深度强化学习 - 无人驾驶自行车
最近突发奇想做了个无人驾驶自行车,视频:无人驾驶自行车演示。本文讲述用深度强化学算法(DRL),unity环境制作完全基于物理引擎的无人驾驶自行车的流程。因为物理引擎可以替换,但思路和算法大同小异,因此该文章主要面向研究强化学习的人,而不是unity开发者。因此无人驾驶自行车的环境我会贴出gym环境的形式而不是unity工程的形式供大家把玩。
首先说句题外话,有很多哥们问我:“你这个做的有点意思,但是有啥用呢?” 是的,我做的这个是虚拟环境中实现的,但是目前很多强化学习在现实中的应用都是先在虚拟环境加速训练,再迁移到现实,比如anymal机器狗,树枝做的机器人等等。甚至,像openai的Dactyl机械手,直接虚拟环境训练好都不用微调,就能在现实中用,简直天秀。其思想就是:与其尽可能的模拟真实,不如在与真实环境较为相似的随机环境中训练,就能适应真实环境。我觉得用这种思路,虚拟环境+DRL会引发一轮新的革命。以上都是我胡诌的,请忽略(*゜ー゜*)。
1.环境搭建
虽然环境的搭建是用unity和C#写的,只有后端是python训练的,但是了解了环境才好设置状态,动作,奖励函数,所以这部分还是有用的。
1.1 基于物理的自行车
DRL研究者不一定熟悉unity引擎,我下面首先对unity环境的搭建进行简要介绍。
unity是一个专业的3d游戏引擎,有完整的物理系统。那么对于无人驾驶自行车,我们首先需要一辆基于物理运动的车。unity有一个内置的用于赛车游戏的车轮组件:Wheel Collider,它的参数除了图中截到的车轮重量,车轮半径,悬架弹力设置等等,还有前向,侧向摩擦等设置,该组件达到的效果就是能较为真实的模拟各种车轮。对于自行车,对各个参数设置一个较为合理的数值,比如车轮半径0.5m。
(1)
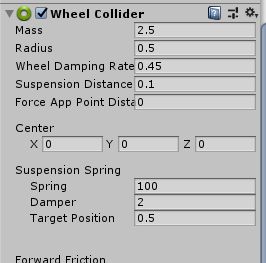
而这只是一个轮子的,自行车有两个轮子,那就需要两个Wheel Collider,在unity项目中,也就是front(前轮)和rear(后轮)
(2)

如果你使用的是其他游戏引擎,一般都会有相应的赛车制作方法,方法大同小异。甚至如果真没有相关支持,可以自己写一个赛车物理系统,虽然这很麻烦(虽然不用从袁隆平说起,至少也要从发动机,一系列计算后得到车轮的扭矩),如果你真的需要在一些小众的虚拟环境中自己撸出来整个赛车物理,可以参考gameinstitute 的GI racing教程。
在unity中,做好的自行车长这个样子:
(3)
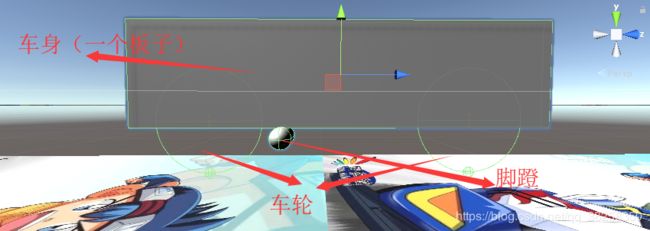
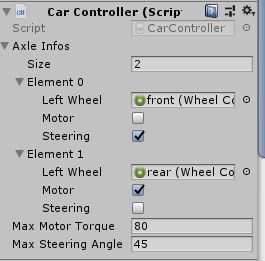
其中脚蹬没有实际用处,只是我抖个机灵;车身用一个板子简单的模拟,并且用这个板子来判断与其他物体的碰撞;而两个车轮各有一个wheel collider组件。然后,我们还需要一个定义自行车属性的脚本,如图中:设定了前轮(图中是Left wheel)勾选了steering(可以转向),后轮勾选了驱动(自行车当然是后轮驱动)。
(4)
如果你对如何制作自行车物理仍然听的有点晕,没关系,unity官网有一个教你五分钟搭建一个四轮车的教程,而你把四轮车拆掉两个轮子,余下两个轮子挪到中间,就成了自行车。
1.2 人体重心模拟
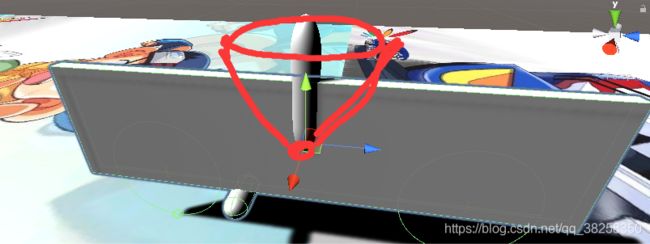
但是这样自行车就能不倒吗?我们人类骑车的话,身体的重心是在不停调整的,与车速,车倾斜角度等配合,达到了车不倒的效果,因此,在这个无人驾驶自行车中,除了车,还需要一个可移动的重心。当然,如果不用和人骑车类似的控制方式,也不是说就骑不了,比如谷歌在愚人节发布的吹牛逼版自行车,清华学霸发明的真 · 无人驾驶,还有泰国学霸版的,只不过我想玩这种靠重心的哈哈。这个重心的移动应该是靠力矩(就像人的腰部关节的扭矩力,让人身体各种倾斜),因此我在车上加了一个类似于机械臂的物体,该物体模拟人的倾斜,从而改变人与车整体的重心。机械臂以底端为关节点旋转,只能在图中红线所画的圆锥范围内(与垂直轴夹角不超过45度)靠扭矩力移动。机械臂利用了unity的configurable joint(可配置关节)实现,可配置关节比较复杂,我就不讲了,反正作用就和mujoco里的机械臂一样一样的,靠扭矩力(底端的关节点)移动。
(5)
1.3 其他
自行车和模拟人体重心的部分都做好了,剩下的就是车要交互的场景了,如果你看了开头的视频,里面展示了两个环境,一个是直线加速环境,另一个是训练转弯的环境。两个环境中都有一个target(直线环境中为位于终点的黄色物体,弯道环境中为派大星)。而自行车需要保持不倒,并且尽快碰到target。由于弯道环境比直线环境训练起来更加困难的多得多得多,因此我在弯道环境多次使用了迁移学习,所以gym版环境就不包含弯道环境了(不用迁移,直接训练弯道环境到达成目标应该是做不到的),只有直线的。
2. 定义DRL的输入与输出。
DRL算法从神经网络的角度看,还是给输入,神经网络吐出输出。输入就是状态,也就是环境中你需要了解的东西,吐出来的就是动作,也就是你在这种状态下该咋办。在无人驾驶自行车这个小项目中,我设置的状态如图:
(6)

图中标号1,代表在世界坐标系下车目前离目标的距离的向量(状态+3),并且用1500m来归一化(因为直线赛道我设置了1500米长,注释里的100m请无视),因为3d环境,所以向量是三维的,也就是已经有三个输入了。
图中标号2,代表车子到赛道中心(1500m长的板子的中心位置,750m处)的向量(+3)。需要说明的是,在后面的弯道环境中,并没有采用这个向量,只有车与目标间的相对位置,角度等。训练时与绝对坐标点无关,车子才能在任意地方都到达target。
图中标号3,当前时刻车速,也是向量(+3)。
图中标号4,当前车的角速度,也是向量(+3),考虑角速度是怕自行车逮虾户(漂移),在真的不确定某个状态需不需要时,我一般都会加上,多加个状态,结果又不会变多差,我觉得这不是造原型时需要过度考虑的。
图中标号5,车身的前向在世界坐标中的三维向量(也就是人坐车上脸超前的方向)(+3),该向量与标号1的向量做点积,可以得到两向量的夹角,这个信息是很有用的。
图中标号6,车子自身坐标的上方向,在世界坐标下的向量值(也就是车坐下面那根棍子,方向朝着车座,的单位向量)(+3)
图中标号7,车头相对于车身的旋转角度(左右旋转我都限制了不超过45度)(+1)。
图中标号8,当前时刻车子是否碰着地面(+1)
图中标号9,当前自行车后轮的扭矩力大小(动力,我设置的扭矩不超过80N)(+1)
图中标号10,11,14共同表示了重心的当前的状态(+3)。简单解释的话,图中红色和黄色代表了人在以车身为坐标系下的旋转,两个方向都只能左右倾斜45度,也就是每个方向有90度活动空间,0和1说明是归一化了,因此,图中正坐在车上时,状态10和11都是0.5. 而状态14代表了机械臂的扭矩力的大小(图中柱子的底端用力)。
(7)
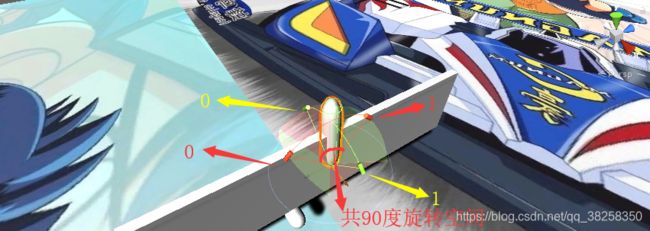
图中标号12表示机械臂的在世界坐标下的旋转角度(由四元数表示,因此+4)
图中标号13表示机械臂当前的角速度(+3)
以上,共31个状态。我猜看到这,大家疑问最多的问题就是:你干嘛不用卷积,直接把图像当输入。(⊙﹏⊙)因为,我这是游戏引擎,我能直接得到上面这些信息,我干嘛还要用图像再去推断我车子现在倾斜多少,距离目标多远这些信息呢,对于车速等信息,还要将多帧图片堆叠,还要用RNN来表征,这使问题更复杂了。在做这个车时,我自己也没谱能否训练好,所以自然会去选最容易训练好的状态信息。现在我确信车子能训练好了,倒是可以用CNN+RNN当输入状态试试看(但是我懒?)
输入说完了,那么神经网络的输出动作呢?这就比较直觉了,输出动作共5个:
1.车头旋转角度的增量(即该时刻下车头应该增加的角度,限制了最大增量一秒100度(-100到+100),才真实嘛)
2.后轮扭矩的增量(一秒最多增加80N)
动作3,4,5共同决定了该时刻人的腰部准备往哪个方向用力,腰部用多大的力。动作3代表了图(7)中红色扇形中的某个位置(神经网络估计出的),相应的,动作4代表了黄色扇形中的一个位置,3,4共同确定了一个人想在此时到达的目标位置,而动作5表示了为了到该位置,人腰部目前用的力的大小(这可真真实?)
3.奖励函数的设置
环境搭好了,输入输出也都设置好了,那么就到了比较有意思又见仁见智的奖励函数设置环节啦。不管是直线加速环境还是拐弯训练环境,如果都只在碰到终点时给予奖励,倒了就失败,那真的是打死它它都训练不好,这是标准的稀疏奖励问题。那么一个比较常用的手段就是reward shaping,也就是除了最终奖励之外,我们造一些奖励引导AI达到目标。在直线环境中,我给AI的附加附加奖励是当车与目标的距离变短了,就给它奖励,这样它就会想尽办法尽量靠近目标。其他奖励就是,如果掉出板子,就-1,直接结束;如果车身倾斜角度大于45度,就-1,直接结束;如果碰到目标,就+1,结束。
而弯道环境更加复杂,只用reward shaping都不行,我还多次用了课程学习(其实就是迁移学习),如图:
(8)
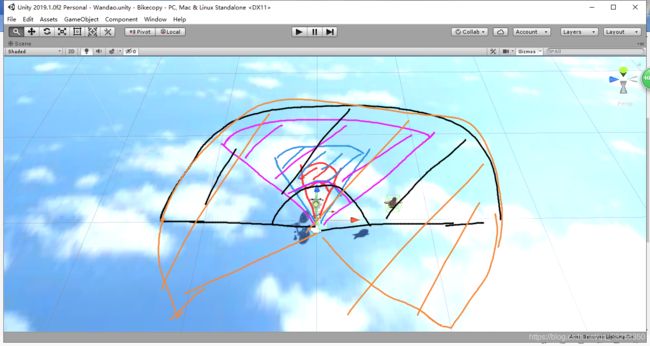
在弯道环境中,如果一开始就让目标在车一定半径内随机位置出现,训练自行车,基本上训练不好,因为奖励太稀疏了,自行车需要不倒,并控制拐弯,还要拐好角度,最终才能碰到目标。因此我将整个训练分成了多个阶段性任务。首先,目标只会出现在红色扇形区域,并且给车一定的初速度,这样车比较容易碰到目标;训练好之后(可以为训练了足够轮数,或者reward达到了目标值),将目标区域扩大为蓝色区域,并减小初始车速;训练好后再逐个变到紫,黑,黄...区域,直至360度,同时半径也在增大,初始车速在减小。最终,一定半径内,从0车速出发,360度内,车都能碰到目标。
4.环境训练
我其实只是自己做着玩的[]~( ̄▽ ̄)~*,所以算法部分就直接用的unity自带的ppo算法训练了。由于动作是连续值,dqn类不适合这个任务,如果你喜欢,可以用其他rl算法来训练。我把环境封装了下(可视化的呦,可以看到自己训练好后的无人驾驶自行车),你可以从两种方式中任选一种来自己训练自行车:
方式一:unity自带的训练方式
该方式需要下载github中的BikeScene_train压缩包。先安装mlagents(unity的机器学习工具包),安装方式很简单,建立一个新的python3.6的虚拟环境,然后pip install mlagents就完了,或者你也可以看官方的安装教程。在该环境下,读取环境,获取状态和动作的逻辑都在nogym.ipynb里,你可以添加自己的算法来训练自行车。官方参考脚本 需要注意的是,在训练时,请保持ipynb中train_mode为True,表示处于训练模式,训练模式下游戏画面只有80*80像素,是为了加速训练而不是为了让人看;而训练好后,请设置train_mode为False,表示处于推理阶段,推理阶段的画面会自动为1280*720分辨率,并且时间也是正常速度,可以把玩自己的自行车。
方式二:gym环境
该方式同样需要安装mlagents(建立一个新的python3.6的虚拟环境,然后pip install mlagents就完了,或者你也可以看官方的安装教程。)。在gym环境下需要同时下载github中的BikeScene_train压缩包和BikeScene_inferer压缩包。该环境比较适合熟悉gym的童鞋,参考脚本为github中的gym.ipynb. 至于你想用openai的算法还是dopamine的算法还是自己写的算法,都可以,可以参考官方示例。在训练时加载BikeScene_train里的exe(80*80分辨率),训练好后,修改路径为BikeScene_inferer里的exe(1280*720分辨率),就可以看到训练好的自行车了。
最后,可以自己玩的自行车:
我还做了个可以玩的环境,就是github里的BikeScene_playable压缩包,解压后,里面的exe是可以双击运行的。按数字键0是我训练了500万步的AI自己控制的自行车(其实没训练好,有时会跌倒);按数字键1是玩家自己控制自行车:w为蹬的力最大,A和D控制车头的左右,上下左右箭头控制中心(中间那个棍子)的移动;按数字键2是固定了车子的Z轴旋转之后,玩家控制自行车,控制按键同模式2. 因为其实人类是玩不转模式2的,所以我加了模式3ㄟ( ▔, ▔ )ㄏ 这估计是我做过的最辣鸡的游戏了( ̄_ ̄|||) 对了,我忘加退出游戏的选项了,请点 × 退出?。
如果有啥我没讲清楚的,可以加微信dada_biubiubiu ,之后做了好玩的环境我都会打包发布?。