基于深度学习的对话系统---论文简介篇
基于深度学习的对话系统—论文简介篇
这篇文章简要介绍几篇seq2seq应用到对话系统的论文,借鉴大佬的博客。补充一些自己的东西,把自己的思路理清。
主要是这几篇论文:
1.Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
2.Sequence to Sequence Learning with Neural Networks
3.Neural Machine Translation by Jointly Learning to Align and Translate
4.Grammar as a Foreign Language
5.On Using Very Large Target Vocabulary for Neural Machine Translation
6.A Neural Conversational Model
介绍的内容包括作者,论文的发表时间,提出的模型,创新点,应用等方面。
好了,我们开始吧
Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
2014年发表,作者Cho,Bahdanau,Bengio,是seq2seq的前身。
提出一种RNN的Encoder-Decoder模型型,用于统计机器翻译SMT。但是模型只是作为SMT框架的一部分进行的训练。下图是它的结构:
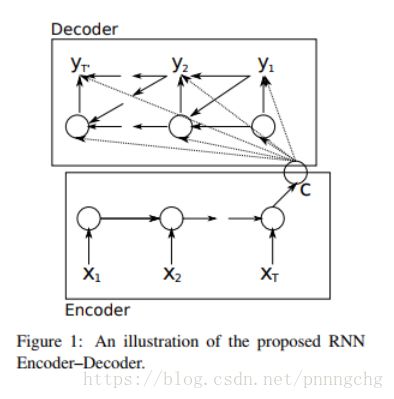
不同于传统的RNN,增加了一个固定维度的向量c,是通过将输入序列进行编码得到的。然后使用另一个RNN进行解码,解码时将c和上一时刻的输出yt-1以及隐层状态ht-1作为输入。
所有输出的yt的概率相乘就是输出序列的概率,两个RNN联合进行训练,学习变长序列之间的条件概率分布。
应用是机器翻译。
另外,这篇文章首次提出了GRU。
Sequence to Sequence Learning with Neural Networks
发表于2014年,作者是Google的研究员,Sutskever等三人。
模型结构如下图所示,实现了end-to-end的训练,不需要人工提取特征。实现的是英法互译。最终的blue值达到了34.8.谷歌翻译目前使用的就是这个结构。
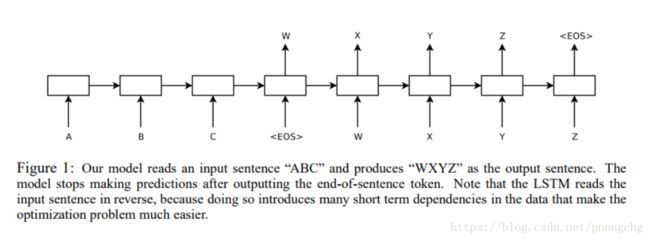
与上一篇我们提到的文章中的结构不同,本文提出的decoder输入固定向量C时不再是每次decode都输入一次C,而是将C作为一个初始化state,只输入一次。
文章有几个需要关注的点:
1.使用深层的LSTM,4层的encoder和decoder,并且表示深层的模型效果要好于shallow的
2.输入序列反向输入,就是ABC变成CBA输入。实验结果显示这样做有更好的效果,但作者也不十分清楚是为什么,只是猜测这样可以增加输入和输出的时间间隔,举例,输入是“ABC”,对应输出是“XYZ”,“A”与对应的“X”的间隔是3,“B”和“C”与其对应的间隔也是3,所以最短时间间隔是3。如果将输入逆序,以“CAB”作为输入,“A”与“X”的间隔是1,最短时间间隔就减小为1。于是作者猜测将输入逆序虽然没有减少源句子(输入)与目标句子(输出)的平均间隔,但是源句子与目标句子是前几个词的距离减少了,于是句子的“最短时间间隔”减少了。通过后向传播可以更快地在源句子和目标句子之间“建立通信”,整体的性能也有了显着的改善。
3.与attention不同的是,文章提出的结构又回归到原始模型,在编码端将输入句子编码成一个固定维度的向量。作者表示这样可以迫使模型学习捕捉句子的意思,尽管句子的表达方式不同。
4.使用beamsearch,在测试阶段使用beamsearch,在训练阶段是不会使用的。通常情况下我们会使用贪婪的方式生成序列,就是每一步都选取概率最大的元素作为当前的输出, 但是这样做的缺点是一旦一个出错了,可能会导致最终的结果出错,所以使用beamsearch进行改善,每一步选取概率最大的k个序列(beam size),作为下一次的输入。关于beamsearch的详解可以参考这篇文章:https://zhuanlan.zhihu.com/p/28048246
一个多层的LSTM的结构如下图所示:

Neural Machine Translation by Jointly Learning to Align and Translate
2015年 Bahdanau发表。第一篇文章SMT也是这个作者发表的。
提出了NMT模型。应用是英法互译
与之前文章提出模型不同的是,encoder模型使用了双向的RNN,decoder使用了attention机制,其中第二个是一个很大的亮点。
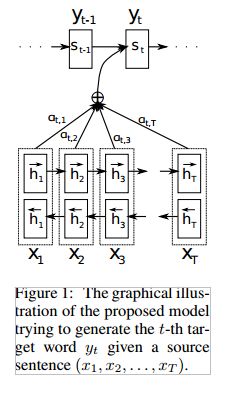
整体的模型结构如上图。
1.双向RNN的encoder使得输出的隐层向量不仅仅包含前面输入的信息,也可以包含后面输入的信息
2.引入attention机制。之前的做法都是将输入层的隐层向量计算一个确定不变的向量c,但是c往往不能不含输入的所有信息,对于长序列更是如此。因此本文提出将隐层向量加权求和的到Ci,对于每一个decoder的隐层向量Si,都有一个对应的Ci,也就是每次解码时都有不同的Ci,并且Ci包含了最相关的encoder隐层向量信息。
On Using Very Large Target Vocabulary for Neural Machine Translation
这篇文章是2015年, Sebastien Jean,Cho,等人发表的。
提出一种NMT的模型,其实在改善NMT模型中的一种计算方法。主要解决在输出词典较大时产生的问题,提出了sample softmax方法。
文章首先分析了NMT相较与SMT的优势和劣势:
优势:
1.NMT不需要过多的预知词句的信息
2.买模型整体训练得到最优的结果
3.NMT内存占用相对于SMT要小
劣势:
目标词的词量受限(通常只能使用30000~80000大小的词典)
NMT目标词量受限主要表现在:
1.目标词典较大时的计算速度回很慢,这是因为输出层需要计算输出词和词典中每一个词的内积,这点在后面我们还会说。所以通常只取30000~80000大小的词典
2.在词典外的词,使用UNK符号代替,所以当目标中的UNK占比较大时,效果就会很差,翻译结果就会有很多UNK符号
那么针对这些问题,当前存在的解决方案主要有两种:
1.基于模型的方法,model-specific:减少训练时的计算量,但是在预测时,仍然需要计算所有的目标词典中的词
- 近似估计目标词的概率
- 将此词典中的目标词进行聚类
2.基于翻译的方法,transla-specific:针对翻译任务的特殊性改进的方案。比如将source和target两两对应起来,使用OOV来表示,这样在翻译结果中出现OOV时,就用source所对应的target来代替。
本文提出的方法是基于模型的方法,将计算复杂度控制在常数级。
计算输出概率的公式如下式,计算量集中在归一化变量Z上,因为他的计算需要遍历整个目标词典。本文提出的方法是,采用一部分词典V’近似估计Z的值,这样就可以将计算复杂度降低到O(V’)。但是V’必然是不能随便选的,不然会导致无法收敛。所以需要根据训练数据提前划分出很多个V’,具体的划分方案就不在这里赘述了。感兴趣的同学可以具体看论文。
