斯坦福教授告诉你:为什么要学习元学习「 CS330 笔记 (一) 」
文章目录
- 写在前面
- 课程介绍
- 问题导入
- 多任务学习和元学习的意义
- 任务的定义(task)
- 重要假设
- 问题描述
- multi-task vs. single-task
- 多任务学习发展历史
写在前面
本系列博客为斯坦福大学 Stanford CS330: Multi-Task and Meta-Learning 2019 的学习笔记。博客中出现的图片均为课程演示文档的截图。笔记为课程的内容整理,主要是为了方便自己理解和回顾,若有纰漏和错误,烦请评论指出,谢谢啦 ~ 。希望对你有帮助。如需转载,请注明出处。
CS330课程传送门
课程介绍
本系列课程将会涉及的话题
- 问题描述:
阐述什么是多任务学习,元学习。 - 多任务学习基础知识:
- 元学习常见算法:
包括了黑盒算法(black-box approach)、基于优化的元学习(optimization-based meta-learning)、度量学习(metric learning)方法等多种多任务学习算法。 - 贝叶斯分级模型(Hierarchical Bayesian models)和元学习:
如何在贝叶斯分层模型下归纳这些常见算法。 - 多任务RL(Multi-task RL),有限制的目标RL(goal-conditioned RL,),分层RL( hierarchical RL)
- 元增强学习(Meta-reinforcement learning)
问题导入
当我们试图把agent从虚拟环境中带出来,让它在真实环境中学习经验获得知识时,机器人成为了我们的不二之选。但是,当我们在真实环境中使用机器人时,它会遇到很多挑战:
- 机器人需要概括(generalize)其遇到的不同任务,目标,环境等。
- 机器人需要有对常识的理解以更好地处理任务。
- 无法想当然地用监督的方式解决任务,对于标签的提供和具体语境中标签的含义,很难做到准确的添加 。
虽然这样会存在需要样例数据较多等问题,但它的好处是机器人采用的算法并不是只能解决这个特定问题的算法,而是一个可以对较广范围的操作任务处理的算法。

这些实验成果看起来很棒(在当时确实很棒),但是在这些实验中,都存在一个问题。如铲子实验中,机器人学会的其实并不是用铲子把目标放入碗中,而是用特定铲子把特定目标放入特定碗中。如果把碗换成盆或甚至只是改变桌布的颜色,实验都无法进行,因为在训练时的环境已经被破坏了。这个问题其实就是由于当前策略无法总结概括造成的。
面对这个问题,直观上,似乎有一个顺理成章的解决办法。就是设置更多的setting。即准备更多的碗和桌布,但是试图通过这样的方式来获得大量实验数据是不实际的,是十分耗时和费力的。

总结起来就是,从零开始在单一环境中学习单一任务需要细致的监督(supervision)和指导(guidance),同时也需要大量大量的数据来支持。仅以这样的方式,我们很难将其扩展到多种不同的任务中去。这个问题不仅仅只出现在机器人学习领域,它同样也是众多强化学习算法乃至有监督学习领域亟待解决的问题之一。我们可以将这样的系统理解为专才(specialist)。
从人类的经验学习,人类初期学习的过程则更倾向于“通才(generalist)的学习过程。它不同与“专才”,在真正学习复杂任务之前,他会先学习一系列诸如爬、抓取等简单的任务。这给我们建立类似“通才”的机器学习系统的灵感:我们需要建立一个可以通过先前的经验,更好更快地学习更复杂的新知识的系统。
多任务学习和元学习的意义

那么在机器人领域以及试图去建议更通用的模型(general-purpose ML system)之外,还有什么是多任务学习和元学习算法的存在意义呢?
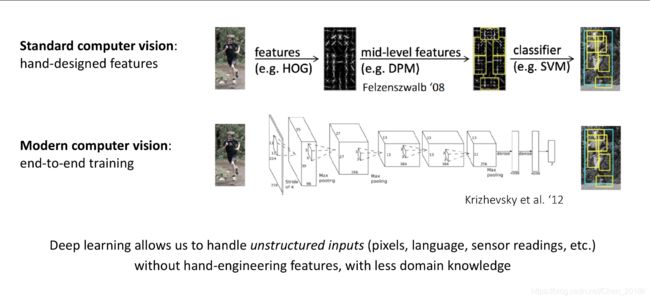
计算机视觉领域从10年前的标准计算机视觉发展到现代计算机视觉,逐步由之前需要提取“人造”特征(hand-designed features 如HOG,SIFT),到现在通过卷积神经网络直接对如像素点,传感器数据等类似的无特征结构输入进行处理。同时我们对于不同领域的问题,处理时也只需要相对较少的相关知识。这是深度神经网络的优势之一,另一个优势则是它的效果也确实好。这样的优势不仅仅只体现在计算机视觉,在机器翻译领域等,效果也很棒。那既然如此,why meta-learning?
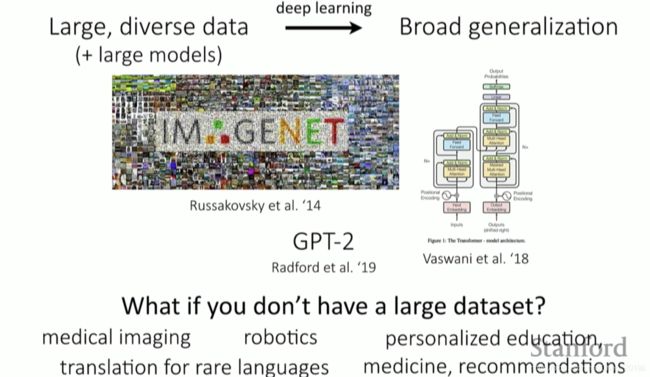
如果想通过深度学习获得较好的模型和效果,我们需要大规模且多种类的数据,才能保证模型的概括性(generalization)。但是如果我们没有这样的一个数据集呢?目前有很多领域都还没法提供较大的数据集:如医学影像、机器人、定制化教育、小语种翻译等。对于每一种疾病,每一个机器人,每一个小语言,其实就是每一个task,我们无法做到从头开始学习。
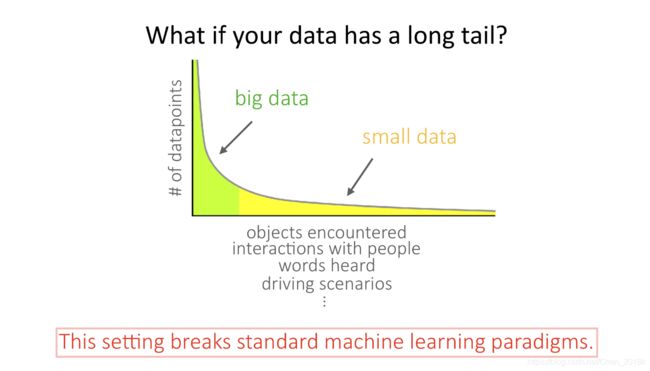
同时,还有老生长谈的长尾问题,尤其体现在自动驾驶领域。

同时,如果我们想快速学习新的目标呢?我们该如何通过过去积累的经验学习一个新的环境或目标?(few-shot learning)
所有的这些问题,就是多任务及元学习的意义所在。
任务的定义(task)
讨论到现在,就有必要对任务这个概念作一个准确的定义,what is a task?
通常来讲,我们可以把task理解为一个机器学习问题,给定数据集 D \mathcal{D} D 和损失函数 L \mathcal{L} L,然后得到模型 f θ f_{\theta} fθ
不同任务的区别可能体现在:
- 不同的物品(从辨识猫狗到辨识不同的水杯)
- 不同的人(定制化教育)
- 不同的目标(从图片辨识人的年龄到辨识身高)
- 不同的光线条件
- 不同的语言
。。。
重要假设
不同的任务需要共享一些模型结构,如果这条不成立,则应该考虑用单任务学习。
这点看起来很苛刻,但从好的方面出发考虑,其实有很多任务都具有相同的结构。即便是一些看起来并不相关的任务:
- 真实世界中的数据基于的物理法则是相同的。
- 所有人都是有目标的生物体,即便是不同的人,也会存在共性。
- 英语背后的语法是相同的
。。。
问题描述
在下一讲中会对元学习和多任务学习下正式的定义,此处只是帮助大家做一个直观的理解。
多任务学习问题:比起单独地学习各个任务,统一学习所有的任务可以更快更熟练
元学习问题:通过在前置任务中以获得了数据/经验,面对新任务可以更快或更熟练的掌握。
两个的区别体现在,在第一个问题中,我们要学习一系列任务,并试图完成这些任务;在第二个问题中,我们试图用过去学习任务的经验来解决新问题。
那很自然地,迁移学习的概念和这两者有什么关系和区别呢?老师给出的答案是,我们可以把迁移学习看作是这两种问题的集合。如何将信息在不同的任务之间传递其实和这两个问题都有关系。
multi-task vs. single-task

利用我们已知数据来源于不同任务的事实,我们可以做一些事情。
多任务学习发展历史


多任务学习算法已经慢慢在机器学习领域成为重要的角色,同时算法需要的数据量也逐渐往更小的趋势发展。