目标检测 之 R-CNN 超全详解
在上一篇博客中介绍了目标检测的概念,发展历程,基本思路和步骤,以及目标检测精准度的评价指标,在这一篇博客中我们将着重介绍几个主流的 目标检测 算法。
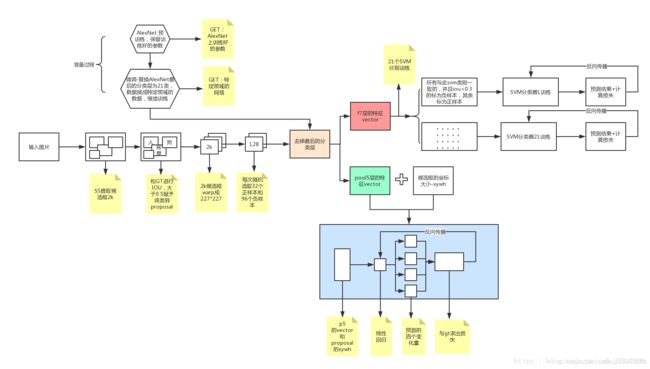
五. R-CNN 算法
(图片来自网络)
5.1 简介
R-CNN的全称是Region-CNN,它可以说是是第一个成功将深度学习应用到目标检测上的算法。 传统的目标检测方法大多以图像识别为基础。 一般可以在图片上使用穷举法选出所所有物体可能出现的区域框,对这些区域框提取特征并使用图像识别方法分类, 得到所有分类成功的区域后,通过非极大值抑制(Non-maximumsuppression)输出结果。
R-CNN遵循传统目标检测的思路,同样采用提取框,对每个框提取特征、图像分类、 非极大值抑制四个步骤进行目标检测。只不过在提取特征这一步,将传统的特征(如 SIFT、HOG 特征等)换成了深度卷积网络提取的特征。R-CNN 体框架如图所示。
对于一张图片,R-CNN基于selective search方法大约生成2000个候选区域,然后每个候选区域被resize成固定大小,并送入一个CNN模型中,最后得到一个特征向量。然后这个特征向量被送入一个多类别SVM分类器中,预测出候选区域中所含物体的属于每个类的概率值。每个类别训练一个SVM分类器,从特征向量中推断其属于该类别的概率大小。为了提升定位准确性,R-CNN最后又训练了一个边界框回归模型,通过边框回归模型对框的准确位置进行修正。

5.2 R-CNN 的主要思路


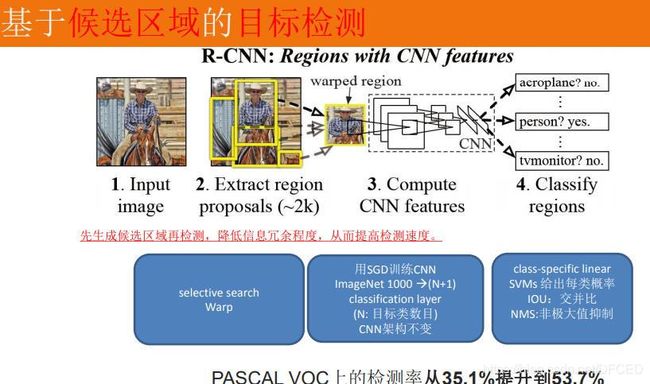
1.利用候选区域与 CNN 结合做目标定位
借鉴了滑动窗口思想,R-CNN 采用对区域进行识别的方案。
具体是:
- 给定一张输入图片,从图片中提取 2000 个类别独立的候选区域。
- 对于每个区域利用 CNN 抽取一个固定长度的特征向量。
- 再对每个区域利用 SVM 进行目标分类。
(图片来自网络)
5.2 提取候选框用到的算法
滑动窗口算法/Sliding Window Algorithm
在滑动窗口方法中,我们在图像上滑动一个框或窗口来选择一个区域,并使用目标识别模型对窗口覆盖的每个图像块进行分类。这是一个穷尽搜索整个图像的对象。我们不仅需要搜索图像中所有可能的位置,还得在不同的尺度上搜索。这是因为物体识别模型通常是在特定的尺度(或范围)上进行训练的。这将对成千上万的图像块进行分类。
问题并没有到此为止。滑动窗口方法对于固定的纵横比对象,例如人脸或行人是很好的。图像是三维物体的二维投影,对象特征,如纵横比和形状根据所拍摄图像的角度而显著变化。滑动窗口的方法因为需要搜索多个纵横比,因此变得非常昂贵。
区域建议的算法/Region Proposal Algorithms
我们目前已经讨论过的问题可以用区域建议算法来解决。这些方法将图像作为输入和输出边界框,对应于图像中最可能成为对象的所有子区域。这些区域建议可能是嘈杂的,重叠的,可能不完全包含对象,但在这些区域建议中,将有一个与图像中的实际对象非常接近的建议。然后,我们可以使用对象识别模型对这些提议进行分类。具有高概率分数的区域建议是对象的位置。
滑动窗口算法/Sliding Window Algorithm
在滑动窗口方法中,我们在图像上滑动一个框或窗口来选择一个区域,并使用目标识别模型对窗口覆盖的每个图像块进行分类。这是一个穷尽搜索整个图像的对象。我们不仅需要搜索图像中所有可能的位置,还得在不同的尺度上搜索。这是因为物体识别模型通常是在特定的尺度(或范围)上进行训练的。这将对成千上万的图像块进行分类。
问题并没有到此为止。滑动窗口方法对于固定的纵横比对象,例如人脸或行人是很好的。图像是三维物体的二维投影,对象特征,如纵横比和形状根据所拍摄图像的角度而显著变化。滑动窗口的方法因为需要搜索多个纵横比,因此变得非常昂贵。
区域建议的算法/Region Proposal Algorithms
我们目前已经讨论过的问题可以用区域建议算法来解决。这些方法将图像作为输入和输出边界框,对应于图像中最可能成为对象的所有子区域。这些区域建议可能是嘈杂的,重叠的,可能不完全包含对象,但在这些区域建议中,将有一个与图像中的实际对象非常接近的建议。然后,我们可以使用对象识别模型对这些提议进行分类。具有高概率分数的区域建议是对象的位置。
目前提出了几种区域建议方法,如
1. Objectness
2. Constrained Parametric Min-Cuts for Automatic Object Segmentation
3. Category Independent Object Proposals
4. Randomized Prim
5. Selective Search
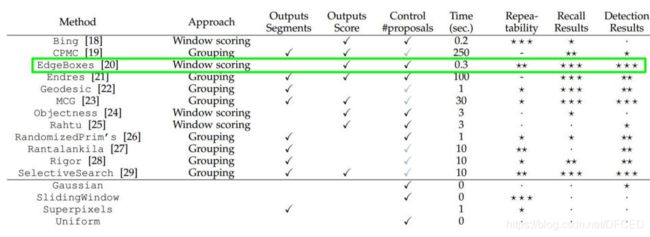
在所有这些区域建议方法中,选择性搜索是最常用的,因为它速度快,召回率高。
各个算法的性能比较
选择性搜索的具体算法(区域合并算法)
什么是选择性搜索?
选择性搜索是一种用于目标检测的区域推荐算法。它的设计速度快,召回率高。它是根据颜色、纹理、大小和形状的兼容性,计算相似区域的层次分组。
选择性搜索开始了基于利用图由Felzenszwalb和Huttenlocher分割方法的像素的图像分割。该算法的输出如下所示。右边的图像包含用纯色表示的分段区域。

我们可以在这个图像中使用分段部分作为区域建议吗?答案是否定的,有两个原因可以解释为什么我们不能做到这一点:
1. 原始图像中的大多数实际对象包含2个或多个分段部分。
2. 用这种方法不能为被遮挡的物体提出建议,例如杯子覆盖的盘子或装满咖啡的杯子。
如果我们试图通过进一步合并相似的相邻区域来解决第一个问题,我们将得到一个覆盖两个对象的分段区域。完美的分割不是我们的目标。我们只是想预测许多区域的建议,其中一些建议应该与实际对象有很高的重叠。选择性搜索使用oversegments Felzenszwalb Huttenlocher的方法作为初始种子。


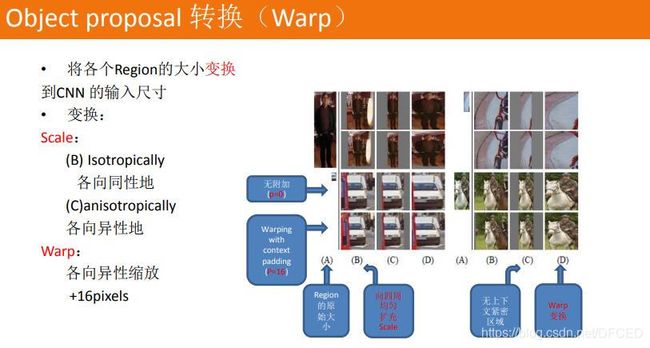
5.3 候选区域转换(Warp)
更加出色的方法-----SPP-Net

在此之前,所有的神经网络都是需要输入固定尺寸的图片,比如224224(ImageNet)、3232(LenNet)、96*96等。这样对于我们希望检测各种大小的图片的时候,需要经过crop,或者warp等一系列操作,这都在一定程度上导致图片信息的丢失和变形,限制了识别精确度。而且,从生理学角度出发,人眼看到一个图片时,大脑会首先认为这是一个整体,而不会进行crop和warp,所以更有可能的是,我们的大脑通过搜集一些浅层的信息,在更深层才识别出这些任意形状的目标。
SPP-Net对这些网络中存在的缺点进行了改进,基本思想是,输入整张图像,提取出整张图像的特征图,然后利用空间关系从整张图像的特征图中,在spatial pyramid pooling layer提取各个region proposal的特征。
crop和warp
crop和warp
一个正常的深度网络由两部分组成,卷积部分和全连接部分,要求输入图像需要固定size的原因并不是卷积部分而是全连接部分。所以SPP层就作用在最后一层卷积之后,SPP层的输出就是固定大小。
SPP-net不仅允许测试的时候输入不同大小的图片,训练的时候也允许输入不同大小的图片,通过不同尺度的图片同时可以防止overfit。
相比于R-CNN提取2000个proposal,SPP-net只需要将整个图扔进去获取特征,这样操作速度提升了100倍左右
5.4 标注数据少怎么办?----迁移学习

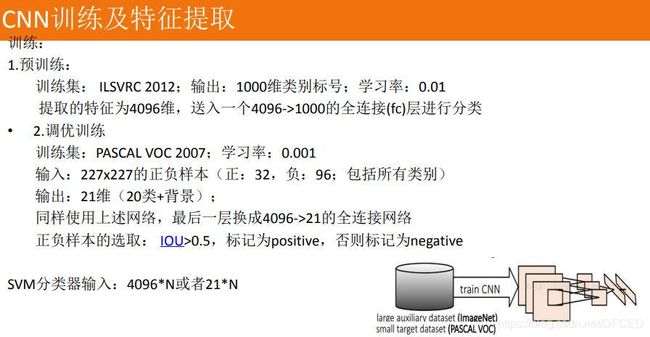

5.5 训练 SVM 分类器


(图片来自网络)
5.6 Bounding box
(1) 一开始会有预测的边框值输入。原来的分类问题只是输入一张图,但是现在对于输入的图还有它在原图中的位置信息。比如滑动窗口、RCNN中selective search给出的区域提案等,产生用于分类判断的区域P
(2) 输入的图会通过卷积网络学习提取出特征向量ϕ5§
(3) 目标检测的一个目标是希望最后的bounding box§和ground truth(G)一致,但是实现方法并不是学习坐标,而是学习变形比例:包括两个部分,一个是对边框(x, y)进行移动,一个是对边框大小(w, h)进行缩放

如何判别哪些矩形框没用?----NMS:非极大值抑制
5.7 位置精修
位置精修: 目标检测问题的衡量标准是重叠面积:许多看似准确的检测结果,往往因为候选框不够准确,重叠面积很小。故需要一个位置精修步骤。
回归器:对每一类目标,使用一个线性脊回归器进行精修。正则项λ=10000。 输入为深度网络pool5层的4096维特征,输出为xy方向的缩放和平移。

训练样本:判定为本类的候选框中和真值重叠面积大于0.6的候选框。
5.8 R-CNN 面临的挑战

1.训练过程是多级流水线。R-CNN首先在目标候选框上使用log损失函数微调一个卷积网络。然后,它将卷积神经网络得到的特征送入SVM。 这些SVM作为目标检测器,通过微调后替代softmax分类器。 在第三个训练阶段,学习边界框回归。
2. 训练在时间和空间上是的开销很大。对于SVM和边界框回归训练,从每个图像中的每个目标候选框提取特征,并写入磁盘。对于非常深的网络,如VGG16,这个过程在单个GPU上需要2.5天(VOC07 trainval上的5k个图像)。这些特征需要数百GB的存储空间。
3. 目标检测速度很慢。在测试时,从每个测试图像中的每个目标候选框提取特征。用VGG16网络检测目标每个图像需要47秒(在GPU上)。
参考:
复旦大学 《深度学习》