TOPSIS法
TOPSIS法
1、定义
国内常简称为优劣解距离法。TOPSIS 法是一种常用的综合评价方法,其能充分利用原始数据的信息,其结果能精确地反映各评价方案之间的差距。(多目标决策 TOPSIS 模型)
2、层次分析法的局限性:
(1) 评价的决策层不能太多,太多的话n会很大,判断矩阵和一致矩阵差异可能会很大。
(2) 决策层中指标的数据是已知的。
基本过程
将原始数据矩阵统一指标类型(一般正向化处理)得到正向化的矩阵,再对正向化的矩阵进行标准化处理以消除各指标量纲的影响,并找到有限方案中的最优方案和最劣方案,然后分别计算各评价对象与最优方案和最劣方案间的距离,获得各评价对象与最优方案的相对接近程度,以此作为评价优劣的依据。该方法对数据分布及样本含量没有严格限制,数据计算简单易行。
具体步骤
第一步:将原始矩阵正向化
所谓的将原始矩阵正向化,就是要将所有的指标类型统一转化为极大型指标。(转换的函数形式可以不唯一哦~ )
最常见的四种指标
四种指标如何正向化
1、极小型指标——>极大型指标
极小型指标转换为极大型指标的公式: max − x \max -x max−x,如果所有的元素均为正数,那么也可以使用1/x
具体例子:
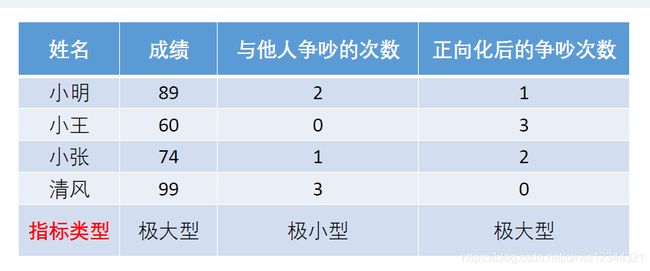
2、中间型指标——>极大型指标
中间型指标:指标值既不要太大也不要太小,取某特定值最好(如水质量评估PH 值)
{ x i } \left\{ x_i \right\} { xi} 是一组中间型指标序列,且最佳的数值为 x b e s t x_{best} xbest,正向化公式 M = max { ∣ x i − x b e s t ∣ } , x i ~ = 1 − ∣ x i − x b e s t ∣ M M=\max \left\{ |x_i-x_{best}| \right\} ,\widetilde{x_i}=1-\frac{|x_i-x_{best}|}{M} M=max{ ∣xi−xbest∣},xi =1−M∣xi−xbest∣
具体例子:
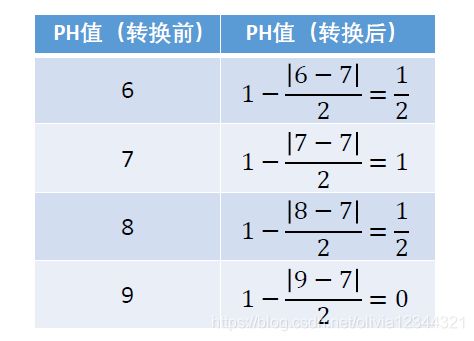
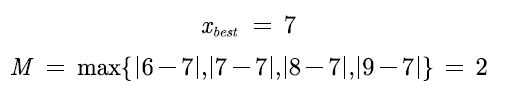
3、 区间型指标——> 极大型指标
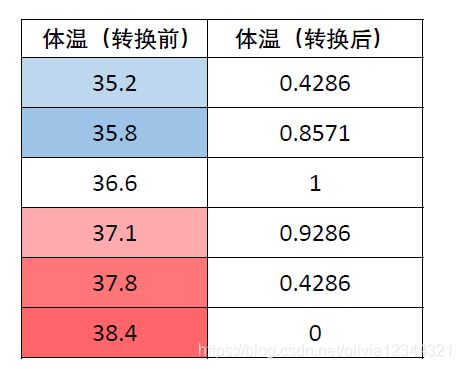
区间型指标:指标值落在某个区间内最好,例如人的体温在36°~37°这个区间比较好。
{ x i } \left\{ x_i \right\} { xi} 是一组中间指标序列,且最佳区间为 [ a , b ] \left[ a,b \right] [a,b],那么正下序列化公式:

具体例子:

第二步:正向化矩阵标准化
标准化的目的是消除不同指标量纲的影响。
消除不同指标量纲的一种方法
假设有n个要评价的对象,m个评价指标(已经正向化),构成的正向化矩阵

那么,对其标准化的矩阵为Z,Z中的每一个元素: Z ij = x ij / ∑ i=1 n x i j 2 { {\text{Z}}_{\text{ij}}}\text{=}{ {\text{x}}_{\text{ij}}}\text{/}\sqrt{\sum\limits_{\text{i=1}}^{\text{n}}{x_{ij}^{2}}} Zij=xij/i=1∑nxij2 (每个元素/sqrt(其所在列的元素的平方和)
注意:* 标准化的方法有很多种,其主要目的就是去除量纲的影响,未来我们还可能见到更多种的标准化方法,例如:(x‐x的均值)/x的标准差;具体选用哪一种标准化的方法在多数情况下并没有很大的限制,这里我们采用的是前人的论文中用的比较多的一种标准化方法。
第三步:计算得分并归一化
假设有n个要评价的对象,m个评价指标(已经正向化),构成的正向化矩阵
定义最大值(找出每一列的最大值构成一个行向量)
X + = ( X 1 + , X 2 + , . . . , X M + ) = ( max { x 11 , x 21 , . . . , z n 1 } , max { x 12 , x 22 , . . . , z n 2 } , . . . . max { x 1 m , x 2 m , . . . , z n m } ) X^+=\left( X_{1}^{+},X_{2}^{+},...,X_{M}^{+} \right) =\left( \max \{x_{11},x_{21},...,z_{n1}\},\max \{x_{12},x_{22},...,z_{n2}\},....\max \{x_{1m},x_{2m},...,z_{nm}\} \right) X+=(X1+,X2+,...,XM+)=(max{ x11,x21,...,zn1},max{ x12,x22,...,zn2},....max{ x1m,x2m,...,znm})
定义最小值 (找出每一列的最小值构成一个行向量)
X − = ( X 1 − , X 2 − , . . . , X M − ) = ( min x { x 11 , x 21 , . . . , z n 1 } , min { x 12 , x 22 , . . . , z n 2 } , . . . . min { x 1 m , x 2 m , . . . , z n m } ) X^-=\left( X_{1}^{-},X_{2}^{-},...,X_{M}^{-} \right) =\left( \min\text{x}\{x_{11},x_{21},...,z_{n1}\},\min \{x_{12},x_{22},...,z_{n2}\},....\min \{x_{1m},x_{2m},...,z_{nm}\} \right) X−=(X1−,X2−,...,XM−)=(minx{ x11,x21,...,zn1},min{ x12,x22,...,zn2},....min{ x1m,x2m,...,znm})
定义第i(i=1,2,……,n)个评价对象与最大值的距离 D i + = ∑ j = 1 m ( X j + − z i j ) 2 D_{i}^{+}=\sqrt{\sum_{j=1}^m{\left( X_{j}^{+}-z_{ij} \right) ^2}} Di+=∑j=1m(Xj+−zij)2
定义第i(i=1,2,……,n)个评价对象与最小值的距离 D i − = ∑ j = 1 m ( X j − − z i j ) 2 D_{i}^{-}=\sqrt{\sum_{j=1}^m{\left( X_{j}^{-}-z_{ij} \right) ^2}} Di−=∑j=1m(Xj−−zij)2
那么,我们可以计算得出第i(i=1,2,……,n)个评价对象未归一化的得分: S i = D i − D i + + D i − S_i=\frac{D_{i}^{-}}{D_{i}^{+}+D_{i}^{-}} Si=Di++Di−Di−
很明显 0 ⩽ S i ⩽ 1 0\leqslant S_i\leqslant 1 0⩽Si⩽1 ,且 S i {S_{i}} Si越大 D i + {D_{i}^{+}} Di+越小,即越接近最大值。
注意:
(1)这里还没有考虑指标的权重,后面的模型拓展内容会考虑指标的权重来进行计算。
(2)要区别开归一化和标准化。
归一化的计算步骤也可以消去量纲的影响,但更多时候,我们进行归一化的目的是为了让我们的结果更容易解释,或者说让我们对结果有一个更加清晰直观的印象。例如将得分归一化后可限制在0‐1这个区间,对于区间内的每一个得分,我们很容易的得到其所处的比例位置。