多因子量化选股(1)
1.1因子就是指标或者说是特征,因子选股模型就是通过分析各种因子与股票收益率之间的关系建立的量化选股体系。

1.2因子有效性评价流程
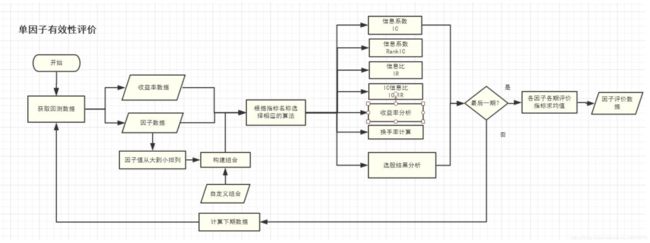
2.1 获取原始数据(因子数据和收益率数据)
首先要确定从哪个角度进行研究,进而确定需要哪些数据。
例如:以沪深300成分股为股票池,每月进行分析、调仓,因子选择:20AD、ROENP(TTM)、NPGR(TTM)
指标释义:
20日收集派发指标(Accumulative Distribution),将市场分为两股收集(买入)及派发(沽出)的力量。属于均线型因子。
Net Profit Growth(本期净利润(TTM)-上年同期净利润(TTM))/ABS(上年同期净利润(TTM))*100
所以需要的数据有:
1.沪深300成分股都有哪些
2.所有成份股的3个因子数据
3.所有成分股的收益率
4.所有成份股的市值数据
5.所有成分股的所属行业
6.策略收益比较基准的数据
一般用作多因子选股模型的因子可以分为两大类:技术分析类因子和基本面分析因子。
技术类因子主要由行情数据加工而来,又可以分为趋势动量类、反转类及波动因子;
基本面因子主要有盈利、成长、估值、收益、资本结构及宏观等。
第一步:
#引用所需库
from WindPy import *
from datetime import datetime, timedelta
from scipy import stats, optimize
from WindCharts import *
import pandas as pd
import WindAlpha as wa# 指标为ad20、TTM的roenp和npgr
ind_code = ['TECH_AD20', 'FA_ROENP_TTM', 'FA_NPGR_TTM']
raw_inds_ret = wa.prepare_raw_data('000300.SH',ind_code, '2017-01-01', '2018-04-30')这里prepare_raw_data函数的详细参数如下:
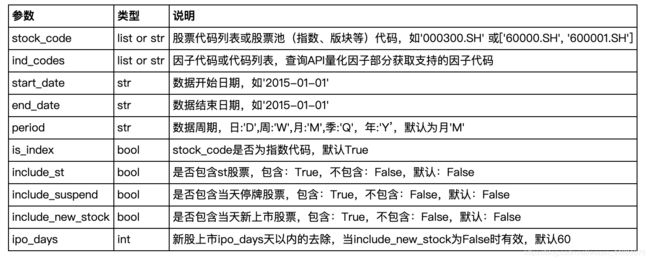
将数据存为csv,然后读成dataframe结构,设前两列为索引并给其命名:
raw_inds_ret.to_csv('data/ind_data.csv')
raw_inds_ret = pd.read_csv('data/ind_data.csv', index_col=[0,1])
raw_inds_ret.index.names = ['date','codes']
接下来要对因子数据进行处理(去极值、标准化)
去极值的主要目的是为了使因子数据在一个合理的范围之内,而不会因为某些异常值对因子的整体分布造成影响,去极值的方法一般有两种:
- 平均绝对离差法(MAD):序列x中,每个元素与x序列均值相减后差的绝对值再求平均值就是MAD(Mean Absolute Deviation)
- 标准差法(Std)
这两种方法的主要区别就是对于异常值判断的度量值不同。顾名思义,MAD去极值法是以n个MAD为界,当元素与均值差的绝对值超过n个MAD时,该元素被认定为异常值,此时我们更改该元素为均值加上(或减去)n倍的MAD;Std法类似,唯一的区别是以标准差为标准判断是否为极值。
对去极值以后的数据进行标准化,这样做的目的是使得横截面数据在一个固定的范围内(量纲的一致性),主要的方法有普通标准化和行业标准化,区别是因子均值的计算方法不一样。
# 标准化
processed_inds_ret = wa.process_raw_data(raw_inds_ret)
# 处理之后的数据
processed_inds_ret
原始数据与处理后的数据分布对比(以日期2017-12-29的数据为例)
import seaborn as se
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(8,6))
plt.subplot(211)
plt.title('processed data')
processed_inds_ret.ix['2017-12-29']['FA_ROENP_TTM'].hist()
plt.subplot(212)
plt.title('raw data')
raw_inds_ret.ix['2017-12-29']['FA_ROENP_TTM'].hist()
plt.suptitle(u"Processed Data VS Raw Data(Date:2017-12-29)")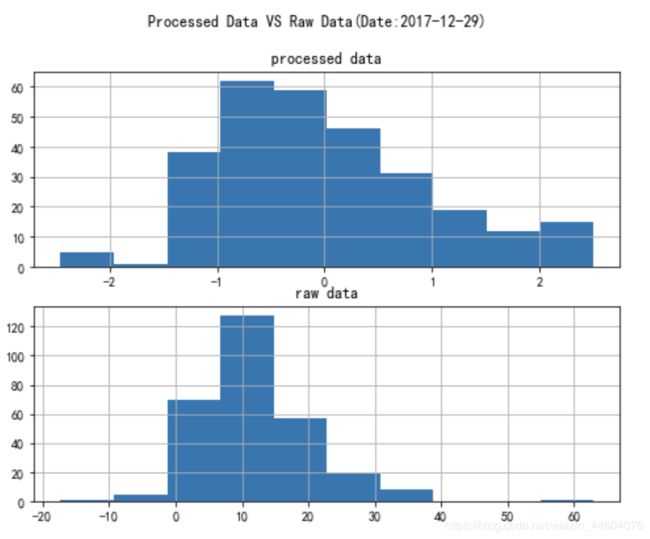
可以看出标准化处理后的数据范围集中在-3到3区间里了。
第二步:因子分析