GPU架构与管线总结
核弹厂有一篇关于自家GPU架构和逻辑管线的非常好的文章,如果你想要对GPU的结构有一个比较完整系统的认识,请一定不要错过这篇Life of a Triangle,本文主要参考此处进行总结归并。
管线结构总图
- 为什么这一切如此复杂?因为在图形阶段我们必须处理由于创建大量变量导致的数据扩充。每个drawcall可能会生产不同数量的三角形。而经过剪裁后的点的数量与我们最初生成的又不一样。经过背面剔除和深度剔除处理后,不是所有的三角形都需要在显示在屏幕上的。一个三角形在屏幕上的尺寸就意味着需要百万的像素来显示,或者不需要显示的时候就不需要任何像素。
- 因此现代GPU使基元(三角形,线,点)遵从逻辑管线,而非物理管线。以前G80架构时代(比如DX9硬件,PS3,XBOX360等),管线体现在不同阶段的芯片不同并且工作会按顺序从一个继续传到下一个。G80本质上会根据负载来重用一些单元来进行点着色和片段着色的计算,但实际上它仍然有一个串行的(a serial process)基元和光栅化过程。而Fermi的进化管线的完全并行化,意味着芯片通过重用各种装置实现了完整的逻辑管线(三角形所经历的各个阶段)。
- 让我们设想有两个三角形A和B,他们在逻辑管线中所需要进行的处理步骤可能不同。A已经经过transform,需要进行光栅化。当它上面的一些像素还在处理深度缓冲阶段时,有一些可能已经运行了像素着色,而另一些可能已经被写入了帧缓冲,还有一些可能还在等待处理。而做完这些处理,我们可能需要从头获取B的顶点。因此,虽然每个三角形都必须经过逻辑步骤,但是很多三角形可以在其生命周期的不同步骤中被主动处理。整个任务(获取drawcall的三角形然后将它们搬到屏幕上)被切分成不同的更小份的任务,甚至连这些子任务都可以并行运算。每个任务都会根据可用资源进行安排,而不仅仅局限于任务的当前类型(比如点着色可以和像素着色并行运算)。
并行管线流中每一条都彼此独立,每一条都有自己的时间线,有一些可能会比其他的有更多分支。如果我们将GPU进行处理所基于的三角形部分的单元或者drawcall当前正在处理的单元进行代码着色的话,看起来会像是七彩的闪烁灯。
一、GPU架构

-
因此Fermi NVIDIA也有一个类似原理的架构。它有一个管理所有工作进行的Giga线程引擎(Giga Thread Engine)。GPU被分割成许多个GPCs(Graphics Processing Cluster 图形处理簇),每个簇都有许多SMs(Streaming Multiprocessor 流多重处理器)和一个光栅引擎(Raster Engine)。这个结构中有许多连接器,尤其是Crossbar,允许工作的迁移穿过GPCs或者其他像ROP(render output unit)这样的功能性单元。
-
程序员所考虑的工作(shader程序计算)是在SMs进行处理的。它包含许多为线程进行数学计算的内核(Cores)。举例来说一个线程可能是VS或者PS调用。这些核心和其他单元由Warp Schedulers驱动,Warp Schedulers管理一组32线程的wrap(Wrap:GPU执行程序时的调度单位,目前cuda的warp的大小为32,同在一个warp的线程,以不同数据资源执行相同的指令,这就是所谓 SIMT)并且把要进行处理的指令递交到Dispatch Units(指令调度器)。代码的逻辑由调度器负责处理而不是在核心自身的内部处理,所以从调度程序上看只会看到类似于“计算寄存器4234和寄存器4235的值的和并且储存到寄存器4230中”。相比较CPU那相当聪明的内核来说(GPU的)一个内核本身是挺蠢的。GPU将比较聪明的部件放置到比较高的层级,它会引导整个工作的进行(或者是你想要的多个工作)。
-
GPU中实际存在多少个这样的核心(每个GPC多少个SMs,每个GPU有多少个GPCs等)基于芯片配置本身。比如像上面说的GM204有4个GPCs,每个GPC有4个SMs,但是同样是基于Maxwell设计的Tegra X1仅有1个GPC和2个SM。SM自身的设计(内核数量,指令单元,调度器等)也随着时间一代代地进化使得芯片如此高效,以至于它们能广泛应用在高端台式、笔记本和移动平台上。
首先我们来看一下其中的管线主流程图:
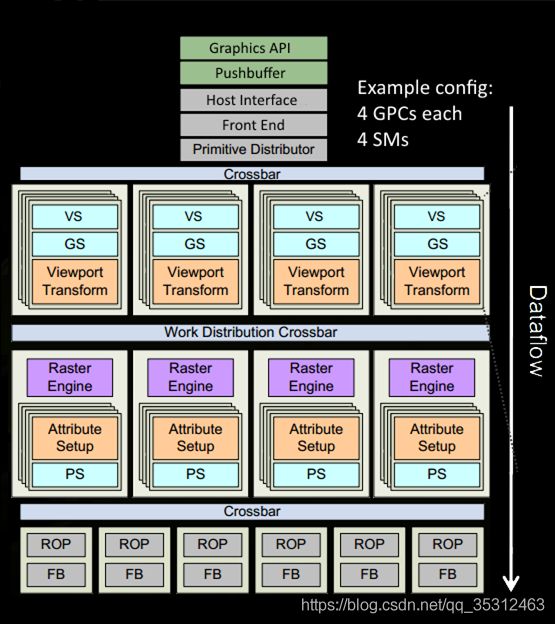
这一部分是基于数据的流向,对GPU的硬件单元进行了大致的划分,通常来说,GPU会有三个比较重要的部分,分别是图中从顶至下的:控制模块、计算模块和输出模块。通常来说,GPU架构的设计需要有可伸缩性,这样通过增加/阉割计算和输出模块,就能够产生性能不同的同架构产品(比如GTX1070和GTX1080的主要区别就在于GPC和FBP的数量),以满足不同消费水平和应用场景的需求。
1.1 控制模块

1.1.1 布局与功能
控制模块负责接收和验证(主要是Host和Front End)来自CPU的经过打包的PushBuffer(经过Driver翻译的Command Buffer),然后读取顶点索引(注意是Vertex Indices不是Vertex Attributes,主要由Primitive Distributor负责)分发到下游管线或者读取Compute Grid的信息(主要由CWD负责,这部分是Compute Pipeline,不作展开)并向下游分发CTA。
- 注:计算管线和图形管线共享大部分的芯片单元,只在分发控制的单元上各自独享(PD和CWD)。许多较新的Desktop GPU允许图形和计算管线并行执行,可以在一些SM压力轻的图形计算环节(比如Shadow Map绘制),利用Compute Shader去做一些SM压力重的工作(比如后处理),让各个硬件单元的负载更加平衡。
1.1.2 工作流程
本部分具体工作流程如下:
- 程序在图形API中创建一个drawcall。之后经过一些验证后到达驱动,然后用GPU可读的编码格式将指令插入到Pushbuffer(推送缓存)。这个阶段会产生许多跟CPU侧相关的瓶颈,这就是为什么程序员用好API以及所用技术能充分利用上现代GPU的性能十分重要。
- 经过一段时间或者直接的“刷新”调用后驱动上已经缓存了足够多的工作到Pushbuffer并将它发送给GPU进行处理(以及一些操作系统的参与)。GPU的主接口(Host Interface)获取到经过前端(Front End)处理的指令。
- 之后我们开始在基元分配器(Primitive Distributor)中开始分配的工作。在这里会对索引缓冲中的序列进行处理,并且批量生成之后我们会将其发送给多个GPC上的三角形。
1.2 计算模块
计算模块是GPU中最核心的部件,Shader的计算就发生在这里。早期的硬件设计上,我们会区分VS,PS等Shader类型,并设计专用的硬件单元去执行对应类型的Shader,但这样的方法并不利于计算单元满负荷运转,所以现在所有的GPU设计都是通用计算单元,为所有Shader类型服务。在NV的显卡里这个模块全称是Graphics Processing Cluster,通常一个GPU会有多个GPC,每个GPC包含一个光栅器(Raster)负责执行光栅化操作,若干个核心的计算模块,称之为Texture Process Cluster(TPC)。
1.2.1 TPC(Texture Process Cluster)
关于TPC,我们进一步分解来看这张大图
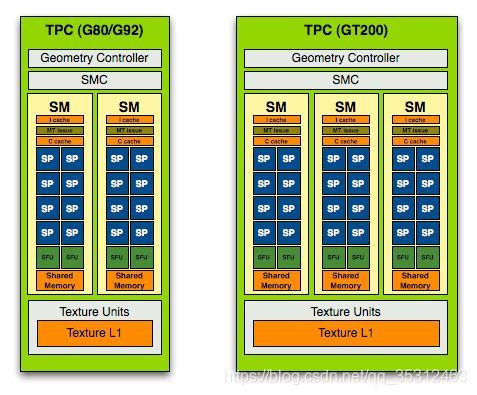
通常来说,一个TPC拥有:
- 若干个用于贴图采样的纹理采样单元(Texture Units)
- 一个用于接收上游PD数据的Primitive Engine,PE作为一个固定单元,负责根据PD传来的顶点索引去取相应的顶点属性(Vertex Attribute) ,执行顶点属性的插值,顶点剔除等操作
- 一个负责Shader载入的模块
- 若干执行Shader运算的计算单元,也就是流处理器(Streaming Multi-Processor,SM, AMD叫CU)
1.2.2 SM(Streaming Multi-Processor)
其中,TPC内最核心的部件就是SM,这里我们再进一步分解SM看这张大图:
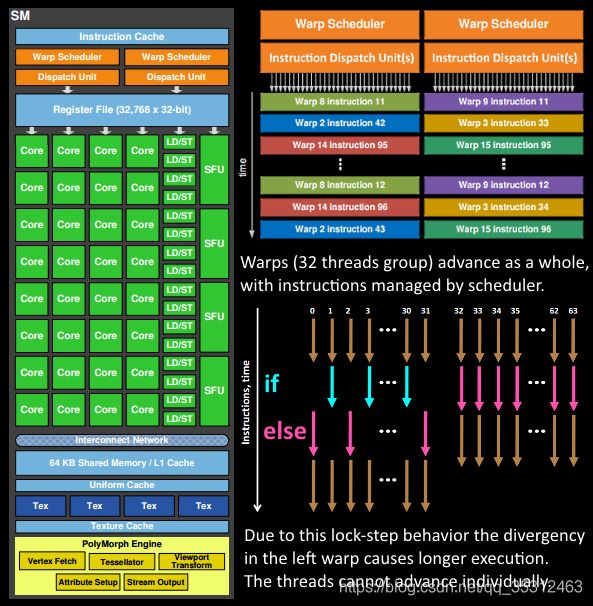
一个SM通常拥有一块专用于缓存Shader指令的L1 Cache,若干线程资源调度器,一个寄存器池,一块可被Compute Pipeline访问的共享内存(Shared Memory),一块专用于贴图缓存的L1 Cache,若干浮点数运算核心(Core),若干超越函数的计算单元(SFU),若干读写单元(Load/Store)。
作为核心计算单元,GPU的设计思路和CPU有很大的不同,就我所知的体现在两个方面:
- GPU拥有较弱的流程控制(Flow-Control)的能力
- GPU拥有更大的数据读写带宽,并配合有更多样的延迟隐藏技术
要详细解释这两点,我们就需要理解GPU的执行模型。
1.2.2.1 GPU的执行模型
GPU的设计是为了满足大规模并行的计算,为此,它使用的是SIMD(Single Instruction Multiple Data) 的执行模式,在内部,若干相同运算的输入会被打包成一组并行执行,这个组就是GPU的最小执行单元,在NV叫做Warp,每32个thread为一组,在AMD叫做Wavefronts,每64个thread为一组。基于不同的shader阶段,被打包执行的对象会有区别,比如VS里,就是32个顶点为一组,PS里,就是8个pixel quad(2*2像素块)为一组。
那么GPU又如何处理分支呢?我们知道,CPU有一种经典的处理分支的方法,叫做分支预测。CPU会根据一组数据之前的分支结果去预测下一次分支的走向,如果错误就会有额外的开销。GPU没有这么复杂的流程控制,它的流程控制基于一种叫做“active mask”的技术,简单来说就是用一个bit mask去判断当前32个thread的branch状态,如果是0,则表示只需要执行false的branch,如果bit mask是2^32-1,则表示只需要执行true的branch,否则就需要对某些thread执行true,同时另一些在执行true的同时等待这些thread,反之亦然,这种情形下一个warp的执行时间就是Max(branch(true))+Max(branch(false))。
1.2.2.2 GPU的内存类型
Desktop GPU的内存类型和CPU比较相似,也是多级缓存的机制,我们能够接触到的内存类型包括Register,Shared Memory(本质是L1 Cache的一块),Texture L1 Cache(本质是L1 Cache的一块),Instruction Cache(本质是L1 Cache的一块),L2 Cache,DRAM,各类存储器的容量在是依次增大的,相应的它们在芯片上的位置也是离核心单元SM越来越远,同时访存延迟也是逐级增大的。
对于GPU在这几种内存中的访存延迟,我从这篇文章找到了一些数据:

Mobile GPU没有专用的显存,而是和CPU共享同一块系统内存(缓存机制当然也应该是共享的),但它有一块位于GPU上的专用on chip memory。
GPU拥有大量的寄存器(数量远多于CPU),是为了能够快速的在warp之间做切换:当某个warp被某些指令阻塞的时候(比如贴图采样),warp schedular可以让其处于休眠状态,并且把shader core的资源让出来,唤醒那些未被阻塞的warp。对于CPU来说,context switch的开销来源于寄存器的恢复和保存(没那么多寄存器,只能复用),但是对于GPU,每个warp是独占一份自己的register file的,这样就可以几乎无消耗地切换warp。相应的,一个SM里能同时并行多少个warp,就取决于一段shader到底占用了多少register,占用的越多,则能够并行的warp就越少。
1.2.2 Turing架构中的光追结构
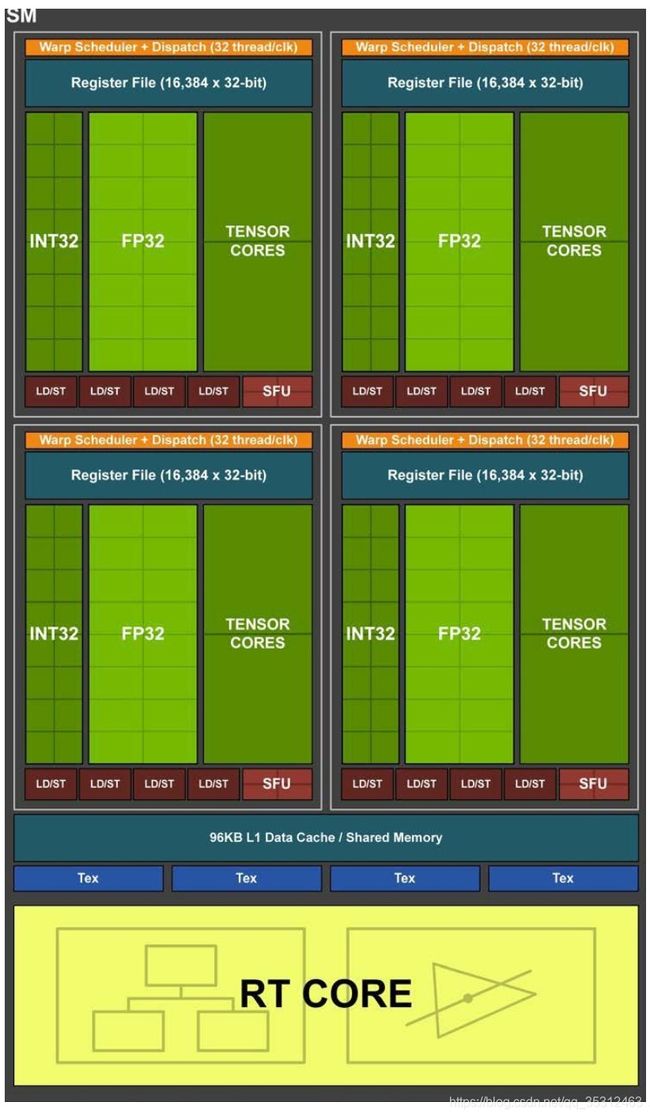
相较于上几代的GPU,Turing在SM中增加了专用于光线追踪的RTCore,以及用于张量计算的TensorCore(后者主要是用于深度学习。在Turing之后,你还可以在做Graphics的同时利用TensorCore去做一些DL的工作,比如DLSS[7]?好像没什么x用)。下面两张图简单解释了RTCore前后光线追踪的基本流程:
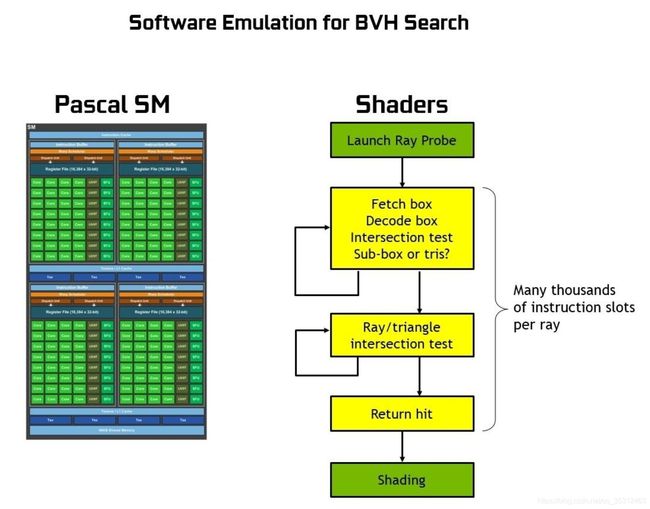
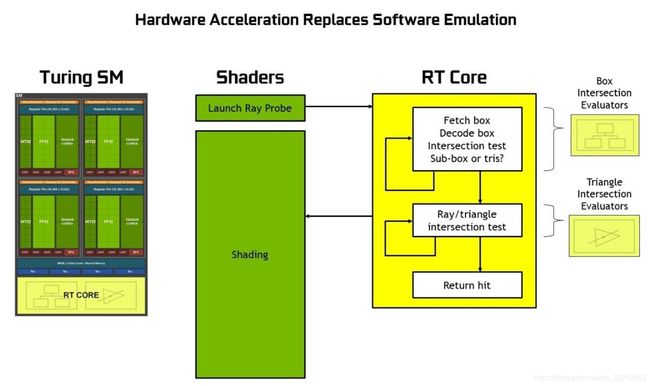
这个图看起来很复杂,其实很简单:对于非Turing架构来说,光线和BVH的遍历求交、光线和三角形的求交、光线和三角形交点的着色这三件事,都是翻译成了数千条SM的指令给FP Core执行的。而Turing架构则是把前两件事作为固定硬件单元集成在了RTCore里,所以RTCore核心功能有两个:遍历BVH和光线-三角形快速求交。
1.2.3 工作流程
接控制模块 1.1.2 工作流程:
- 在GPC中,SM中的多边形变形引擎(Poly Morph Engine)负责根据三角形序列获取顶点数据(Vertex Fetch)。
- 获取到数据后,SM内部就会调度32线程的warp然后开始进行顶点处理工作。
- SM的warp调度器会根据顺序为整个warp分发指令。每个线程锁步(lock -step)地运算每个指令,如果线程不应该主动执行,则可以单独屏蔽掉。需要这种屏蔽的原因有许多。比如如果当前的指令是一个if-true分支的一部分并且具体运算结果是false,或者当一个循环条件的终止条件在一个线程时刚好满足而不是另外一个线程中时。所以一个有许多分支结构的shader会显著地增加在warp中所有线程上所消耗的时间。线程不能单独推进到下一步,只有作为整个warp的时候才行,虽然warp也是互相独立的。
- warp指令可能会一次性完成,也可能会耗费几个发送回合。SM通常比进行基本数学运算具有更少的加载/存储单位。
- 由于一些指令处理会比其他的消耗跟多的时间,特别是内存加载,因此warp调度程序可能只是切换到另一个不等待内存的warp。这就是GPU克服内存延迟的关键概念,GPU只是简单地切换活动的线程组。为了保证切换足够快速,所有被调度器管理的线程都在寄存器堆(register-file)中有自己的寄存器。shader程序所需要的寄存器越多,线程/warp所有用的空间就越少。而我们可以用于切换的warp越少,我们在等待指令完成(最重要的是内存获取)的过程中所能做的工作就越少。(因为正在获取内存的warp不会用来做其他工作,所以只能跳转到空闲的warp上)

- 一旦warp完成了所有VS的指令运算,结果会被视口转换(Viewport Transform)处理。三角形会被裁剪空间体裁剪,至此就做好了光栅化的准备。我们使用L1和L2缓存来存储所有这些跨任务通讯的数据。
10.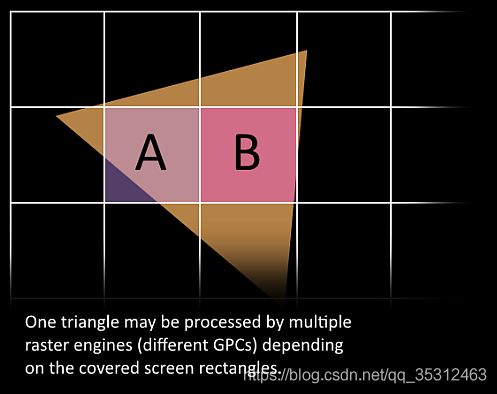
- 现在过程变得令人兴奋了,我们的三角形被切分并且可能会离开目前它存在的这个GPC。由于每个光栅引擎会覆盖多个屏幕的上的连块,所以三角形的边界框会用来判断哪个光栅引擎会被用来处理这个三角形。之后我们的三角形通过任务分配交叉线(Work Distribution Crossbar)被发送到一个或者多个GPC上。现在我们有效地将我们的三角形切分成许多更小型的任务了。
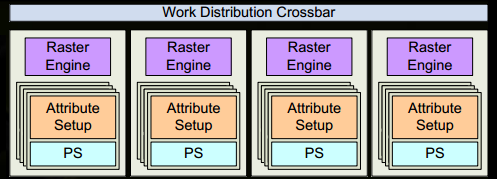
- 目标SM中的属性设置(Attribute Setup)会确保插值(比如我们我们从VS中生成的输出)用的是对PS友好的格式。
- GPC的光栅引擎对接受到的三角形进行处理,并为它负责的那些部分生成像素信息(也处理背面剔除和Z-cull)。
- 我们再次来分批处理32像素的线程,更贴切的说是处理8次2x2像素的方格,一般来说这是我们将要在PS中处理的最小单位。这个2x2方格允许我们计算一些类似于mip map过滤之类的工作(方格中纹理坐标太大会导致更高的mip)。那些采样位置没有真正意义上覆盖三角形的2*2方格中的线程会被屏蔽。一个本地SM的warp调度器会对PS任务进行管理。
- 我们在VS逻辑阶段进行过的同样的warp调度器指令游戏现在跑在了PS线程上。锁步处理十分有用,因为我们几乎可以自由的存取像素格内的值,因为所有的线程都会被确保他们的数据被计算成了相同的指令指针。
1.3 输出模块

输出模块(Framebuffer Partition,FBP)比较简单,最核心的部件是一个称之为ROP(Raster Operation) 的单元,ROP又包含了两个子单元,分别是CROP(Color ROP)和ZROP,前者负责Alpha Blend,MSAA Resolve等操作,并把最终的颜色写到color buffer上,后者则负责进行Stencil/Z Test以及把depth/stencil写到z buffer上。
1.3.1 工作流程
接计算模块 1.2.3 工作流程:
- 由于对PS进行了计算,我们已经得知了要向渲染目标(Render Target:即一块backbuffer 离屏缓冲,或者可以理解为一个和输出像素等高宽的平面,可以将物件渲染到这里进行后续处理)写入的颜色并且我们也有了深度信息。此时我们必须考虑三角形的原始API顺序,然后才将数据传递给ROP(渲染输出单元)子系统之一,这些子系统本身具有多个ROP单元。在这里深度测试,帧缓冲混合等处理已经进行了处理。这些操作需要在原子级别上运作(一次设置一种颜色/深度)以确保我们不会在同一个像素上设置了一个三角形的颜色又设置了另一个三角形的深度值。NVIDIA通常采用内存压缩,以降低内存带宽要求,从而增加“有效”带宽。
至此,我们已经完成了,我们写入了一些像素值到渲染目标(Render Target)。我希望这些信息对于理解GPU内部的工作流/数据流有所帮助。当然另一方面也可以帮助理解为什么与CPU同步工作是相当痛苦的。有一点就是如果没有新任务提交进来GPU就必须等待所有CPU的处理完成(所有单元都会变成闲置状态),这意味着当有新任务发送进来时需要等待一段时间才能达到完全负载的状态下,尤其是大型GPU更为明显。
二、渲染管线
说到渲染管线,就必须介绍当前GPU使用的三种不同的渲染管线:Immediate Mode Rendering, Tile Based Rendering和Tile Based Deferred Rendering。我们用三张图来详细描述IMR,TBR和TBDR三种模式的渲染管线:
2.1 IMR模式(立即渲染模式)

IMR(Immediate Mode Rendering)就如字面意思一样——提交的每个渲染要求都会立即开始,这是一种简单而又粗暴的思路,优点缺点都非常明显,如果不用为性能担忧,这种方式会很省事,但是IMR的渲染实行的是无差别对待,那些遮蔽处理的部分依然会被渲染处理器,这也导致无意义的读写操作更多,浪费了大量性能和带宽。
IMR这种渲染方式在移动GPU上的评价只能是“负分”。
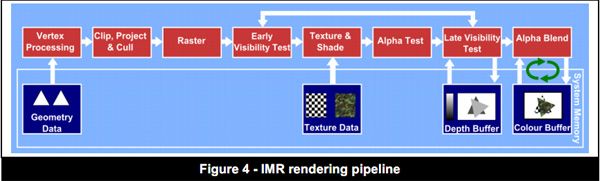
-
IMR模式的第一个阶段是Vertex Processing,这个环节包括从DRAM/System Memory取Vertex Indices(PD的工作),然后根据Vertex Indices去Vertex Buffer取相应的属性(PE中VAF的工作),需要注意的是,取Indices/Vertex Attributes的阶段都会有L2 Cache在工作,表示如果顶点短时间内被share多次,则可以通过cache命中减少加载时间。加载完顶点数据后,Vertex Shader将会被加载到SM的Instruction Cache,紧接着就是VS在SM的执行。
-
VS执行完毕后,PE内的固定单元会执行顶点剔除来剔除一些视口外的三角形,背面剔除也在这个阶段发生。
-
接下来,由Raster对三角形进行光栅化,光栅化完毕的像素将会被打包成warp,经过XBAR重新流入SM(可能是同一个SM,也可能是不同的SM)。重新进入SM的每个pixel会根据其重心坐标,使用PE内的固定单元进行属性插值,从而得到depth,varying attributes等信息。
其中对early-Z test的处理是:
-
对于没有Apha Test的pixel quad,由ZROP对其执行early-Z test。
-
对于通过early-Z test的像素,在SM内执行pixel shader。
-
对于开启Alpha Test的像素,由ZROP对其进行late-Z test,并根据结果决定是否更新FrameBuffer相应位置的颜色和深度值。
-
若需要更新,则ZROP根据depth test的设置更新z buffer,CROP根据blend的设置去更新color buffer。
注意,IMR的整个流程中,三角形是可以以Stream的形式逐步提交给管线的,先提交的三角形也不需要去等待同一个Render Target上的其他三角形。
IMR是所有Desktop GPU的标配,因为Desktop GPU相较于Mobile GPU,有更多的带宽用于读写,有专用供电接口,也不受限于芯片发热的问题。IMR架构的好处是设计上会相对来说比较清晰简明,并且整个管线是连续的,draw call之间不需要互相等待,有利于最大化吞吐量。对于Mobile GPU来说,只有NV的Tegra系列是基于IMR的。
2.2 TBR模式(分块渲染模式)
IMR傻大粗的做法不可取,那就来一个聪明点的方式——TBR(Tile Based Rendering,贴图渲染),它将需要渲染的画面分成一个个的区块(tile),每个区块的坐标通过中间缓冲器以列表形式保存在系统内存中。这种渲染方式的好处就是相对IMR减少了不必要的渲染任务,缺点就是遮蔽碎片依然会少量存在,而且需要中间缓冲器。
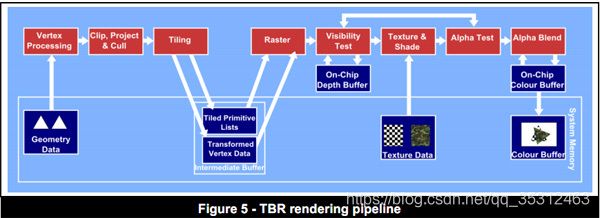
TBR架构的GPU会把整个逻辑渲染管线打断成两个阶段:
- 第一阶段和IMR类似,它负责顶点处理的工作,不同的是在每个三角形执行完他们的VS之后,还会执行一个称之为Binning Pass[18]的阶段,这个阶段把framebuffer切分成若干个小块(Tiles/Bins),根据每个三角形在framebuffer上的空间位置,把它的引用写到受它影响的那些Tiles里面,同时由VS计算出来的用于光栅化和属性插值的数据,则写入另一个数组(我们可以认为图中Primitive List就是我们说的一个固定长度数组,其长度依赖于framebuffer划分出的tile的数量,数组的每个元素可以认为是一个linked list,存的是和当前tile相交的所有三角形的指针,而这个指针指向的数据,就是图中的Vertex Data,里面有VS算出的pos和varying变量等数据)。在Bining Pass阶段,Primitive List和Vertex Data的数据会被写回到System Memory里。
注:TBR的管线会等待同一个framebuffer上所有的三角形的第一阶段都完成后,才会进入到第二阶段,这就表示,你应该尽可能的少切换framebuffer,让同一个framebuffer的所有三角形全部绘制完毕再去切换
- 第二阶段负责像素着色,这一阶段将会以Tile为单位去执行(而非整个framebuffer),每次Raster会从Primitive List里面取出一个tile的三角形列表,然后根据列表对当前tile的所有三角形进行光栅化以及顶点属性的插值。后面的阶段TBR和IMR基本是一致的,唯一区别在于,由于Tile是比较小的,因此每个Tile的color buffer/depth buffer是存储在一个on chip memory上,所以整个着色包括z test的过程,都是发生在on chip memory上,直到整个tile都处理完毕后,最终结果才会被写回System Memory。
注:TBR的优化实际上是利用缓存的局部性原理。
2.3 TBDR模式(分块延迟渲染模式)
TBR虽然比IMR聪明多了,不过还是存在不少缺陷,TBDR(Tile Based Deferred Rendering,贴图延迟渲染)闪亮登场,它跟TBR原理相似,但是使用的是延迟渲染(Deferred Rendering),合并了完美像素,通过HSR(Hidden Surface Removal,隐藏面消除)等进一步减少了不需要渲染的过程,降低了带宽需求。实际上这些改变和PC上的渲染有些相似。
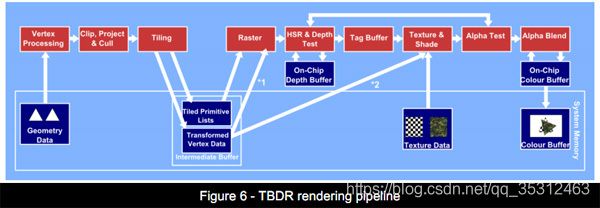
TBDR和TBR模式基本类似,唯一的区别在于,TBDR模式在执行光栅化之后,不会急着shading,而是会对rasterized sample进行消隐(基于depth buffer和相同位置的其他sample深度去移除被遮挡的sample),这个消隐的过程结束之后,tile上剩下的sample才会被送到PS里面去做shading。
2.4 三种管线模式对比
通常TBR/IMR模式的GPU是基于比较简单的early-Z reject去防止overdraw,TBDR在这个方面则走得更远一点。所以对于IMR/TBR模式的GPU来说,对不透明物体的draw call从前到后排序、Pre-Z pass都能够显著减少overdraw并提高性能;但对于TBDR模式的GPU来说,这两个策略都不会提升性能(管线里面做了相同的事),而且还会影响因性能(排序、Pre-Z pass带来的额外开销)。