是已知的,所以可以计算出 w w 和 b b 的值
求偏导等于0有效的原因,主要是因为函数的形式保证了偏导为0时,恰好能够取到最值。
4.1.2. 梯度下降法
当loss function改变了,最小二乘法很可能不再有用。这时,可以采用梯度下降法。梯度下降法是一种迭代式的算法。
梯度下降法的基本思想,就是对loss function求参数的梯度,向梯度下降的方向更新参数:
L是loss function
θ θ 是参数构成的向量
∇L(θt) ∇ L ( θ t ) 是t时刻的梯度,loss function对各个参数求偏微分得到的结果构成的向量
η η 是learning rate,体现的是每次调整参数调整的大小。因为要找的是向梯度下降的方向,所以learning rate之前有负号。 η η 和梯度相乘体现的是,梯度越大,调整的量也越大。
在整个训练过程中, η η 不应该是始终不变的。如果 η η 始终不变, η η 过小会导致需要很多次迭代,参数才能收敛,并且容易陷入局部极值点; η η 过大,会导致效果不佳,容易在极值点附近震荡,但是始终到不了极值点。
所以理想的 η η ,一开始较大,后面趋于极值点时逐渐减小。
Adagrad
Adagrad是一种常用的learning rate自动调节方法
w是一个具体的参数
gt=∂L(θt)∂w g t = ∂ L ( θ t ) ∂ w
ηt=ηt+1√ η t = η t + 1 ,体现出learning rate随迭代次数会变化
σt=1t+1∑ti=0(gi)2‾‾‾‾‾‾‾‾‾‾‾‾‾√ σ t = 1 t + 1 ∑ i = 0 t ( g i ) 2 root mean square
实际上 t+1‾‾‾‾‾√ t + 1 这一项可以被除去
Adagrad关心的是当前梯度与之前其他梯度之间的反差
∑ti=0(gi)2‾‾‾‾‾‾‾‾‾‾√ ∑ i = 0 t ( g i ) 2 ,这一项能体现loss function二次微分的变化。二次微分越大,体现的是 gt g t 变化的越快,这一项的值也会越大
Stochastic Gradient Descent随机梯度下降
一般的梯度下降,计算所有样本的loss function后,update参数
SGD:
1. (随机)选择一个样本
2. 计算这个样本的loss function,update参数
更新参数更频繁,有助于加速训练
4.2 多项式回归
多项式回归模型,表示的是多项式函数的集合,例如:
如果令 X2=x22,X3=x33 X 2 = x 2 2 , X 3 = x 3 3 ,则
则函数变为了关于 x1,X2,X3 x 1 , X 2 , X 3 的线性函数,4.1中的方法依然有效
4.3 regression tree回归树
回归树是由决策树发展而来的,决策树一般用于分类问题
决策树的定义:
决策树是以层次的方式组合起来的一组问题的集合,并以树的形式进行表示。
对于一个给定的输入对象,决策树通过依次询问关于它已知特征的问题,来预测它的未知特征。后一个询问的问题,依赖于前一个问题的回答,这种依赖关系表示为树中的路径;对象的未知特征由路径上的终点决定。
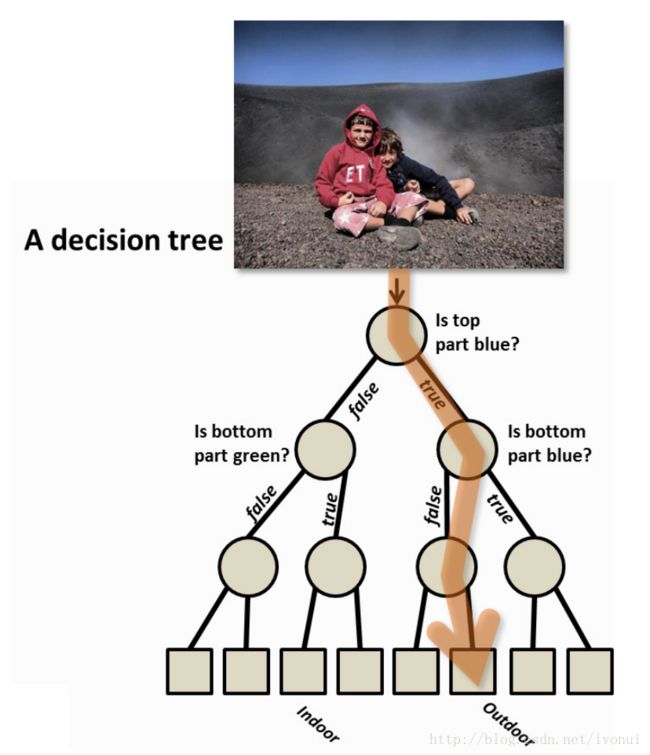
上图是一棵判断照片场景的决策树,通过对多个问题的依次判断,最终得到照片所属的场景。
决策树可以认为是一种将复杂问题不断分解为简单问题的思路。在建立决策树的时候,需要考虑的问题是 选择哪一个特征对当前的数据进行划分、如何防止过拟合等。
与决策树的思想类似,回归树的思路是将一个复杂的非线性回归问题,分解成一组更小的能够被简单模型(比如线性模型)解决的问题

上图是一个二叉回归树的实例,从树根向下,数据的熵会不断变小。
与构建决策树类似,构建回归树时需要考虑的问题是,选择哪一个属性对当前的数据进行划分。与决策树不一样的地方在于,需要预测的属性是连续的,因而在叶子节点选择什么样的预测模型也很关键。
4.3.1 CART(Classificaion and Regression Tree)分类回归树算法
CART是一种常用的建立二叉决策树的算法,既可以用于分类也可以用于回归,并且连续和非连续的属性都能够处理
CART算法有两个关键步骤:
1. 递归划分训练样本,进行建树
2. 利用验证集进行剪枝
建树的伪代码如下:
createTree()
找到最佳的待切分特征:
如果该节点不能再分
将该节点存为叶子节点
否则
执行二元切分
左子树调用createTree()
右子树调用createTree()由于CART建出来的是二叉决策树,这减少了切分特征的难度,只需要选择一个切分点,将样本切分成两部分
1. 对于离散型特征
枚举特征取值的不同组合,分别放到树的左枝和右枝。对不同组合产生的树进行评判,找到最佳组合
2. 对于连续型特征
将取值排序,分别取两相邻值的平均值作为分隔值,小于和大于分隔值的分别放在树的左枝和右枝。对不同分隔值产生的树进行评判,找到最佳分隔值
切分的目标是让样本随着树的分支变的越来越纯,使得叶子节点样本的预测比较简单
树的纯度有多种度量方式,CART算法建立回归树时,常使用最小平方残差作为度量:
利用这个度量希望达到的效果是,组内方差最小,组间方差最大。即决策树的两枝内部差异小,两枝之间的差异大
剪枝的目的是为了限制树的生长,避免过拟合。剪枝分为预剪枝和后剪枝。
- 预剪枝是通过提前停止树的构造来对树进行剪枝。一般的策略有:树的深度达到用户的要求,样本个数少于用户的设定,纯度的上升幅度小于指定的幅度等
- 后剪枝是先构造完整的决策树,允许发生过拟合。在完整的决策树上,将一些节点剪去
CART中采用了代价复杂度剪枝(Cost-Complexity Pruning, CCP),这是一种后剪枝
对于决策树 T0 T 0 的每一个内部结点t,计算
其中, Tt T t 表示以t为根的子树, C(Tt) C ( T t ) 表示 Tt T t 子树的预测误差, C(t) C ( t ) 将t为根节点的子树剪去后,独根树t的预测误差, |Tt| | T t | 表示子树 Tt T t 的节点个数
剪去t为根的子树,对预测误差的影响越小,剪去的节点越多, g(t) g ( t ) 越小
CCP从 T0 T 0 开始,计算出最小的 g(t) g ( t ) ,剪去以t为根节点的子树,得到一个新的决策树 T1 T 1 。不断进行这个操作,产生一个决策树的序列 T0,T1,T2,T3... T 0 , T 1 , T 2 , T 3 . . . ,直至决策树仅剩下根
在得到的决策树序列中,用验证集找到效果最好的决策树
除了CART算法之外,决策树生成算法还有ID3,C4.5等等,这些算法用了信息增益、信息增益比等不同指标对树的纯度进行度量
4.4. 神经网络
神经网络一般用来解决分类问题,也可以用来解决回归问题
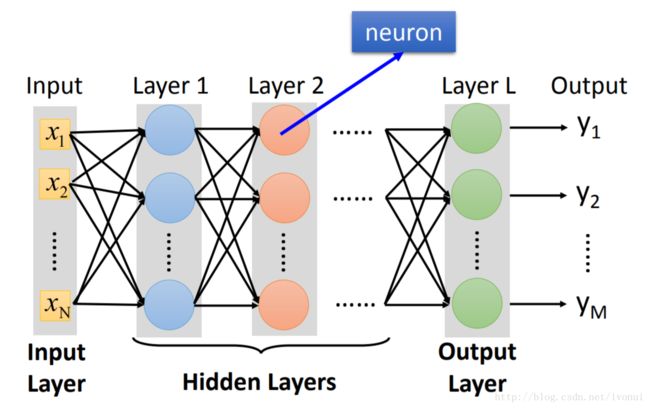
上图是一个神经网络的示意图。神经网络有一个输入层、一个输出层、0到多个隐藏层。输入层的维度等于样本的特征个数,输出层的维度和具体问题有关,在回归问题中,输出层是一维的,即预测值。隐藏层的层数和维度需要通过经验和不断尝试确定。
每一层中的元素被称作神经元,它有多个输入,一个输出。将输入加权求和,再加上bias,通过一个激活函数,得到一个在0至1之间的值作为输出。实际上,当激活函数是sigmoid函数( σ(z)=11+e−z σ ( z ) = 1 1 + e − z )时,每一个神经元完成的就是一个逻辑斯蒂回归。
神经元之间的连接方式需要用户来指定,上图的神经网络,每一层的神经元都和上一层所有神经元的输出相连,这种神经网络被称作全连接神经网络
不同结构的神经网络,可以看做是不同的模型。结构确定后,神经网络的神经元还有很多参数需要调整,预测效果最佳的参数组合构成的神经网络可以看做是best function。
神经网络结构确定之后,寻找best function的过程,一般采用反向传播算法。
4.4.1. 神经网络用于回归
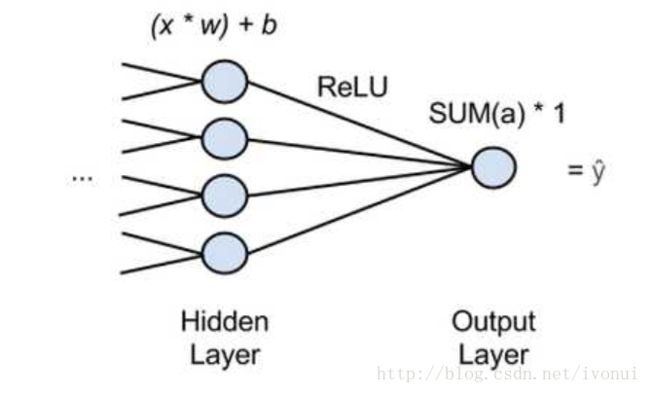
输入层和隐藏层与一般分类问题的神经网络类似,区别在于回归问题的神经网络的输出层只有一个神经元,并且这个神经元不能使用一般的激活函数。激活函数会使得输出限制在0和1之间。所以输出层的神经元直接去掉激活函数,只是将输入相加
回归问题的loss function,一般使用mse
5. 误差分析
在确定了一个模型,找到best function之后,预测的误差可能还是不能让人满意。接下来需要对误差进行分析,改进模型
不同模型在同样的数据集上会有不一样的表现,分析当前预测的误差,有助于发现模型的改进方法
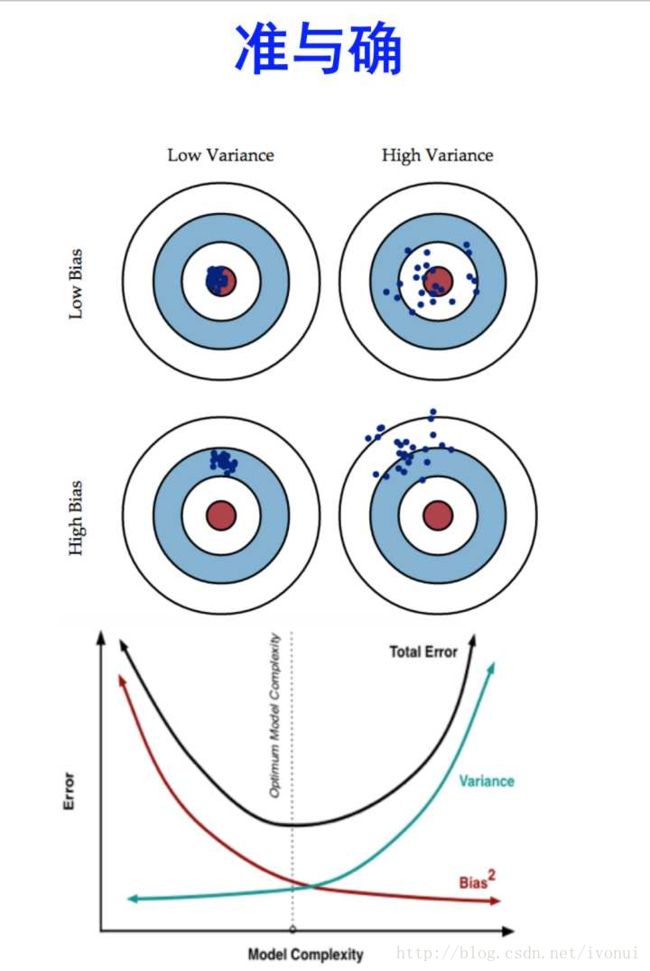
对于同一个模型,随机选择一些训练数据,能够找到模型的best function;多次随机选择不同的训练数据,就会找到不同的best function。上图中每一个蓝点是以这种方式找到的best function,蓝点与红色靶心偏差越大,体现的是best function的预测误差越大。
最佳情况下,同一个模型按不同数据集找到的best function都聚集在靶心上
如果这些best funxtion比较分散,但best function的中心在靶心上,这反应了模型表达能力很强,但是表现的不稳定,不同数据集得到的best function差异比较大。这种误差来源,称作variance
如果这些best function很集中,但best function的中心离靶心很远,这反应了模型表现很稳定,但是不同数据集得到的best function表现都很差。极端情况下,模型每次都返回相同的值,则所有的best function都在靶上同样的位置。这反应了模型的能力不够,这种误差来源称作bias
模型越复杂,表达能力就越强,一般bias越小,variance越大。目标是找到一个模型,它的bias和variance的和比较小,即总的误差比较小
欠拟合underfitting: large bias low variance,
增加特征;设计更复杂的模型过拟合overfitting: low bias large variance,
增加数据,eg.图片旋转;正则化,使模型更平滑
通过判断当前是过拟合还是欠拟合,有助于对模型或者数据进行相应的调整,从而使总的预测误差减小
6. Ensemble
Ensemble是将多个模型或者一个模型的不同数据集上的best function集合起来,得到一个效果更好的模型的方法。这多个模型之间应该各不相同,有各自擅长的方面
6.1. Bagging
对于一个复杂模型,其variance很大,bias很小
Bagging的基本思想是,划分数据集,不同数据集上利用同一个复杂模型找到多个best function。将这几个best function的预测值求平均,往往会比一个best function的误差更小。
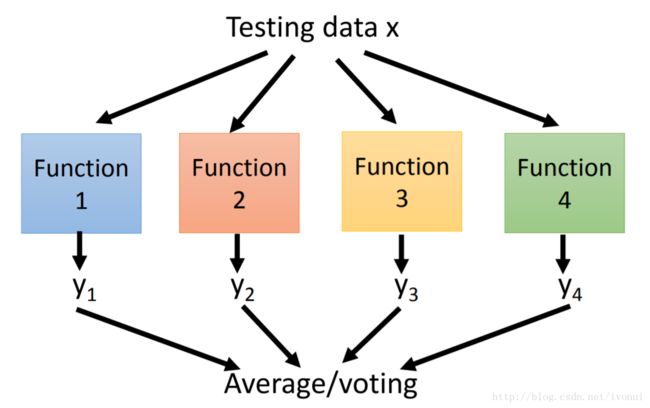
当模型很复杂,容易过拟合时,可以用bagging 降低variance。eg.决策树
6.1.1. Random Forest
随机森林是决策树做了bagging的版本
决策树是很容易过拟合的,在训练集上甚至能做到0%的误差,只要将每一个样本分在决策树不同的叶子节点上
对于决策树而言,简单的划分数据集构造不同的决策树还是不够的。随机森林,随机限制了每个决策树建树时允许使用的特征,从而保证生成的决策树都是不一样的。再将多个决策树的预测结果整合起来,作为随机森林的预测值。
6.2. Boosting
Boosting适用于将多个较差的模型,集合为一个较好的模型
Boosting的思路是,先找到第一个函数 f1(x) f 1 ( x ) ,找到另一个函数 f2(x) f 2 ( x ) 。 f2(x) f 2 ( x ) 要对 f1(x) f 1 ( x ) 有帮助,不能与 f1(x) f 1 ( x ) 很接近,应该与 f1(x) f 1 ( x ) 互补。按顺序找 f3(x) f 3 ( x ) 、 f4(x) f 4 ( x ) …,最后将所有的函数集合起来。
Boosting中可以给每个样本一个权重,样本设置不同权重,得到不同的数据集。
对于 f1(x) f 1 ( x ) ,如何找到对它有帮助的 f2(x) f 2 ( x ) ,有很多种方法
6.2.1 Adaboost
Adaboost是一种boosting方法,其思路是调整样本的权重,构造一个 f1(x) f 1 ( x ) 表现很差的数据集,基于这个数据集得到 f2(x) f 2 ( x )
设样本的权重为u
如果f1分类正确,u = u / d (减小)
如果f1分类错误,u = u * d (增大)f2在权重调整后的数据集上得到
Adaboost根据不同函数的错误率将他们整合起来:
其中 et e t 是函数t分类的错误率,错误率越低,函数的权重越大
6.3. Stack
将多个不同的模型的结果整合起来
将每个模型的输出当做是一个新的特征,新的特征作为最终模型的输入

用Stack方法,需要额外划分出一个数据集,最终模型需要在额外划分出的数据集上训练
7. 补充
对于一般的回归问题,特征工程是很关键的一步,但这里没有涉及到。对于性能预测这个具体问题,特征是比较明确的,一般也不会有缺失值,对特征的处理比较少。
一般回归问题,回归树方法常常很有效。但是对于性能预测这个问题,要用较慢的样本,预测较快的情况,非常不适合回归树来处理。较快情况会聚集在回归树的一个叶子上,预测完全不准确。
8. 参考
- Machine Learning Hung-yi Lee
- 统计学习方法 李航
- 机器学习 周志华