kaggle入门-Bike Sharing Demand自行车需求预测
接触机器学习断断续续有一年了,一直没有真正做点什么事,今天终于开始想刷刷kaggle的问题了,慢慢熟悉和理解机器学习以及深度学习。
今天第一题是一个比较基础的Bike Sharing Demand题,根据日期时间、天气、温度等特征,预测自行车的租借量。训练与测试数据集大概长这样:
// train
datetime,season,holiday,workingday,weather,temp,atemp,humidity,windspeed,casual,registered,count
2011-01-01 00:00:00,1,0,0,1,9.84,14.395,81,0,3,13,16
2011-01-01 01:00:00,1,0,0,1,9.02,13.635,80,0,8,32,40
// test
datetime,season,holiday,workingday,weather,temp,atemp,humidity,windspeed
2011-01-20 00:00:00,1,0,1,1,10.66,11.365,56,26.0027
2011-01-20 01:00:00,1,0,1,1,10.66,13.635,56,观察上面的数据,我们可以发现:租借量等于注册用户租借量加上未注册用户租借量,即casual + registered。评价指标是loss函数RMSLE (Root Mean Squared Logarithmic Error):
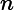
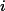


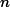
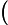


其中,![]()
为实际的租借量,
为样本数。实际上,RMSLE就是一个误差函数。
以下是对数据的描述:
Data Fields
datetime - hourly date + timestamp
season - 1 = spring, 2 = summer, 3 = fall, 4 = winter
holiday - whether the day is considered a holiday
workingday - whether the day is neither a weekend nor holiday
weather - 1: Clear, Few clouds, Partly cloudy, Partly cloudy
2: Mist + Cloudy, Mist + Broken clouds, Mist + Few clouds, Mist
3: Light Snow, Light Rain + Thunderstorm + Scattered clouds, Light Rain + Scattered clouds
4: Heavy Rain + Ice Pallets + Thunderstorm + Mist, Snow + Fog
temp - temperature in Celsius
atemp - "feels like" temperature in Celsius
humidity - relative humidity
windspeed - wind speed
casual - number of non-registered user rentals initiated
registered - number of registered user rentals initiated
count - number of total rentals
整个过程:
# coding: utf-8
# In[54]:
import numpy as np
import pandas as pd
get_ipython().magic('matplotlib inline')
from sklearn import cross_validation
from sklearn.metrics import mean_squared_error
from sklearn.ensemble import RandomForestRegressor
# In[4]:
df_origin = pd.read_csv("train.csv",sep=",")
df_origin.head()
# ### 查看完整24小时的时间
# In[5]:
df_origin.head(24)
# In[6]:
df_origin.tail(24)
# ### 查看描述信息
# In[7]:
df_origin.info()
# In[9]:
df_origin.describe()
# In[10]:
df_origin.columns
# In[12]:
df_origin.shape
# In[11]:
df_test = pd.read_csv("test.csv",sep=",")
df_test.head()
# In[13]:
df_test.shape
# ### 检测异常值
# In[14]:
df_origin.isnull
# In[18]:
#df_test.isnull
# ## 特征工程
# ### 时间离散化
# In[25]:
df_origin['hour'] = df_origin['datetime'].str[11:13].astype(int)
df_origin.head()
# In[26]:
from datetime import datetime
# In[42]:
week = [datetime.date(datetime.strptime(time, '%Y-%m-%d')).weekday() for time in df_origin['datetime'].str[:10]]
df_origin['week'] = week
df_origin.head()
# In[43]:
df_origin['month'] = df_origin['datetime'].str[5:7].astype(int)
df_origin['year'] = df_origin['datetime'].str[0:4].astype(int)
df_origin.head()
# In[45]:
df_origin.columns.values
# In[46]:
df_clean = df_origin.loc[:,['season', 'holiday', 'workingday', 'weather', 'temp',
'atemp', 'humidity', 'windspeed', 'casual', 'registered', 'count',
'hour', 'week', 'year', 'month']]
df_clean.head()
# #### 同理 处理test数据
# In[47]:
#temp = pd.DatetimeIndex(train['datetime'])
#train['year'] = temp.year
#train['month'] = temp.month
#train['hour'] = temp.hour
#train['weekday'] = temp.weekday
df_test['hour'] = df_test['datetime'].str[11:13].astype(int)
week1 = [datetime.date(datetime.strptime(time, '%Y-%m-%d')).weekday() for time in df_test['datetime'].str[:10]]
df_test['week'] = week1
df_test['month'] = df_test['datetime'].str[5:7].astype(int)
df_test['year'] = df_test['datetime'].str[0:4].astype(int)
df_clean_test = df_test.loc[:,['season', 'holiday', 'workingday', 'weather', 'temp',
'atemp', 'humidity', 'windspeed', 'casual', 'registered', 'count',
'hour', 'week', 'year', 'month']]
df_test.head()
# ## 检查数据均衡
# ### log casual和register,然后相加
# In[51]:
df_origin['casual'].hist()
# In[52]:
df_origin['registered'].hist()
# In[57]:
df_clean['log_cas'] = np.log(df_origin['casual'] + 1)
df_clean['log_reg'] = np.log(df_origin['registered'] + 1)
df_clean.head()
# ### 随机森林特征选择
# In[58]:
df_clean.head(10)
# In[59]:
fea_cols=['season', 'holiday', 'workingday', 'weather', 'temp',
'atemp', 'humidity', 'windspeed',
'hour', 'week', 'year']
# ### 许多特征之间有太多相关性
#
# #### season和month,二选一
# #### temp和atemp,二选一
# #### humidity和weather,windspeed,看rf的特征重要度
# #### week和workingday
#
#
# In[60]:
df_clean[fea_cols].corr()
# ### 剔除特征重要度< 0.01的特征
# In[62]:
clf_cal = RandomForestRegressor(n_estimators=1000, min_samples_split=11, oob_score=True)
clf_cal
# In[63]:
clf_cal.fit(df_clean[fea_cols].values, df_clean['log_cas'].values)
pd.DataFrame(clf_cal.feature_importances_).plot(kind='bar')
clf_cal.oob_score_
# In[64]:
clf_cal.feature_importances_
# In[65]:
fea_cas = ['season', 'workingday', 'weather', 'temp',
'humidity', 'windspeed','hour', 'week', 'year']
# In[66]:
clf_cal.fit(df_clean[fea_cas].values, df_clean['log_cas'].values)
pd.DataFrame(clf_cal.feature_importances_).plot(kind='bar')
clf_cal.oob_score_
# In[67]:
clf_reg = RandomForestRegressor(n_estimators=1000, min_samples_split=11, oob_score=True)
# In[68]:
clf_reg.fit(df_clean[fea_cols].values, df_clean['log_reg'].values)
pd.DataFrame(clf_reg.feature_importances_).plot(kind='bar')
clf_reg.oob_score_
# In[69]:
clf_reg.feature_importances_
# In[70]:
fea_regs=['season', 'workingday', 'weather', 'temp', 'humidity', 'hour', 'week', 'year']
# In[71]:
clf_reg.fit(df_clean[fea_regs].values, df_clean['log_reg'].values)
pd.DataFrame(clf_reg.feature_importances_).plot(kind='bar')
clf_reg.oob_score_
# In[73]:
y_pred7 = np.exp(clf_cal.predict(df_clean_test[fea_cas])) + np.exp(clf_reg.predict(df_clean_test[fea_regs])) - 2
y_pred7[:40]
# ### 对结果四舍五入
# In[74]:
y_pred7 = [round(x) for x in y_pred7]
df_test['count'] = y_pred7
df_test['count'] = df_test['count'].astype(int)
df_test.head()
# In[75]:
df_test.shape
# In[77]:
df_test.to_csv('result.csv', sep=',', columns=['datetime', 'count'], header=['datetime', 'count'], index = False)
# In[ ]:
参考:
1. http://www.cnblogs.com/en-heng/p/6907839.html
2. http://efavdb.com/bike-share-forecasting/
3. http://nbviewer.jupyter.org/gist/whbzju/ff06fce9fd738dcf8096#%E6%97%B6%E9%97%B4%E7%A6%BB%E6%95%A3%E5%8C%96