Directx11渲染管线概述
渲染管线(rendering pipeline)是指:在给定一个3D场景的几何描述及一架已经确定位置和方向的虚拟摄像机时,根据虚拟摄像机的视角生成2D图像的一系列步骤。以下文章将会具体描述这些步骤(阶段)。
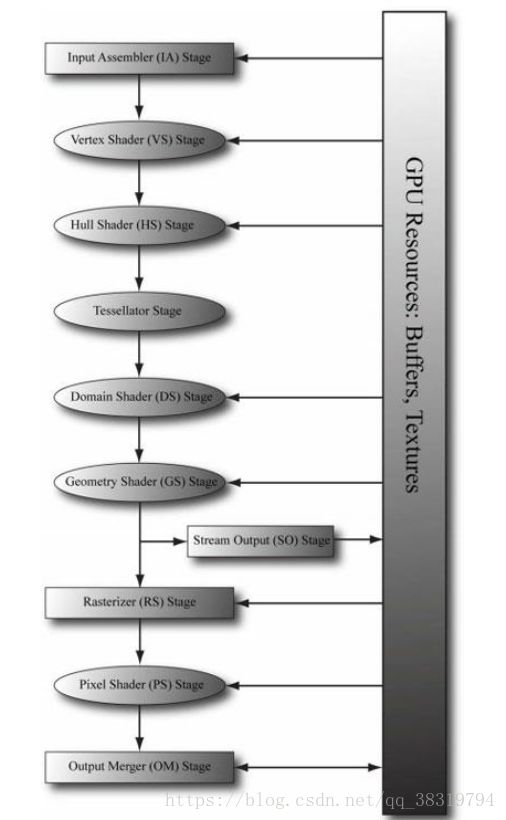
1.输入装配阶段
输入装配(Input Assembler,简称IA)阶段从内存读取几何数据(顶点和索引)并将这些数据组合为几何图元(例如三角形和直线)。
1.1顶点
从数学上来说,三角形的顶点即边的交点;线段的顶点即端点;点的顶点即为本身。
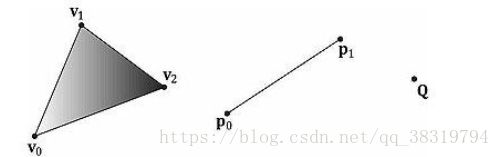
上图说明顶点只是几何图元中一个特殊的点。但在D3D中,顶点具有更多含义。本质上,D3D中的顶点有空间位置和各种附加属性组成。(此处不具体展开了就)。
1.2图元拓扑
顶点是以顶点缓冲区(D3D数据结构)的形式绑定到图形管线的。顶点缓冲区只是在连续的内存中存储了一个顶点列表。但并不知道这些顶点是如何组织的。所以要通过制定图元拓扑来告诉D3D以何种方式组成几何图元。
void ID3D11Device::IASetPrimitiveTopology(
D3D11_PRIMITIVE_TOPOLOGY Topology);
typedef enum D3D11_PRIMITIVE_TOPOLOGY
{
D3D11_PRIMITIVE_TOPOLOGY_UNDEFINED = 0,
D3D11_PRIMITIVE_TOPOLOGY_POINTLIST = 1,
D3D11_PRIMITIVE_TOPOLOGY_LINELIST = 2,
D3D11_PRIMITIVE_TOPOLOGY_LINESTRIP = 3,
D3D11_PRIMITIVE_TOPOLOGY_TRIANGLELIST = 4,
D3D11_PRIMITIVE_TOPOLOGY_TRIANGLESTRIP = 5,
D3D11_PRIMITIVE_TOPOLOGY_LINELIST_ADJ = 10,
D3D11_PRIMITIVE_TOPOLOGY_LINESTRIP_ADJ = 11,
D3D11_PRIMITIVE_TOPOLOGY_TRIANGLELIST_ADJ = 12,
D3D11_PRIMITIVE_TOPOLOGY_TRIANGLESTRIP_ADJ= 13,
D3D11_PRIMITIVE_TOPOLOGY_1_CONTROL_POINT_PATCHLIST = 33,
D3D11_PRIMITIVE_TOPOLOGY_2_CONTROL_POINT_PATCHLIST = 34,
. . .
D3D11_PRIMITIVE_TOPOLOGY_32_CONTROL_POINT_PATCHLIST = 64,
} D3D11_PRIMITIVE_TOPOLOGY;
以下图片为部分图元拓扑的示例,选择对应的标志即可选择使用的图元。
 |
 |
1.3索引
先说一个结论,三角形是构成3D物体的基本单位。下面的代码示范了如何使用三角形列表来构建四边形和八边形的顶点数组(每三个顶点构成一个三角形)。
Vertex quad[6] ={
v0, v1, v2, // Triangle0
v0, v2, v3, // Triangle1
};
Vertex octagon[24] ={
v0, v1, v2, // Triangle0
v0, v2, v3, // Triangle1
v0, v3, v4, // Triangle2
v0, v4, v5, // Triangle3
v0, v5, v6, // Triangle4
v0, v6, v7, // Triangle5
v0, v7, v8, // Triangle6
v0, v8, v1 // Triangle7
};注意:三角形的顶点顺序非常重要,具体会在之后背面消隐的小节中提到。
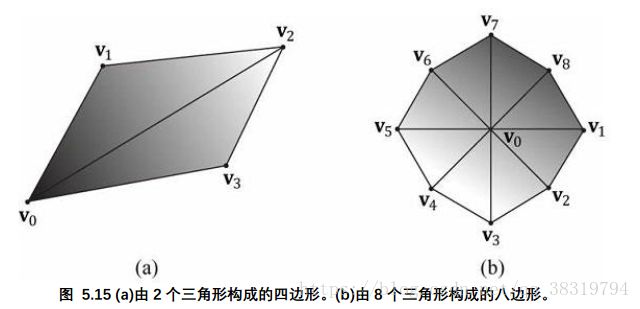
如上图所示,构成3D物体的三角形会共享许多相同同的顶点。这在八边形的V0点表现尤其明显。复制(重复)顶点的数量会随着模型细节和复杂性的提高而骤然上升。这样就会浪费大量的资源(内存)。
三角形带可以在一定程度上解决复制顶点的问题,然而三角形带组织起来比较麻烦,难度很大。相比之下三角形列表就非常灵活了。如果能找到一种方法,即移除复制顶点,又保留三角形列表的灵活性,就很爽了。而索引就可以解决这个问题。
它的原理是:创建一个顶点列表和一个索引列表。顶点列表包含所有唯一的顶点,而索引列表包含指向顶点列表的索引值,这些索引定义了顶点以何种方式组成三角形。回顾上图,四边形顶点列表可以这样创建:
Vertex v[4] = {v0, v1, v2, v3};而索引列表需要定义如何将顶点列表中的顶点放在一起,构成两个三角形。
UINT indexList[6] = {0, 1, 2, // Triangle0
0, 2, 3}; // Triangle 1 以上的索引列表含义为:使用顶点v[0],v[1],v[2]构成三角形0,使用顶点v[0],v[2],v[3]构成三角形1。
与之类似,八边形的顶点列表和索引列表可以如此创建:
//顶点列表
Vertex v[9] = {v0, v1, v2, v3, v4, v5, v6, v7, v8};
//索引列表
UINT indexList[24] = {
0, 1, 2, // Triangle 0
0, 2, 3, // Triangle 1
0, 3, 4, // Triangle 2
0, 4, 5, // Triangle 3
0, 5, 6, // Triangle 4
0, 6, 7, // Triangle 5
0, 7, 8, // Triangle 6
0, 8, 1 // Triangle7
};总结一下,就是把顶点的复制转嫁给了索引,而索引都是基本的整数数值类型,就算大量复制也不会使用多少内存。而通过适当的顶点缓存排序,图形硬件也不必重复处理顶点(绝大多数情况下)。
2.顶点着色器阶段
在完成图元装配后,顶点将被送往顶点着色器(vertex shader)阶段。顶点着色器可以被看成是一个以顶点作为输入输出的函数(输入未经着色的原始顶点,输出着色后的顶点)。我们可以概念性地认为在硬件上执行了如下代码。
for(UINT i = 0; i < numVertices; ++i)
outputVertex[i] = VertexShader(inputVertex[i]); 顶点着色器函数由我们自己编写,它会在GPU上运行,所以速度非常快。
许多效果,比如变换(transformation)、光照(lighting)、和置换贴图映射(displacement mapping)都是由顶点着色器来实现。在顶点着色器中,我们不仅可以访问输入的顶点数据,也可以访问在内存中的纹理和其他数据,比如变换矩阵的场景和灯光。
2.1局部空间和世界空间
创建3D场景时,我们往往不会在世界坐标系中直接建立物体(这样太麻烦了,太难了),而是在便于操作的局部坐标系中建立物体。局部坐标系的原点接近于物体中心,坐标轴的方向和物体的方向也是对齐的,所以操作起来会很方便。
在局部空间(坐标系)中完成物体的创建后,再把它放到(转换到)世界空间(坐标系)中,这个转换操作也非常简单(以下会提到)。当所有物体都从局部空间变换到世界空间,这些物体就位于同一个坐标系(世界坐标系)中了。

根据模型自身的局部坐标系定义模型,有以下几点好处。
1.简单易用,操作方便。坐标系原点通常与物体中心对齐,坐标轴也是对齐的。非常便于描述。
2.便于在多个场景中复用,不用每次都重新定义。
3.便于在单个场景中复用,简单来说实例化操作便捷。
世界矩阵描述的是一个物体的局部空间相对于世界空间的原点位置和坐标轴方向,这些坐标可以存放在一个行矩阵中。
设Qw=(Qx,Qy,Qz,1)、uw=(ux,uy,uz,0)、vw=(vx,vy,vz,0)、ww=(wx,wy,wz,0)分别表示局部空间相对于世界空间的原点、x轴、y轴、z轴的齐次坐标,从局部空间到世界空间的坐标转换矩阵为:
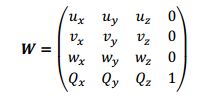
W=SRT S R T分别为尺度变化矩阵,旋转变化矩阵,平移矩阵。
2.2观察空间
为了生成场景的2D图像,我们必须在场景中放置一架虚拟摄像机。虚拟摄像机指定了所要生成的2D图像所显示的场景范围。把一个局部坐标系(观察空间)附加在摄像机上,该坐标系以摄像机的位置为原点,观察方向为z轴正方向,右侧为x轴,上方为y轴。在渲染管线的后续阶段中,使用观察空间来描述顶点比世界空间要方便得多。从世界空间变换到观察空间的坐标变换称为观察变换,相应的矩阵称为观察矩阵。

从观察空间(本质上也是个局部空间)到世界空间的变换矩阵就是上述的W。因为观察空间不用考虑尺度变换,故W=RT。显然,从世界空间转换到观察空间的的矩阵就是W的逆矩阵,即V=inv(W)=inv(RT)=inv(T)inv(R)。
经过简单的推导,可知观察矩阵为

现在介绍一种更直观的方法,通过指定摄像机的位置、目标点和世界“向上”向量来创建摄像机坐标系。

学过线代的都知道,显然有w

然后u
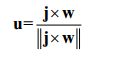
最后v
![]()
XNA库提供了如下函数,根据以上描述计算观察矩阵。
XMMATRIX XMMatrixLookAtLH( // Outputs resulting view matrix V
FXMVECTOR EyePosition, // Input camera position Q
FXMVECTOR FocusPosition, // Input target point T
FXMVECTOR UpDirection); // Input world up vector j 通常,y就是向上的,即(0,1,0)。举例说明,假设摄像机相对于世界空间的位置为(5,3,-10),目标点为世界原点(0,0,0)。可以使用一下代码创建观察矩阵。
XMVECTOR pos = XMVectorSet(5,3,-10,1.0f);
XMVECTOR target = XMVectorZero();
XMVECTOR up = XMVectorSet(0.0f,1.0f,0.0f,0.0f);
XMMATRIXV = XMMatrixLookAtLH(pos,target,up);2.3投影与齐次裁剪空间
相机可见范围可通过一个平截头体(frustum)来描述,如下图
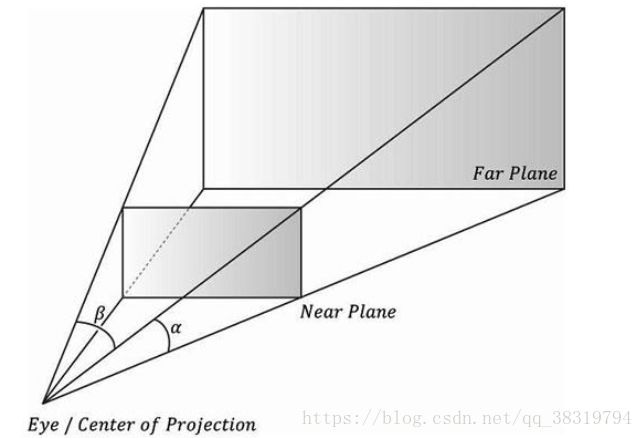
下一个任务就是把平截头体内的3D物体投影到2D投影窗口上。将3D顶点v变换到它的投影线与2D投影平面相交的点v'上;我们称v'为v的投影。对一个3D物体的投影就是对组成该物体的所有顶点的投影。

2.3.1定义平截头体
可以使用如下参数定义平头截体:近平面n(与摄像原点距离为n)、远平面f(与摄像原点距离为f)、垂直视域角α和横纵比r。
侧视图如下(默认半高为1 即高为2)
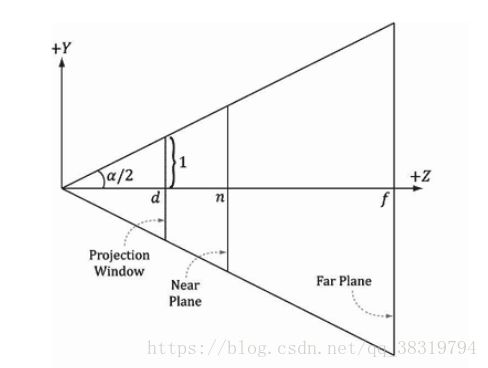
俯视图如下

可以得到
![]()
简单的几何证明就懒得写了,学过三角函数的都懂。。。
2.3.2对顶点进行投影
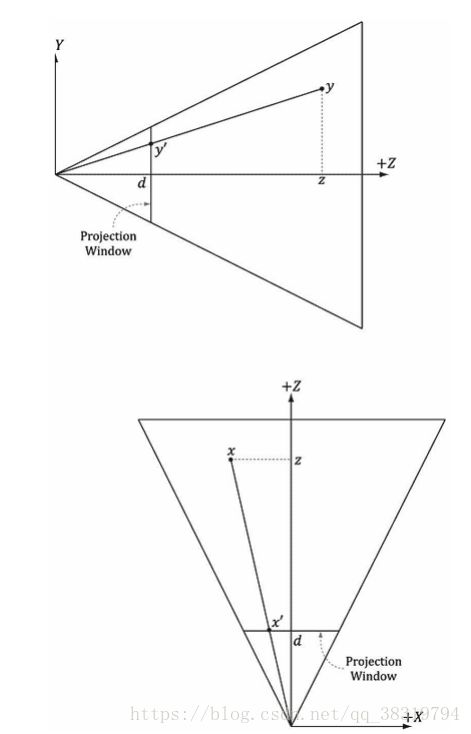
参考以上图片。给出一个点(x,y,z)求它在投影平面z=d上的投影点(x`,y`,d)。通过相似三角形很容易得到

2.3.3规范化设备坐标(NDC)
上一节中我们有提到一个关键参数横纵比r。但是不同的硬件纵横比是不同的,我们必须为硬件指定纵横比,否则无法执行运算。如果消除对横纵比的依赖,会使相关的运算变得简单。为了解决这个问题,可以将x坐标从[-r,r]区间缩放到[-1,1]区间:
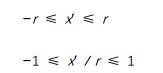
在映射之后,x、y坐标被称为规范化设备坐标(normalized device coordinates,简称NDC)(z坐标还没有被规范化)。
那就可以修改之前的投影公式,直接使用NDC空间中的x,y投影坐标:

其实说了很多废话,简单的总结一下:NDC空间中,投影窗口高度和宽度都为2。
2.3.4用矩阵来描述投影方程
为了保持一致,我们将用一个矩阵来描述投影变换。不过,上述方程是非线性的(透视除法,即x',y'的分母z),无法用矩阵描述。但可以使用一种技巧将它分为两部分实现:一个线性部分和一个非线性部分。非线性部分要除以z(透视除法)。后面会讲到这个问题,现在只需要知道,我们会因除法操作失去原始的z坐标,所以必须在变换之前保存输入的z坐标。可以利用齐次坐标解决这一问题,将输入的z坐标赋值给输出的w坐标。在矩阵乘法中,将元素[2][3]设为1、[3][3]设为0(从0开始的索引)。
矩阵大致如下:
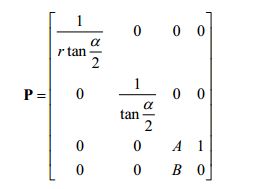
矩阵中的常量A好B在下一节讨论;这项常量用于把输入的z坐标变换到规范化区间。将一个任意点(x,y,z,1)与该矩阵相乘,可以得到:

在与投影矩阵(线性部分)相乘之后,我们要将每个坐标除以z(透视除法;非线性部分),得到最终结果:

2.3.5规范化深度值
在数学概念上,当3D物体投影到平面上,就会丢失z轴的信息(z为常数)。但事实上,我们仍然需要为深度缓存算法提供3D物体的z坐标信息。在实际中,我们会创建一个保序函数把深度坐标(区间为[n,f])映射到一个规范化区间[0,1]。由于该函数是保序的,所以深度值的相对大小可以完整的保留下来。
由上一节我们知道g(z)=A+B/z。若g(z)的区间为[0,1]。显然
在近平面上,有g(n)=A+B/n=0;
在远平面上,有g(f) =A+B/f =1;
可以解得A=f/(f-n) ,B=-fn/(f-n)。
所以,
g(z)=f/(f-n)-nf/(f-n)z
g(z)的曲线图如下
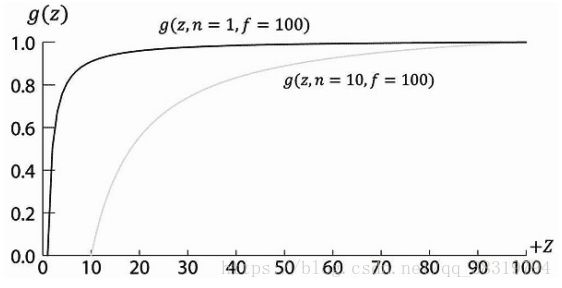
可以看出它是保序且非线性的。而且大部分的取值落在近平面附近。因此,大多数深度值被映射到一个很窄的取值范围内。考虑到计算机处理小数的精度有限,所以建议让近平面和远平面尽可能接近,把深度的精度性问题减小的最低程度。
此时已经可以确定出完整的透视投影矩阵:

在与投影矩阵相乘之后,进行透视除法之前,几何体所处空间称为齐次裁剪空间(homogeneous clip space)或投影空间(projection space)。在透视除法之后,几何体所处的空间称为规范化设备空间(normalized device coordinates,简称NDC)。
2.3.6XMMatrixPerspectiveFovLH
透视投影矩阵P可由如下XNA函数生成:
XMMATRIX XMMatrixPerspectiveFovLH(// returns projection matrix
FLOAT FovAngleY, // vertical field of view angle in radians
FLOAT AspectRatio, // aspect ratio = width / height
FLOAT NearZ, // distance to near plane
FLOAT FarZ); // distance to far plane一下代码片段示范XMMatrixPerspectiveFovLH函数的使用方法。这里,我们将垂直域角设为45°,近平面设为1,远平面设为1000(在观察空间中)
XMMATRIX P = XMMatrixPerspectiveFovLH(0.25f*MathX::Pi,
AspectRatio(),1.0f,1000.0f);横纵比要匹配窗口的横纵比:
float D3Dapp::AspectRatio() const
{
return static_cast(mClientWidth)/mClientHeight;
} 3.曲面细分阶段
曲面细分(Tessellation)是指通过添加三角形的方式对一个网格的三角形进行细分,这些新添加的三角形可以偏移到一个新的位置,让网格的细节更加丰富。
下面是曲面细分的一些优点:
1.我们可以通过曲面细分实现细节层次(level-of-detail,LOD),使靠近相机的三角形通过细分产生更多细节,而远离相机的三角形保持不变。通过这种方式,我们只需要在需要细节的地方使用更多的三角形就行了。
2.我们可以在内存中保存一个低细节(三角形数量更少)的网格,但是可以实时地添加额外的三角形,这样可以节省内存。
3.我们可以在一个低细节的网格上处理动画和物理效果,而只是在渲染时才使用细分过的高细节网格。
4.几何着色器阶段
几何着色器阶段(geometry shader stage)是可选的,这里只做一个简短的概述。几何着色器以完整的图元作为输入数据。例如,当我们绘制三角形列表时,输入到几何着色器的数据是构成三角形的三个点。几何着色器的主要优势是它可以创建或销毁几何体。例如,输入图元可以被扩展为一个或多个其他图元,或者几何着色器可以根据某些条件拒绝输出某些图元。这一点与顶点着色器有明显的不同:顶点着色器无法创建顶点,只要输入一个顶点,那就必须输出一个顶点。几何着色器通常用于将一个点扩展为一个四边形,或者将一条线扩展为一个四边形。
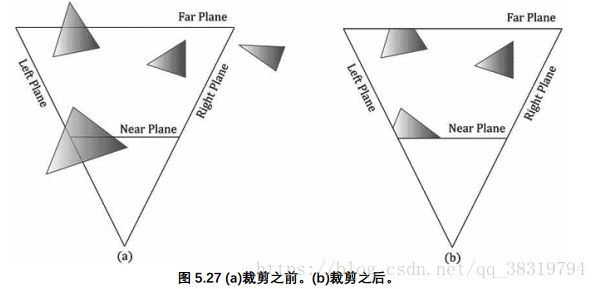
5.裁剪阶段
我们必须完全丢弃在平截头体之外的几何体,裁剪与平截头体边界相交的几何体,只留下平截头体内的部分;
6.光栅化阶段
光栅化(rasterization)阶段的主要任务是为投影后的3D三角形计算像素颜色。
6.1视口变换
在裁剪之后,硬件会自动执行透视除法,将顶点从齐次裁剪空间变换到规范化设备空间(NDC)。顶点进入NDC空间后,构成2D图像的2D x、y坐标就会被变换到后台缓冲区中的一个称谓视口(viewport)的矩形区域内。在该变换之后,x、y坐标讲义像素为单位。通常,视口变换不修改z坐标,因为z坐标还要由深度缓存使用,但是我们可以通过D3D11_VIEWPORT结构体的MinDepth和MaxDepth值修改z坐标的取值范围。MinDepth和MaxDepth取值必须在0和1之间。
6.2背面消隐
一个三角形有两个面。用“左手定则”来区分正反。

3D空间中的大部分物体都是封闭实心物体。摄像机不会看到实心物体朝后的三角形,所以绘制他们是毫无意义的,这就是背面消隐的原理。这可以将所要处理的三角形数量降低到原数量的一半。
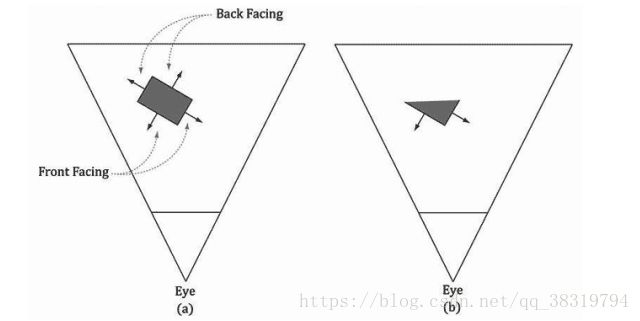
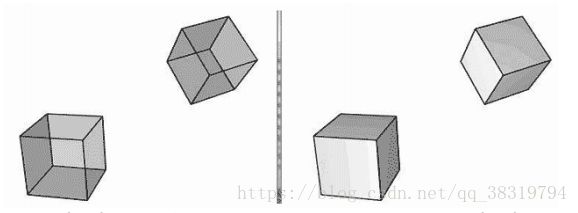
6.3顶点属性插值
之前提到过,顶点除了位置信息,还可以包含其他属性,比如颜色、法线向量和纹理坐标。在视口变换之后,这些属性必须为三角形表面上的每个像素进行插值。顶点深度值也必须进行插值,以使每个像素都有一个可应用于深度缓存算法的深度值。对屏幕空间中的顶点属性进行插值,其实就是对3D空间中的三角形表面进行线性插值;这一工作需要借助所谓的透视校正插值(perspective correct interpolation)来实现。本质上,三角形表面内部的像素颜色都是通过顶点插值得到的。

我们不必关心透视精确插值的数学细节,因为硬件会自动完成这一工作。有兴趣的话,自行查阅。
7.像素着色器阶段
像素着色器是由我们编写的在GPU上执行的程序。像素着色器会处理每个像素片段,它的输入是插值后的顶点属性,由此计算出一个颜色。像素着色器可以非常简单的输出一个颜色,也可以很复杂,例如实现逐像素光照、反射和阴影等效果。
8.输出合并阶段
当像素片段由像素着色器生成之后,它们会被传送到渲染管线的输出合并(output merger,简称OM)阶段。在该阶段中,某些像素片段会被丢弃。未丢弃的像素片段会被写入后台缓冲区。混合(blending)工作是在该阶段中完成的,一个像素可以与后台缓冲区中的当前像素进行混合,并以混合后的值作为该像素的最终颜色。某些特殊效果,比如透明度,就是通过混合来实现的