《FPGA并行编程》读书笔记(第一期)02_Fir滤波器
《FPGA并行编程》读书笔记(第一期)02_Fir滤波器
- 1. 绪论
- 2. 读书笔记源码说明
- 3. 9个Solution来学习HLS
- 3.1 S1_Baseline
- 3.2 S2_Remove_if
- 3.3 S3_Cycle_Partition
- 3.4 S4_Manual_Unroll_TDL
- 3.5 S5_Unroll_TDL
- 3.6 S6_Unroll_MAC
- 3.7 S7_ARRAY_PARTITION
- 3.8 S8_Manual_Unroll_MAC
- 3.9 S9_Pipeline
- 4. 总结
说在前面的话:
我最初的规划是一个星期更新一篇文章,但根据过去一天的统计,在没有刻意宣传的情况下,公众号粉丝从0到170人,单篇文章阅读量达600人,这结果对小编来说是个非常好的开始,因此决定熬夜写稿加更一期文章,来回馈粉丝的热情!同时非常欢迎关注公众号拍的小伙伴们推荐给身边有需要的童靴,让更多的人只要有个这个样的公众号分享经验。
1. 绪论
大家上个读书笔记的内容都掌握了吗?个人感觉至少需要6个小时才可以对HLS有个概念性的认识,要真正熟练掌握HLS还得靠接下来10个章节循序渐进的历练。为了使大家对上节内容的理解更加深刻,我联系了Xilinx SAE的军哥,转载他的《跟Xilinx SAE学HLS》系列视频教程,今天转载他的4个与上节内容相关的视频。
Vivado HLS基本流程
- 第1讲 软件工程师应如何理解FPGA
- 第2讲 Vivado HLS 工作机制
- 第3讲 HLS设计流程之基本概念介绍
- 第4讲 HLS 设计流程之实例演示
作者高亚军,FPGA技术爱好者、分享者,出版图书《基于FPGA的数字信号处理》、《Vivado从此开始》,发布视频“Vivado入门与提高”、“跟Xilinx SAE学HLS”。公众号来源及ID(Lauren的FPGA,Lauren_FPGA)
上述视频是权威资源,Xilinx官方录制的视频。
2. 读书笔记源码说明
该书的配套源码下载,见我的Github:PP4FPGAS_Study_Notes_S1C02_HLS_FirFilter
该代码源自原版书籍的源码的重新组织,为的是方便小伙伴们进行学习。
文件组织说明:
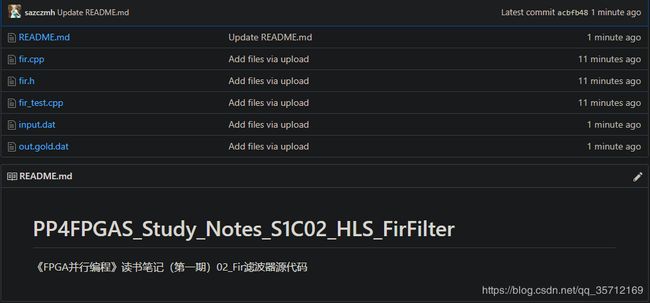
本章有6个用户文件,按照第1章给大家的HLS入门资料新建工程。新建好的工程目录截图如下:
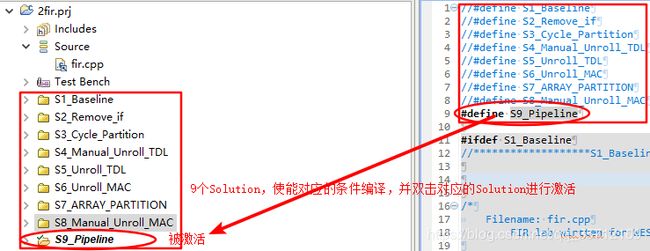
只要取消对应Solution的注释,并双击对应的Solution进行激活,就可以进行接下来的工作了。
3. 9个Solution来学习HLS
3.1 S1_Baseline
大家阅读完《FPGA并行编程》第二章FIR滤波器的概述、背景以及结构基础就可以进行接下来奇妙的实验之旅了。在此郑重说明,大家一定要对FIR有个比较清晰的理解,否则进行很难进行代码重构以及一些HLS的Directive优化。
首先要进行的当然是C Simulation,以此验证C的逻辑正确性。
下面是进行C Simulation容易出现的问题,一定注意把这两个文件加入Test Bench。
否则的话运行C-Simulation运行会出现这个结果
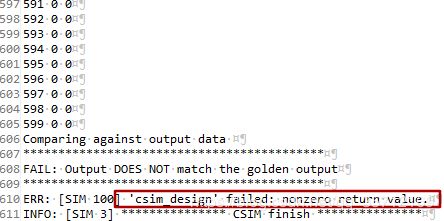
如果自己尝试把英文原版书籍的源码导入工程,就会出现上述莫名其妙的错误。大家可能会好奇,官方给的源码为啥会有问题呢???这里的官方源码当然没有问题,有问题的是自己的操作,没有把out.gold.dat与input.dat加入到Test Bench当中导致出现这个错误。其实官方给了script.tcl这个文件,估计很多小伙伴没有注意。tcl命令说明需要加入这两个文件,这样就可以正常进行仿真出结果了。这个命令行的操作对很多小伙伴不友好,我就不在此介绍了。
正确仿真结果为
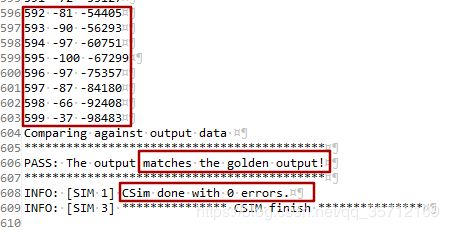
从上图可以看出,仿真正确执行了,这个滤波器输出的结果与文件中已经算好的结果一致。
完成了仿真还不算完,我带大家说明下为啥不添加文件就不可以正确仿真呢。小编当初学习《FPGA并行编程》这本书的时候就没有各位小伙伴当初那么幸运了,想着用官方的源码怎么不可以正确地仿真呢,于是一步一步利用Debug找到了罪恶的源头,发现这些数据文件根本没有被正确的读取…。

这里面采用的相对路径,相对路径和绝对路径我就不在这里科普了,大家可以移步至Google找下。我们可以通过观察Console来看出一点端倪来。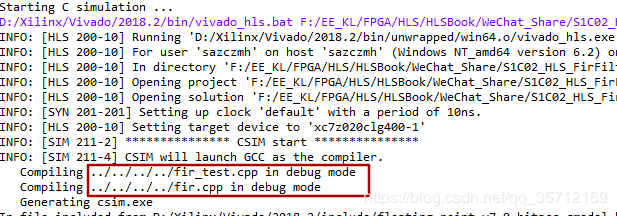
通过这个Console输出的消息我们可以找到对应的C simulation指令所生成的exe文件。
对相对路径和绝对路径熟悉的小伙伴现在应该知道问题出在哪了!也有的小伙伴想,干脆直接使用绝对路径,这也是个办法,只不过代码的可移植性立马降下来了。
然后大家可以直接进行C Synthesis了,综合的结果如下图所示。这个是没有加入优化的原始代码,所以效率比较低。可以简单分析这个fir滤波器的C代码实现,发现它并没有并没有充分利用并行性,后面会通过加入HLS特有的Directive以及代码重构来提升算法的并行性。

3.2 S2_Remove_if
首先进行一次简单的代码重构,即删除for循环中的条件语句,来实现一个更加有效的硬件结构。
#ifdef S2_Remove_if
//*******************S2_Remove_if
#include "fir.h"
void fir (data_t *y,data_t x)
{
coef_t c[N] = {53, 0, -91, 0, 313, 500, 313, 0, -91, 0,53};
// Write your code here
static data_t shift_reg[N];
acc_t acc;
int i;
acc = 0;
Shift_Accum_Loop:
for (i = N - 1; i > 0; i--) {
shift_reg[i] = shift_reg[i - 1];
acc += shift_reg[i] * c[i];
}
acc += x * c[0];
shift_reg[0] = x;
*y = acc;
}
#endif
对比S1与S2的时间以及资源情况,发现并没有产生太大变化。而且fir滤波器的任务延迟好像还“增大了”。小伙伴们先不要急我们的优化才刚开始,慢慢来,最后你会发现HLS的神奇之处。

3.3 S3_Cycle_Partition
现在我们开始进行循环拆分优化,优化后的代码为
#ifdef S3_Cycle_Partition
//*******************S3_Cycle_Partition
#include "fir.h"
void fir (data_t *y,data_t x)
{
coef_t c[N] = {53, 0, -91, 0, 313, 500, 313, 0, -91, 0,53};
// Write your code here
static data_t shift_reg[N];
acc_t acc;
int i;
acc = 0;
TDL:
for (i = N - 1; i > 0; i--) {
shift_reg[i] = shift_reg[i - 1];
}
shift_reg[0] = x;
acc = 0;
MAC:
for (i = N - 1; i >= 0; i--) {
acc += shift_reg[i] * c[i];
}
*y = acc;
}
#endif
循环拆分虽然并不可以提高硬件实现的效率,这从下面的Solution综合报告可以看出,但可以允许我们在每个循环上进行不同程度的优化。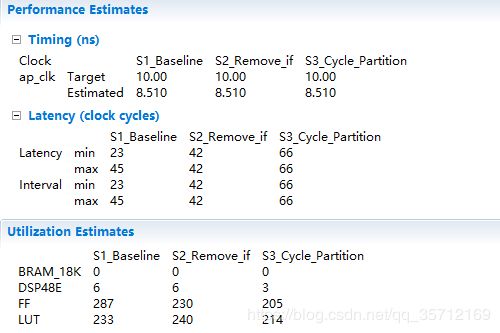
3.4 S4_Manual_Unroll_TDL
首先我们对TDL进行手动循环展开,代码如下
#ifdef S4_Manual_Unroll_TDL
//*******************S4_Manual_Unroll_TDL
#include "fir.h"
void fir (data_t *y,data_t x)
{
coef_t c[N] = {53, 0, -91, 0, 313, 500, 313, 0, -91, 0,53};
// Write your code here
static data_t shift_reg[N];
acc_t acc;
int i;
acc = 0;
TDL:
for (i = N - 1; i > 1; i = i - 2) {
shift_reg[i] = shift_reg[i - 1];
shift_reg[i - 1] = shift_reg[i - 2];
}
if (i == 1) {
shift_reg[1] = shift_reg[0];
}
shift_reg[0] = x;
acc = 0;
MAC:
for (i = N - 1; i >= 0; i--) {
acc += shift_reg[i] * c[i];
}
*y = acc;
}
#endif
通过在Analysis界面对比S3、S4可以发现TDL实现的时间缩短了一半


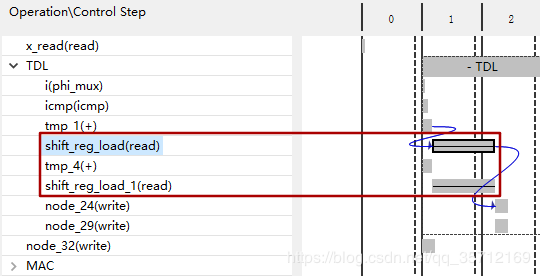

3.5 S5_Unroll_TDL
除了手动进行展开外,可以利用Directive进行指令展开,展开factor=2,这里就不进行代码贴图了

实现效果与S4_Manual_Unroll_TDL一致。
3.6 S6_Unroll_MAC
对MAC也进行展开,展开factor=4 
进行综合结果对比发现对MAC进行展开时,并没有像对TDL展开那样,有非常好的性能提升。在Analysis界面也可以明显看到,MAC展开好像并没有效果呀!不像TDL那么直观明了,需要的时间直接减少了一半。这里读者可能就要怀疑了,是不是HLS有缺陷,导致了这个错误,如果你这样想的话,那就太幼稚了,接下来引出一个非常重要的知识点ARRAY_PARTITION,官方讲解可以去pragma HLS array_partition浏览。
我这里就按照我的理解,结合UG902来给大家讲解吧!
下面是直接Google翻译的上述网站的内容。
ARRAY_PARTITION功能描述:将数组分为较小的数组或单个元素。
具有四个关键参数
- variable=(name):必需参数,指定要分区的数组变量。
- (type):可选择指定分区类型。默认类型是complete。
- factor=(int):指定要创建的较小数组的数量。切记对于完整类型分区,不需要指定因子。但对于块和循环分区,这factor= 是必需的。
- dim=(int):指定要分区的多维数组的维度。
- 如果使用值0,则使用指定的类型和因子选项对多维数组的所有维度进行分区。
- 任何非零值仅分区指定的维度。例如,如果使用值1,则仅对第一个维度进行分区。
具有三种分区类型
- cyclic:循环分区通过交错原始数组中的元素来创建较小的数组。通过在返回第一个数组之前将一个元素放入每个新数组中来循环分区数组,以重复循环直到数组完全分区。例如,如果factor=3使用:
- 元素0被分配给第一个新数组。
- 元素1被分配给第二个新阵列。
- 元素2被分配给第三个新阵列。
- 元素3再次分配给第一个新阵列。
- block:块分区从原始数组的连续块创建较小的数组。这有效地将数组拆分为N个相等的块,其中N是由factor=参数定义的整数。
- complete:完全分区将阵列分解为单个元素。对于一维数组,这对应于将存储器解析为单独的寄存器。这是默认的 (type)。
下面截取UG902来加深大家对ARRAY_PARTITION的理解。
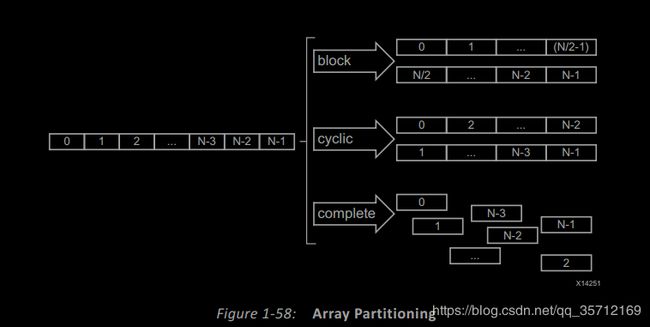
一维数组,factor=2。大家结合上面的介绍来充分理解这张图,对ARRAY_PARTITION的深刻理解对以后的各种优化都非常重要哦!
上面是一个三维数组进行ARRAY_PARTITION,要理解好各个参数的对应关系,我在这里就不多费口舌了。

最后一个我这里就不多说了,有能力者可以先学下。
大家如果读懂上述的ARRAY_PARTITION如何使用之后,接下来我们就继续进行优化了。
3.7 S7_ARRAY_PARTITION
通过上节对ARRAY_PARTITION进行讲解之后,大家应该都明白ARRAY_PARTITION如何使用了吧。对循环展开涉及到的c 、shift_reg两个数组的读取进行如下优化。

通过下图发现这个优化策略仍然没有实质性的性能提升。
分析Analysis界面的结果也可以看出,并没有并行执行呀!这是因为循环之间有依赖关系,这个问题的解决需要在后面章节见分晓!现在我们来执行个手动展开来优化,使之可以综合出并行效果的硬件。
3.8 S8_Manual_Unroll_MAC
手动展开MAC代码见下图
#ifdef S8_Manual_Unroll_MAC
//*******************S8_Manual_Unroll_MAC
#include "fir.h"
void fir (data_t *y,data_t x)
{
coef_t c[N] = {53, 0, -91, 0, 313, 500, 313, 0, -91, 0,53};
#pragma HLS ARRAY_PARTITION variable=c complete dim=1
// Write your code here
static data_t shift_reg[N];
#pragma HLS ARRAY_PARTITION variable=shift_reg complete dim=1
acc_t acc;
int i;
acc = 0;
TDL:
for (i = N - 1; i > 0; i--) {
#pragma HLS UNROLL skip_exit_check factor=11
shift_reg[i] = shift_reg[i - 1];
}
shift_reg[0] = x;
MAC:
for (i = N - 1; i >= 2; i -= 3) {
acc += shift_reg[i] * c[i] +
shift_reg[i - 1] * c[i - 1] +
shift_reg[i - 2] * c[i - 2] +
shift_reg[i - 3] * c[i - 3];
}
for (; i >= 0; i--) {
acc += shift_reg[i] * c[i];
}
*y = acc;
}
#endif
对比综合结果,是不是很神奇,现在仅用0.17us就可以实现fir滤波了。
资源占用也仅仅是提高一点点,真是皆大欢喜。通过观察Analysis界面的结果,可以发现算法按照预计的并行执行了。
为了进一步提高效率,有的小伙伴想不如完全手动展开,这样算法的执行效率不就更高了吗?答案当然是否定的,虽然执行效率更高了,但是占用了很多DSP资源,得不偿失。后面会利用更有效的方法来进一步的减少任务延迟,优化逻辑资源的利用率,让这些资源没有片刻休息时间。另外我在此章节刻意隐藏一个bug,这个bug我还没找到解决方案,因此就暂且搁置,我会在本读书笔记的后续版本进行更新,欢迎大家进行原文阅读导向CSDN,里面有我文章的最新版本。
3.9 S9_Pipeline
pipeline本章节就不做过多介绍了,会在DFT章节进行详细讲解,代码截图为
#ifdef S9_Pipeline
//*******************S9_Pipeline
#include "fir.h"
void fir (data_t *y,data_t x)
{
coef_t c[N] = {53, 0, -91, 0, 313, 500, 313, 0, -91, 0,53};
#pragma HLS ARRAY_PARTITION variable=c complete dim=1
// Write your code here
static data_t shift_reg[N];
#pragma HLS ARRAY_PARTITION variable=shift_reg complete dim=1
acc_t acc;
int i;
acc = 0;
TDL:
for (i = N - 1; i > 0; i--) {
#pragma HLS UNROLL skip_exit_check factor=11
shift_reg[i] = shift_reg[i - 1];
}
shift_reg[0] = x;
MAC:
for (i = N - 1; i >= 2; i -= 3) {
#pragma HLS PIPELINE
acc += shift_reg[i] * c[i] +
shift_reg[i - 1] * c[i - 1] +
shift_reg[i - 2] * c[i - 2] +
shift_reg[i - 3] * c[i - 3];
}
for (; i >= 0; i--) {
#pragma HLS PIPELINE
acc += shift_reg[i] * c[i];
}
*y = acc;
}
#endif
综合结果对比

任务延迟继续减小至0.11us,逻辑资源基本保持不变,算法的并行效果更好。
4. 总结
本章重点介绍了ARRAY_PARTITION、UNROLL以及进行简单代码重构的UNROLL,提及了PIPELINE但没有进行重点讲解,后续会在DFT章节进行详细介绍,还提及了进行C Simulation因为路径问题而要特别注意的地方。位宽优化与复数FIR滤波器我这里就先不进行详细说明了,大家有精力可以自己研究,不是很复杂。最后要说的是,大家最好多看几遍本章的内容,后续内容的复杂度是循序渐进的,不慢慢来的话会面会吃不消的。
原创不易,切勿剽窃!
欢迎大家关注我刚创建的微信公众号——小白仓库
原创经验资料分享:包含但不仅限于FPGA、ARM、Linux、LabVIEW等软硬件开发。目的是建立一个平台记录学习过的知识,并分享出来自认为有用的与感兴趣的道友相互交流进步。
最后要提的是,本文很多资料都是Xilinx大学计划提供,该公众号提供很多的权威信息、开源项目、开发板租借,强烈推荐对FPGA感兴趣的道友关注——XIlinx学术合作。
注:个人精力能力有限,欢迎批评指正!