《Java程序性能优化》-葛一鸣
第1章 java性能调优概述
1.1性能概述
1.1.1 一般来说,程序的性能的表现方面:
-
执行速度
-
内存分配
-
启动时间
-
负载承受能力
1.1.2 性能参考指标:
-
执行时间
-
CPU时间
-
内存分配
-
磁盘吞吐量
-
网络吞吐量
-
响应时间
1.1.3 木桶原理与性能瓶颈
最有可能成为性能瓶颈的环节:
-
磁盘IO
-
网络操作
-
CPU
-
异常
-
数据库
-
锁竞争
-
内存
1.1.4 Amdahl定律
加速比=优化前系统耗时/优化后系统耗时
Amdahl定律:
加速比speedup<=1/(F+(1-F)/N)
其中N为CPU处理器数量,F为系统内必须串行化的程序比重。由此可见,为了提高系统的运行速度,仅仅增加N,是不能提高运行速度的,从根本上修改程序的串行化行为,提高系统内并行模块的占比,才行。
1.2性能调优层次:
1.2.1设计调优
1.2.2代码调优
1.2.3JVM调优
1.2.4数据库调优:
1.应用层SQL优化;
2.数据库优化;
3.数据库软件优化;
1.2.5操作系统调优:
共享内存段、信号量、共享内存最大值(shmmax)、共享内存最小值(shmmin)、最大文件句柄数、虚拟内存大小、磁盘块大小。
1.3基本调优策略和手段
第2章 设计优化
2.1善用设计模式
2.1.1单例模式
代理模式
享元模式
装饰者模式
观察者模式
value object模式
业务代理模式
2.2常用的优化组件和方法
2.2.1缓冲buffer
缓冲区是一块特定的内存区域;缓冲区不宜过大,浪费系统内存,增加GC负担;
缓存cache,WeakHashMap;EHCache数据缓存解决方案,OSCache,可用于缓存任何对象,JBossCache可用于JBoss集群间数据共享的缓存框架;EHCache的缺点是缓存组件和业务层代码紧密耦合,依赖性太强;基于动态代理的缓存;
对象复用-池:线程池,数据库连接池;适用场景:创建耗时的大对象,节省获取对象实例的成本,减少GC负担;生成实例成本小的对象,使用池的方式,得不偿失;JDK new操作的效率很高,但是new操作所调用的类的构造函数可能很耗时;apache commons-pool对象池组件,对象池接口ObjectPool,PoolableObjectFactory,内置三个对象池,StackObjectPool,GenericObjectPool,SoftReferenceObjectPool;
并行代替串行
负载均衡,Apache+Tomcat集群搭建负载均衡解决方案,Session共享模式,黏性Session模式和复制Session模式;跨JVM分布式缓存框架Terracotta,可以实现Tomcat的Session共享;
时间换空间,看系统的性能瓶颈是什么,空间是瓶颈,则采用时间换空间;
空间换时间
第3章 java程序优化
3.1字符串优化处理
3.1.1 String对象及其特点
String对象的优化:
1.不变性
不变性:String对象一旦生成,则不能对它进行改变。
2.针对常量池的优化
3.类的final定义
String对象的内部结构:
-
char数组
-
offset偏移量
-
count长度
3.1.2 subString()方法的内存泄露漏
String提供了2个截取字符子串的方法:
public String substring(int beginIndex)
public String substring(int beginIndex,int endIndex)
3.1.3 字符串的分割和查找
字符串分割方法:
public String[] split(String regex)
1.最原始字符串分割
String str;
StringBuffer sb=new StringBuffer();
for(int i=0;i<10000;i++) {
sb.append(i);
sb.append(";");
}
str=sb.toString();
for (int i = 0; i < 10000; i++) {
str.split(";");
}
2.使用效率更高的StringTokenizer类分割字符串

3.更优化的字符串分割方式
自定义字符串分割算法:需要使用String类的indexOf()和subString()
String tmp=str;
for(int i=0;i<10000;i++){
while(true){
String splitStr=null;
int j=tmp.indexOf(“;”);
if(j<0)break; //没有分隔符存在
splitStr=tmp.subString(0,j);
tmp=tmp.substring(j+1)
}
tmp=str;
}
4.高效率的charAt()方法
3.1.4 StringBuffer和StringBuilder
String对象是不可变对象,对字符串进行修改操作时,String对象会生成新对象
1.String常量的累加操作

2.String变量的累加操作
3.构造超大的String对象
4.StringBuffer和StringBuilder的选择
无需考虑线程安全的情况下使用StringBulider,系统有安全要求使用StringBuffer
5.容量参数
构造器:
public StringBuffer(int capacity)
public StringBuilder(int capacity)
不指定容量参数时,默认是16字节。
3.2 核心数据结构
3.2.1 List接口
ArrayList和Vector使用了数组实现,Vector是线程安全,ArrayList和Vector性能特性相差无几。LinkedList使用循环双向链表数据结构。
3.2.2 Map接口
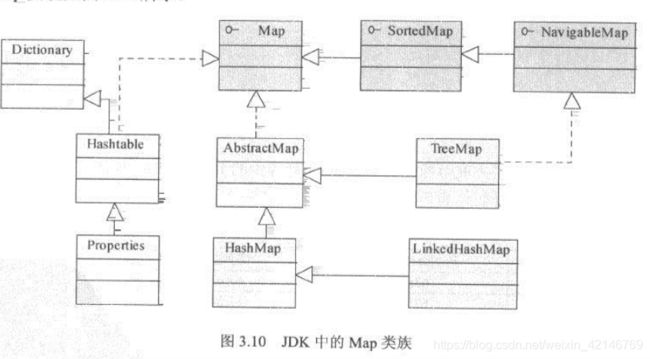
Map接口主要的实现类:Hashtable、HashMap、LinkedHashMap、TreeMap
Hashtable和HashMap的差别:
1.Hashtable是线程安全的,HashMap不是线程安全的
2.HashMap允许null的key和vlaue,Hashtable不允许
3.在内部算法上,它们对key的hash算法和hash值到内存索引的映射算法不同
HashMap的同步实现:Collections.synchronizedMap()
1.HashMap实现原理
HashMap:将key做hash算法,然后将hash值映射到内存地址,直接取得key对应的数据。HashMap底层数据结构采用数组,内存地址就是数组下标索引。
HashMap高性能保证要点:
1)hash必须是高效
2)hash值到内存地址(数组下标)的算法是快速的
3)根据内存地址(数组下标)可以直接取得对应的值


2.Hash冲突
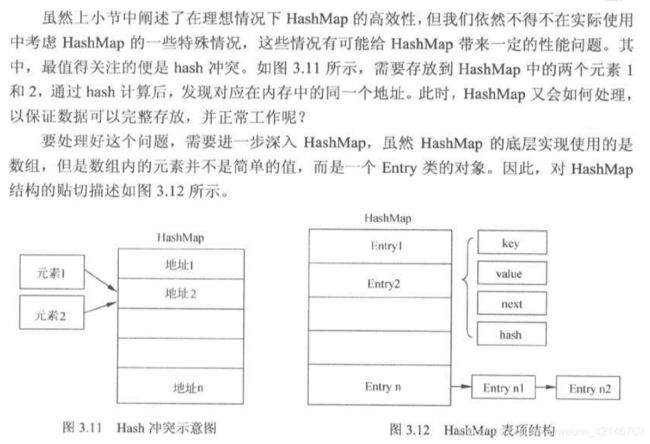



3.容量参数
4.LinkedHashMap-有序的HashMap
3.2.3 Set接口
Set中的元素不能重复。Set:HashSet、LinkedHashSet、TreeSet。HashSet是对HashMap的封装,以此类推,LinkedHashSet对应LinkedHsahMap,TreeSet对应TreeMap。
HashSet内部维护一个HashMap对象,并将所有的Set的实现,都委托给HashMap去完成。
3.2.5 RandomAccess接口
3.3使用NIO提升性能
Java NIO基于块,它以块为基本单位处理数据。最重要的两个组件缓冲Buffer和通道Channel。缓冲是一块连续的内存块,是NIO读写数据的中转地。
3.3.1 NIO的Buffer类族和Channel
在NIO是实现中Buffer是一个实现类,
channel是一个双向通道,既可读也可写。应用程序不能直接对Channel进行读写操作,而必须通过Buffer进行。
3.4 引用类型
3.4.1 强引用
强引用特点:
-
强引用可以直接访问目标对象
-
强引用所指向的目标对象在任何时候都不会被系统回收,JVM宁愿抛出OOM异常,也不回收强引用所指向的对象。
3.4.2软引用
通过java.lang.ref.SoftReference使用软引用。一个持有软引用的对象,不会被JVM很快回收,JVM根据当前堆的使用情况判断何时回收。
3.4.3弱引用
在系统GC时,系统只要发现弱引用,都会将对象进行回收。软引用和弱引用都适合保存那些可有可无的数据。
3.4.4虚引用
虚引用总是和引用队列一起使用,它的作用在于跟踪垃圾回收的过程。
3.4.5 WeakHaspMap类及其实现
它是HashMap的一种实现,它使用弱引用作为内部数据的存储方案。
3.5 有助于改善性能的技巧
3.5.1 慎用异常
3.5.2 使用局部变量
局部变量的访问速度远远高于类的成员变量。
3.5.3 位运算代替乘除法
3.5.4 替换switch
数组替代switch语句。
3.5.5 一位数组代替二维数组
一位数组的访问速度优于二维数组。
3.5.6 提取表达式
尤其要关注循环体内的代码,从循环体内提取重复的代码。
3.5.7 展开循环
int[] arr=new int[999];
for(int i=0;i<999;i++){
arr[i]=i;
}
int[] arr=new int[999]
for(int i=0;i<999;i+=3){
arr[i]=i;
arr[i+1]=i+1;
arr[i+2]=i+2;
}
3.5.8 布尔运算代替位运算
a&&b&&c,a||b||c

3.5.9 使用arrayCopy()
在进行数组复制时应该使用这个方法。


3.5.10 使用buffer进行IO操作;
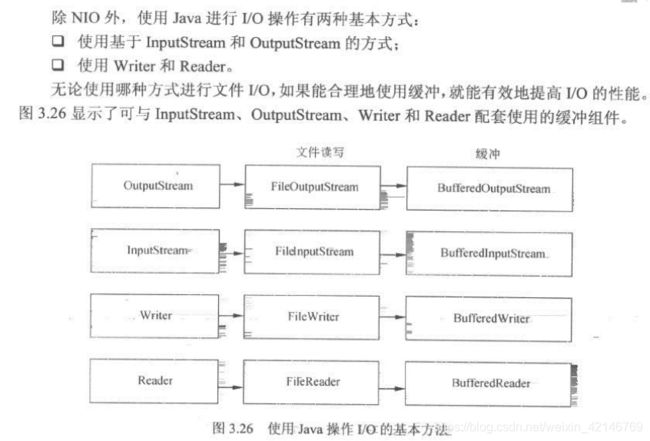
3.5.11 使用clone()代替new
Object.clone()可以绕过对象的构造方法,快速复制一个对象的实例。Object.clone(),默认情况下,clone()生成的实例只是原对象的浅拷贝。
3.5.12 静态方法代替实例方法
静态方法调用速度快于实例方法。
第4章 并行程序开发优化
4.1 并行程序设计模式
4.1.1 Future模式
master-worker模式,类似于fork-join,master进程负责接收和分配任务,worker进程负责处理子任务;
Guarded Suspension模式,
不变模式,不变模式比只读属性具有更强的一致性和不变性,只读属性自身可能变化;不变模式的使用条件:
1. 对象创建后,其内部状态和数据不再发生变化;
2. 对象需要被共享,被多线程频繁访问。
实现4要点:
1. 去掉setter方法和所有修改自身属性的方法;
2. 所有属性私有且final;
3. 没有子类可以继承并重写其方法;
4. 构造函数可以创建完整对象。
4.1.5 生产者-消费者模式
生产者线程负责提交用户请求,消费者线程负责处理生产者提交的任务。生产者和消费者通过共享内存缓冲区进行通信。生产者和消费者的核心组件是共享内存缓冲区。
4.2 JDK多任务执行框架
4.2.1 无限制线程的缺陷
4.2.2 简单的线程池实现
线程池的基本功能是对线程的复用。
4.2.3 Executor框架
自定义线程池
优化线程池大小,估算公式:N = Nc * Uc * (1+W/C),其中Nc是CPU的数量,Uc是CPU的使用率,W/C是等待时间与计算时间的比率。
扩展ThreadPoolExecutor
4.3 JDK并发数据结构
4.3.1 并发List
Vector和CopyOnWriteArrayList是2个线程安全的List实现。CopyOnWriteArrayList:当对象进行写操作时,复制该对象;当进行读操作时,则直接返回结果。核心思想:减少锁的竞争。
4.3.2 并发Set
并发Set有一个CopyOnWriteArraySet,他实现了Set接口,并且是线程安全的,它内部实现完全依赖于CopyOnWriteArrayList,它的特性和CopyOnWriteArrayList完全一致,适合读多写少的高并发场合。在需要并发写的场合,开业使用Collections的方法:
public static
4.3.3 并发Map
多线程下使用Map,可以使用Collections的synchronizedMap()方法可以得到一个线程安全的Map
4.3.4 并发Queue
ConcurrentLinkedQueue代表高性能队列,BlockingQueue接口代表阻塞队列。ConcurrentLinkedQueue适合高并发场景下的队列,它通过无锁的方式,实现高并发状态下的高性能。
BlockingQueue的主要功能在于简化多线程间的数据共享。BlockingQueue典型使用场景:生产者和消费者模式
BlockingQueue最常用的应用场景是多线程间的数据共享。


4.3.5 并发Deque
双端队列(Double-Ended Queue),简称Deque。Deque允许在队列的头部和尾部,进行出队和入队操作。
4.4并发控制方法
4.4.1 Java内存模型与volatile
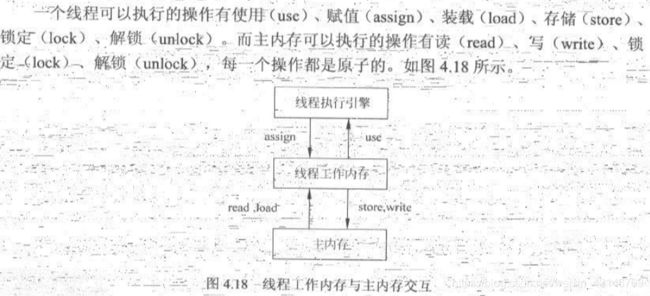
声明valotile的变量:
-
其它线程对变量的修改,可以及时反映在当前线程中
-
确保当前线程对volatile变量的修改,能及时写回共享主内存中,并被其它线程所见
-
使用volatile的变量,编译器会保证其有序性
注意:使用volatile标识的变量,将迫使所有线程均读写主内存中的对应变量,从而使得volatile变量在多线程间可见。
4.4.2 同步关键字synchronized
当synchronized用于static方法时,相当于将锁加到当前class对象上,因此,所有对该方法的调用,都必须获得class对象的锁。
锁性能与优化
无锁并行计算
协程
4.5.9 自旋锁(Spinning Lock)
自旋锁可以在线程没有取得锁时,不被挂起,而转而去执行空循环。若干个循环后,线程如果获得锁,则继续执行。
JVM提供-XX:+UseSpinning参数来开启自旋锁,使用-XX:PreBlockingSpin参数来设置自旋锁的等待次数。
第5章 JVM调优
5.1 JVM内存模型

5.1.1 程序计数器
程序计数器
java虚拟机栈
本地方法栈
java堆
方法区
JVM内存分配参数
最大堆内存
最小堆内存
新生代
持久代
线程栈
堆的比例分配
垃圾收集
垃圾收集器要处理的基本问题:
哪些对象需要回收?
何时回收这些对象?
怎么回收这些对象?
算法:
引用计数法(reference counting):问题:循环引用;
标记清除算法(mark-sweep),问题:空间碎片,尤其是大对象的内存分配,不连续的内存空间的工作效率要低于连续的空间。
复制(copy),代价:内存折半;其高效性建立在存活对象少、垃圾对象多的情况。
标记压缩(mark-compact),将所有的存活对象压缩到内存的另一侧;
增量(incremental collecting),垃圾回收时,stw,所有线程挂起;故,垃圾回收与应用程序交替执行;但是线程切换和上下文转换的消耗,使得GC的成本提高,吞吐量下降。
分代(generational collecting)
垃圾收集器的类型
按线程数分,串行GC和并行GC;
工作模式分,并发式和独占式;
碎片处理方式分,压缩和非压缩;
工作的内存区间分,新生代和老年代;
评价GC策略的指标:
吞吐量
垃圾回收器负载
停顿时间
垃圾回收频率
反应时间
堆分配
新生代串行收集器
第六章 性能调优工具
Linux命令行
top
sar
vmstat
iostat
pidstat
Windows工具
任务管理器
perfmon性能监控工具
process explorer
pslist
JDK命令行
jps
jstat
jmap
jstack
jinfo
jhat
jstatd
hprof
JConsole
Visual VM多合一工具
Visual VM对OQL的支持
MAT内存分析工具
MAT对OQL的支持
JProfile