《动手学深度学习》学习笔记(九)
第九章 计算机视觉
先介绍两种有助于提升模型泛化能力的方法:图像增广和微调。
鉴于深度神经网络能够对图像逐级有效地进行表征:所以广泛应用到目标检测、语义分割和样式迁移这些主流计算机视觉任务中。
全卷积网络对图像做语义分割。
样式迁移技术生成封面图像。
一、图像增广
图像增广(image augmentation)技术通过对训练图像做一系列随机改变,来产生相似但又不同的训练样本,从而扩大训练数据集的规模。
图像增广的另一种解释是,随机改变训练样本可以降低模型对某些属性的依赖,从而提高模型的泛化能力。
裁剪感兴趣区域出现在不同位置,减轻模型对物体出现位置的依赖性;
调整亮度、色彩、对比度、饱和度、色调来降低模型对色彩的敏感度。
上下翻转不如左右翻转。
以上规则叠加使用。
为了在预测时得到确定的结果,我们通常只将图像增广应用在训练样本上,而不在预测时使用含随机操作的图像增广。
二、微调
适用于ImageNet数据集的复杂模型在我们应用场景的数据集上过拟合。同时,因为数据量有限,最终训练得到的模型的精度也可能达不到实用的要求。
为了解决这个问题:
一方面:收集更多的数据集。然而收集数据集花费大量的时间和资金。
另一方面:迁移学习(Transfer learning),将从源数据集学到的知识迁移到目标数据集上。虽然ImageNet数据集的图像大多跟我们的应用场景无关,但在该数据集上训练的模型可以抽取较通用的图像特征,从而能够帮助识别边缘、纹理、形状和物体组成等。这些类似的特征对于识别我们的场景也可能同样有效。
迁移学习的一种常用技术:微调(fine tuning) :
-
在源数据集(如ImageNet数据集)上预训练一个神经网络模型,即源模型。
-
创建一个新的神经网络模型,即目标模型。它复制了源模型上除了输出层外的所有模型设计及其参数。我们假设这些模型参数包含了源数据集上学习到的知识,且这些知识同样适用于目标数据集。我们还假设源模型的输出层跟源数据集的标签紧密相关,因此在目标模型中不予采用。
-
为目标模型添加一个输出大小为目标数据集类别个数的输出层,并随机初始化该层的模型参数。
-
在目标数据集(如椅子数据集)上训练目标模型。我们将从头训练输出层,而其余层的参数都是基于源模型的参数微调得到的。

当目标数据集远小于源数据集时,微调有助于提升模型的泛化能力。
PyTorch可以方便的对模型的不同部分设置不同的学习参数。
小结:
-
迁移学习将从源数据集学到的知识迁移到目标数据集上。微调是迁移学习的一种常用技术。
-
目标模型复制了源模型上除了输出层外的所有模型设计及其参数,并基于目标数据集微调这些参数。而目标模型的输出层需要从头训练。
-
一般来说,微调参数会使用较小的学习率,而从头训练输出层可以使用较大的学习率。
三、目标检测和边界框
在图像分类任务中,我们假设图像里只有一个主题目标,并关注如何识别该目标的类别。然而,很多图像里有多个我们感兴趣的目标,不仅需要知道它们的类别,还想得到它们在图像中的位置。这类任务称为:目标检测(object detection)或物体检测。
边界框(bounding box)来描述目标位置。矩形框,由左上角和右下角两个角点坐标确定。
四、锚框
目标检测算法通常会在输入图像中采样大量的区域,然后判断这些区域中是否包含我们感兴趣的目标,并调整区域边缘从而更准确地预测目标的真实边界框(ground-truth bounding box)。不同的模型使用的区域采样方法可能不同。这里我们介绍其中的一种方法:它以每个像素为中心生成多个大小和宽高比(aspect ratio)不同的边界框。这些边界框被称为锚框(anchor box)。
anchor只有跟你要检测的物体的大小和长宽比更贴近,才能让模型的效果更好。
anchor都是根据数据的实际分布来设置的。YOLOV3开始使用Kmeans方法聚类得到合适的anchor。
1、生成多个锚框
假设输入图像高为h,宽为w。我们分别以图像的每个像素为中心生成不同形状的锚框。设大小为![]() 且宽高比为
且宽高比为![]() ,那么锚框的宽和高将分别为
,那么锚框的宽和高将分别为![]() 和
和![]() 。当中心位置给定时,已知宽和高的锚框是确定的。
。当中心位置给定时,已知宽和高的锚框是确定的。


通过制定像素位置来获取所有以该像素为中心的锚框。上图以(250, 250)为中心的所有锚框。可以看到大小为0.75且宽高比为1的锚框较好地覆盖了图像中的狗。
2、交并比
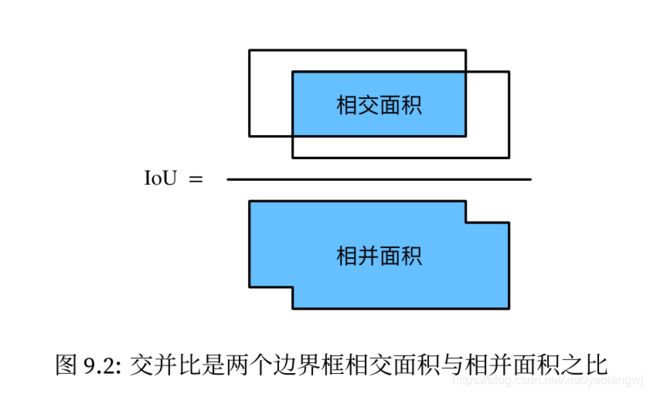
为了衡量某个锚框对图像中目标的覆盖情况,在已知目标的真实边界框的情况下,通过Jaccard系数衡量锚框和真实边界框之间的相似度:两者交集大小除以二者并集大小:
![]()
当衡量两个边界框的相似度时,我们通常将Jaccard系数称为交并比(Intersection over Union, IoU),即两个边界框相交面积与相并面积之比。
3、标注训练集的锚框
在训练集中,我们将每个锚框视为一个训练样本。为了训练目标检测模型,我们需要为每个锚框标注两类标签:
- 一是锚框所含目标的类别,简称类别;
- 二是真实边界框相对锚框的偏移量,简称偏移量(offset)。
在目标检测时,我们
- 首先生成多个锚框,
- 然后为每个锚框预测类别以及偏移量,
- 接着根据预测的偏移量调整锚框位置从而得到预测边界框,
- 最后筛选需要输出的预测边界框。
1、将生成锚框(![]() )与真实锚框(
)与真实锚框(![]() )一一做交并比,生成交并比矩阵。
)一一做交并比,生成交并比矩阵。
2、基于交并比矩阵最大元素,匹配锚框所属类别,然后分配给真实锚框类别。
3、接着将最大元素所在行列丢弃。继续找剩余最大元素,然后再分配真实锚框类别。再丢弃该行列。
4、直到真实锚框全部被分配过。
5、此时剩余元素(![]() 个)中,遍历,看交并比是否满足阈值。
个)中,遍历,看交并比是否满足阈值。
以上所有分配,交并比必须大于预先设定的阈值,否则无效。
对锚框分配完成后,标注锚框的类别,根据锚框和真实边界框中心坐标的相对位置和两个框的相对大小为锚框标注偏移量。

通过contrib.nd模块中的MultiboxTarget函数为锚框标注类别和偏移量。背景类别设置为0,目标类别索引加1。交并比最大的直接标注,较小的与阈值对比。小于阈值标记为背景。且返回每个锚框的偏移量,负类掩码变量为0。
4、输出预测边界框
根据锚框及其预测偏移量得到预测边界框时,如果相似的较多,使用非极大值抑制(non-maximum suppression, NMS)移除相似的预测框:
对每一个预测边界框,模型会计算各个类别的预测概率,找到其中最大的预测概率为p,则概率所对应的类别即为该预测边界框的预测类别:也称为预测边界框的置信度。
- 将预测边界框按每类置信度从高到低排序生成列表L,
- 从L中选取置信度最高的预测边界框作为基准。
- 将所有与基准交并比大于某阈值的非基准预测边界框移除。太相似的删除。
- 再从L中选择第二高置信度的预测边界框作为基准,再删除一遍。
- 重复此过程。直到L中所有预测边界框都曾作为基准。
- 总之:不是极大值,就删。
- 为了减少计算量,最后只保留置信度较高的结果作为最终输出。
小结:
-
以每个像素为中心,生成多个大小和宽高比不同的锚框。
-
交并比是两个边界框相交面积与相并面积之比。
-
在训练集中,为每个锚框标注两类标签:一是锚框所含目标的类别;二是真实边界框相对锚框的偏移量。
-
预测时,可以使用非极大值抑制来移除相似的预测边界框,从而令结果简洁。去重。
五、多尺度目标检测
以每个像素为中心生成不同尺寸和形状的锚框,锚框是对输入图像不同区域的采样。但是如此,生成锚框过多,计算量过大。561像素高,728像素框图像上以每个像素为中心生成5个不同形状的锚框,那么一张图像上则需要标注并预测200多万个锚框(561 × 728 × 5)。
减少锚框个数的办法:
1、输入图像中均匀采样:并以采样的像素为中心生成锚框。
2、在不同尺度下,生成不同数量和不同大小的锚框。较小目标比较大目标在图像上出现位置的可能性更多。因此,当使用较小锚框来检测较小目标时,我们可以采样较多的区域。而当使用较大锚框来检测较大目标时,我们可以采样较少的区域。
我们可以通过定义卷积层输出的特征图feature map的形状来确定任一图像上均匀采样的锚框中心。这个对应不同尺度这个概念。
锚框中x和y轴的坐标值分别已除以特征图fmap的宽和高,这些值域在0和1之间的值表达了锚框在特征图中的相对位置。(归一化)
如果锚框anchors的中心遍布特征图fmap上的所有单元,anchors的中心在任一图像的空间相对位置一定是均匀分布的。(这句话的意思是说:卷积采样完之后的特征图featuremap上的点作为anchors的中心,在fmap上是每个点都作为anchors中心,但是因为这是采样后,如果恢复到原始图上的时候,那么就不再是逐像素分布,而是均匀分布了。每个anchor中心之间就有了间隔。)
上面说了小目标检测用小锚框,采样多;大目标检测用大锚框,采样少。
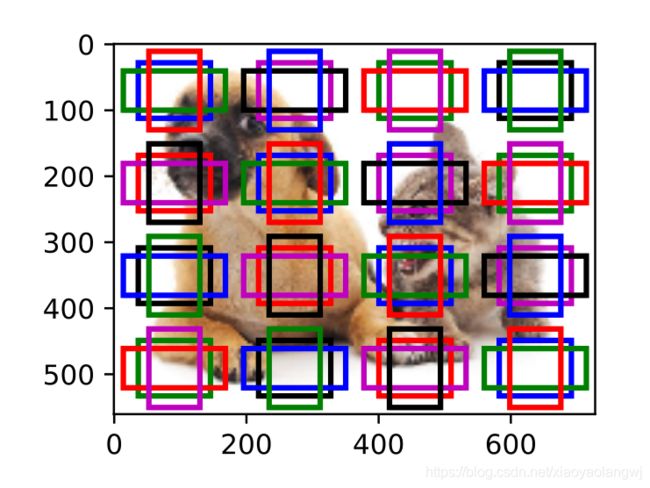
设锚框大小为0.15,特征图的高和宽分别为4。如下图,图像上4行4列的锚框中心分布均匀。
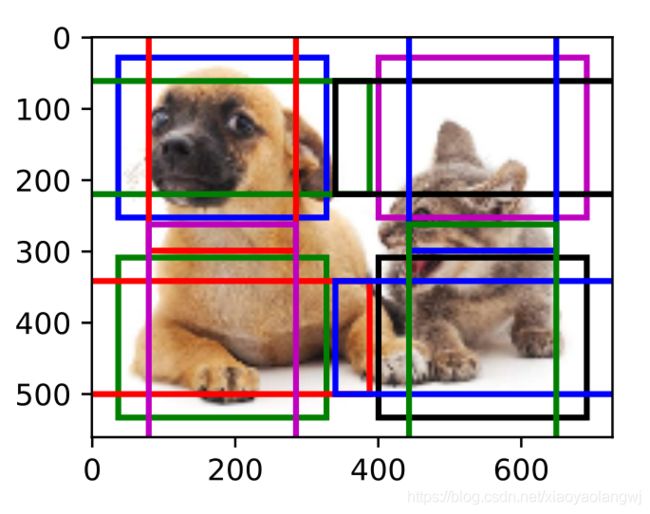
如果将特征图的宽和高分别减半,并用更大的锚框检测更大的目标。当锚框大小设为0.4时,有些锚框的区域有重合。
如果我们将特征图的高和宽进一步减半至1,并将锚框大小增至0.8。此时锚框中心即图像中心。

上面三个例子就是在多个尺寸上生成了不同大小的锚框,相应地,我们需要在不同尺度下检测不同大小的目标。基于卷积神经网络的方法:
在某个尺度下:特征图![]() 的特征图生成
的特征图生成 ![]() 组不同中心的锚框,每组锚框个数为a。依据真实边界框的类别和位置,每个锚框将被标注类别和偏移量。在当前的尺度下,目标检测模型需要根据输入图像预测
组不同中心的锚框,每组锚框个数为a。依据真实边界框的类别和位置,每个锚框将被标注类别和偏移量。在当前的尺度下,目标检测模型需要根据输入图像预测![]() 组不同中心的锚框的类别和偏移量。
组不同中心的锚框的类别和偏移量。
特征图为卷积神经网络根据输入图像做前向计算所得的中间输出。特征图组中在相同空间位置的单元在输入图像上的感受野相同,将特征图在相同位置的单元变换成以该位置为中心生成的a个锚框的类别和偏移量。
本质上,我们用输入图像在某个感受野区域内的信息来预测输入图像上与该区域位置相近的锚框的类别和偏移量。
不同层的特征图在输入图像上分别拥有不同大小的感受野时,它们将分别用来检测不同大小的目标。
我们可以通过设计网络,令较接近输出层的特征图中每个单元拥有更广阔的感受野,从而检测输入图像中更大尺寸的目标。
小结:
- 可以在多个尺度下生成不同数量和不同大小的锚框,从而在多个尺度下检测不同大小的目标。
- 特征图的形状能确定任一图像上均匀采样的锚框中心。
- 用输入图像在某个感受野区域内的信息来预测输入图像上与该区域相近的锚框的类别和偏移量。
六、目标检测数据集(皮卡丘)
使用MXNet提供的im2rec工具将图像转换成二进制的RecordIO格式。该格式既可以降低数据集在磁盘上的存储开销,又能提高读取效率。
七、单发多框检测(SSD)
单发多框检测(single shot multibox detection,SSD)。
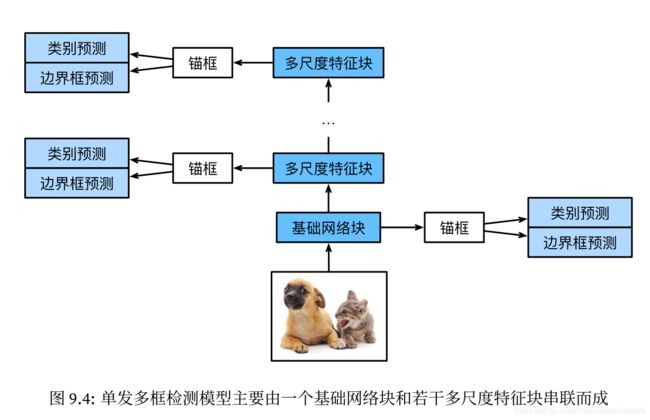
1、定义模型
单发多框检测SSD模型主要由一个基础网络块和若干个多尺度特征块串联而成。
- 其中基础网络块用来从原始图像中抽取特征,因此一般会选择常见的深度卷积神经网络。单发多框检测SSD论文中选用了在分类层之前截断的VGG。现在也常用ResNet替代。我们可以实际基础网络使它输出的高和宽较大。这样一来,基于该特征图生成的锚框数量较多。可以用来检测尺寸较小的目标。
- 接下来的每个多尺度特征块将上一层提供的特征图的高和宽缩小(如减半),并使特征图中每个单元在输入图像上的感受野变得更广阔。多尺度特征块输出的特征图越小,故而基于特征图生成的锚框也越少,加之特征图中每个单元感受野越大,因此更适合检测尺寸较大的目标。
- 由于单发多框检测基于基础网络块和各个多尺度特征块生成不同数量和不同大小的锚框,并通过预测锚框的类别和偏移量(即预测边界框)检测不同大小的目标,因此单发多框检测SSD是一个多尺度的目标检测模型。
2、类别预测层
设目标的类别个数为q。每个锚框anchor的类别个数将是q+1(类别0表示锚框只包含背景)。在某个尺度下,设特征图的高和宽分别为h和w,如果以其中的每个单元为中心生成a个锚框,那么我们需要对hwa个锚框进行分类。如果使用全连接层作为输出,很容易导致模型参数过多。参照NIN网络结构,使用卷积通道来输出类别预测的方法。单发多框检测SSD采用同样的方法来降低模型复杂度。
类别预测层使用一个保持输入高和宽的卷积层。输出和输入在特征图宽和高上的空间坐标一一对应。输出特征图上(x,y)坐标的通道里包含了以输入特征图(x,y)坐标为中心生成的所有锚框anchor的类别预测。因此输出通道数为![]() ,其中索引为
,其中索引为![]() 的通道代表了索引为i的锚框有关类别索引为j的预测。
的通道代表了索引为i的锚框有关类别索引为j的预测。
定义一个类别预测层:指定参数为a和q后,它使用一个填充为1的 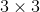 卷积层。该卷积层的输入和输出的高和宽保持不变。
卷积层。该卷积层的输入和输出的高和宽保持不变。
def cls_predictor(num_anchors, num_classes):
return nn.Conv2D(num_anchors * (num_class + 1), kernel_size=3, padding=1)3、边界框预测层
边界框预测层的设计与类别预测层的设计类似。唯一不同的是:这里需要为每个锚框预测4个偏移量,而不是![]() 个类别。
个类别。
def bbox_predictor(num_anchors):
return nn.Conv2D(num_anchors * 4, kernel_size=3, padding=1)输出通道数为anchors的4倍。
4、连结多尺度的预测
单发多框检测根据多个尺度下的特征图生成锚框并通过cls_predictor预测类别,通过bbox_predictor预测偏移量。 由于每个尺度上特征图的形状或以同一单元为中心生成的锚框个数都可能不同,因此不同尺度的预测输出形状可能不同。
假设对同一批量数据构造不同尺度下的特征图Y1和Y2,其中Y2相对于Y1来说高和宽分别减半。以类别预测为例,假设以Y1和Y2特征图中每个单元生成的锚框个数分别为5和3,当目标类别个数为10时,类别预测输出的通道数分别为![]() 和
和![]() 。
。
预测输出的格式为(批量大小,通道数,高,宽)。可以看到,除了批量大小外,其他维度大小均不一样。我们需要将他们变形成统一的格式并将多尺度的预测连结,从而让后续计算更简单。
def forward(x, block):
block.initialize()
return block(x)
Y1 = forward(nd.zeros((2, 8, 20, 20)), cls_predictor(5, 10))
Y2 = forward(nd.zeros((2, 16, 10, 10), cls_predictor(3, 10))
print(Y1.shape, Y2.shape)
# ((2, 55, 20, 20), (2, 33, 10, 10))通道维包含中心相同的锚框的预测结果。我们首先将通道维移到最后一维。因为不同尺度下批量大小扔保持不变,我们可以将预测结果转成二维的(批量大小,高×宽×通道数)格式,以方便之后在维度1上的连结。
def flatten_pred(pred):
return pred.transpose((0, 2, 3, 1)).flatten()
def concat_preds(preds):
return nd.concat(*[flatten_pred(p) for p in preds], dim=1)
如此,尽管Y1和Y2形状不同,我们仍然可以将这两个同一批量不同尺度的预测结果连结在一起。
concat_preds([Y1, Y2]).shape高和宽减半块
Page388页。后续整理。此处换工作后,方向转变,所以作为基础留存。整理为辅,学习为主。
八、区域卷积神经网络(R-CNN)系列
区域卷积神经网络(region-based CNN或regions with CNN features, R-CNN)是将深度模型应用于目标检测的开创性工作之一。该系列有:快速的R-CNN(Fast R-CNN)、更快的R-CNN(Faster R-CNN)以及掩码R-CNN(Mask R-CNN)。
1、R-CNN

首先对图像选取若干提议区域(如锚框也是一种选取方法)并标注它们的类别和边界框(如偏移量)。然后,用卷积神经网络对每个提议区域做前向计算抽取特征。之后我们用每个提议区域的特征预类别和边界框。
步骤如下:
- selective search: 对输入图像使用选择性搜索(selective search)来选取多个高质量的提议区域。这些提议区域通常是在多个尺度下选取的,并具有不同的形状和大小。每个提议区域将被标注类别和真实边界框。
- 卷积提取特征:选取一个预训练的卷积神经网络,并将其在输出层之前截断。将每个提议区域变形为网络需要的输入尺寸,并通过前向计算输出抽取的提议区域特征。
- 支持向量机SVM对目标分类:将每个提议区域的特征连同其标注的类别作为一个样本,训练多个支持向量机对目标分类,其中每个支持向量机用来判断样本是否属于某一个类别。
- 回归分析预测边界:将每个提议区域的特征连同其标注的边界框作为一个样本,训练线性回归模型来预测真实边界框。
R-CNN虽然通过预训练的卷积神经网络有效地抽取了图像特征,但它的主要缺点是速度慢。上千个提议区域,上千次前向计算。
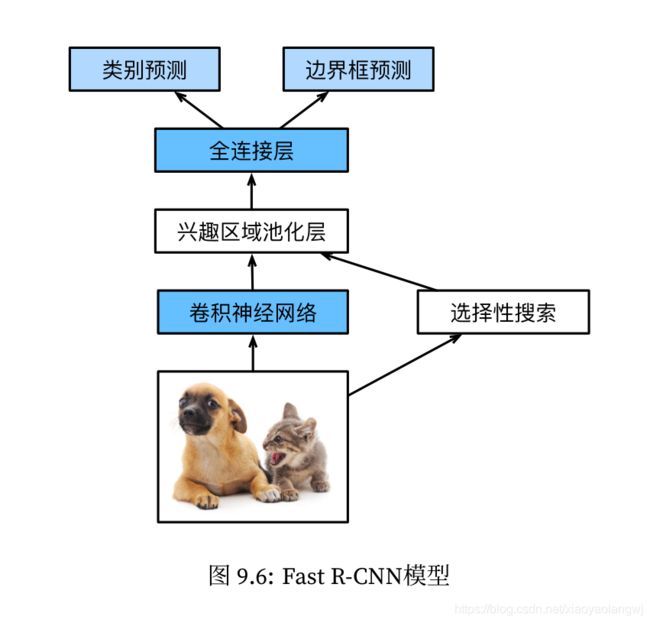
2、Fast R-CNN
R-CNN的主要问题在:需要对每个提议区域抽取特征。这些区域有大量的重叠,独立的特征提取会导致大量的重复计算。Fast R-CNN对R-CNN的一个主要改进在于只对整个图像做卷积神经网络的前向计算。
步骤如下:
- 整个图像做卷积提取特征:与R-CNN相比,Fast R-CNN用来提取特征的卷积神经网络的输入是整个图像,而不是各个提议区域。而且,这个网络通常会参与训练,即更新模型参数。
- 兴趣区域池化层(region of insterest pooling, RoI池化),选择性搜索selective search生成n个提议区域,这些兴趣区域需要通过卷积神经网络提取出形状相同的特征以便于连结后输出。这一步在兴趣区域池化层中完成。
- 全连接层将输出形状变换为
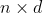 。
。 - 预测类别时,将全连接层的输出的形状再变换为
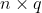 ,并使用softmax回归预测边界框和类别。
,并使用softmax回归预测边界框和类别。
原始输入图像拿来做两件事:一是:进入卷积神经网络提取特征;二是:selective search生成提议区域,然后将形状相同的特征连结输出。
两部分通过兴趣区域池化层连结,输出连结后的各个提议区域抽取的特征。然后接入全连接层输出类别和边界框。
3、Faster R-CNN
Fast R-CNN通常需要在选择性搜索selective search中生成较多的提议区域,以获得较精确的目标检测结果。
Faster R-CNN提出将选择性搜索替换成区域提议网络(region proposal network),从而减少提议区域的生成数量,并保证目标检测的精度。
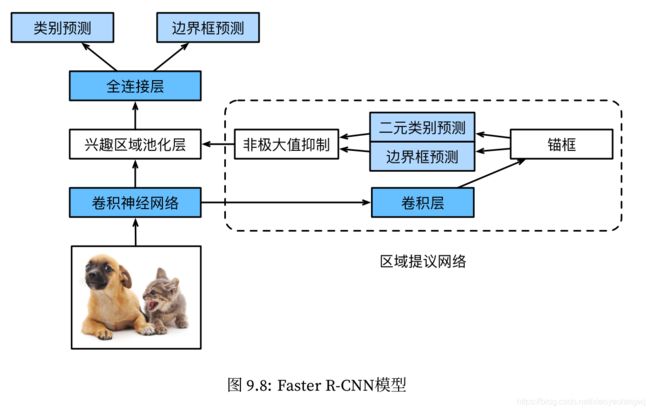
Faster R-CNN和Fast R-CNN相比,只有生成提议区域的方法从选择性搜索变成了区域提议网络。
区域提议网络的计算步骤如下:
-
使用填充为1的
卷积层变换卷积神经网络的输出,并将输出通道数记为c。这样,卷积神经网络为图像抽取的特征图中的每个单元均得到一个长度为c的新特征。 -
以特征图的每个单元为中心,生成多个不同大小和宽高比的锚框并标注它们。
-
用锚框中心单元长度为c的特征分别预测该锚框的二元类别(含目标还是背景)和边界框。
-
使用非最大值抑制,从预测类别为目标的预测边界框中移除相似的结果。最终输出的预测边界框即兴趣区域池化层所需要的提议区域。
值得一提的是,区域提议网络作为Faster R-CNN的一部分,是和整个模型一起训练得到的。Faster R-CNN的目标函数既包括目标检测中的类别和边界框预测,有包括区域提议网络中锚框的二元类别和边界框预测。最终,区域提议网络能够学习到如何生成高质量的提议区域,从而在减少提议区域数量的情况下也能保证目标检测的精度。
4、Mask R-CNN
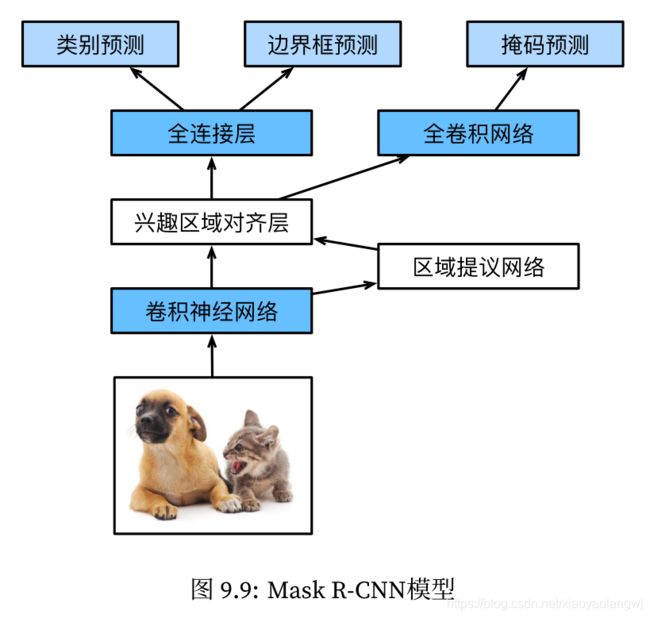
如果训练数据还标注了每个目标在图像上的像素级位置,那么Mask R-CNN能有效利用这些详尽的标注信息进一步提升目标检测的精度。
Mask R-CNN将兴趣区域池化层替换成了兴趣区域对齐层,即通过双线性插值来保留特征图上的空间信息,从而更适于像素级预测。兴趣区域对齐层的输出包含了所有兴趣区域的形状相同的特征图。它们既用来预测兴趣区域的类别和边界框,又通过额外的全卷积网络预测目标的像素级位置。
小结:
-
R-CNN对图像选取若干提议区域,然后用卷积神经网络对每个提议区域做前向计算抽取特征,再用这些特征预测提议区域的类别和边界框。SVM
-
Fast R-CNN对R-CNN的一个主要改进在于只对整个图像做卷积神经网络的前向计算。它引入了兴趣区域池化层,从而令兴趣区域能够抽取出形状相同的特征。
-
Faster R-CNN将Fast R-CNN中的选择性搜索替换成区域提议网络,从而减少提议区域的生成数量,并保证目标检测的精度。
-
Mask R-CNN在Faster R-CNN基础上引入一个全卷积网络,从而借助目标的像素级位置进一步提升目标检测的精度。
九、语义分割和数据集
1、语义分割、图像分割、实例分割
与目标检测相比,语义分割(semantic segmentation)标注的像素级的边框显然更加精细。

图像分割(image segmentation)将图像分割成若干组成区域。例如上图将狗分割成两个区域:一个覆盖以黑色为主的嘴巴和眼睛,另一个覆盖以黄色为主的其余部分身体。
实例分割 (instance segmentation)又叫同时检测并分割(simultaneous detection and segmentation)。研究如何识别图像中各个目标实例的像素级区域。与语义分割不同:实例分割不仅需要区分语义,还要区分不同的目标实例。如果图像中有两只狗,实例分割需要区分像素属于这两只狗中的哪一只。
2、语义分割的数据集
语义分割的数据集:Pascal VOC2012数据集。标签也是图像格式,其尺寸和它所标注的输入图像的尺寸相同。标签中颜色相同的像素属于同一个语义类别。不同颜色标注不同类别。
# 本函数已保存在d2lzh_pytorch中方便以后使用
VOC_COLORMAP = [[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0],
[0, 0, 128], [128, 0, 128], [0, 128, 128], [128, 128, 128],
[64, 0, 0], [192, 0, 0], [64, 128, 0], [192, 128, 0],
[64, 0, 128], [192, 0, 128], [64, 128, 128], [192, 128, 128],
[0, 64, 0], [128, 64, 0], [0, 192, 0], [128, 192, 0],
[0, 64, 128]]
# 本函数已保存在d2lzh_pytorch中方便以后使用
VOC_CLASSES = ['background', 'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair', 'cow',
'diningtable', 'dog', 'horse', 'motorbike', 'person',
'potted plant', 'sheep', 'sofa', 'train', 'tv/monitor']
在卷积神经网络中,我们通过缩放图像使其符合模型的输入形状。然而在语义分割里,这样做需要将预测的像素类别重新映射回原始尺寸的输入图像。但是,这样的映射难以做到精确,尤其在不同语义的分割区域。
为了避免这个问题,我们将图像裁剪成固定尺寸而不是缩放。具体来说:我们使用图像增广里的随机裁剪,并对输入图像和标签裁剪相同区域。
小结:
-
语义分割关注如何将图像分割成属于不同语义类别的区域。
-
语义分割的一个重要数据集叫作Pascal VOC2012。
-
由于语义分割的输入图像和标签在像素上一一对应,所以将图像随机裁剪成固定尺寸而不是缩放。
十、全卷积网络(FCN)
转置卷积层:最大的作用就是上采样。stride小于1的卷积进行上采样,使输出的size变大,所以转置卷积层还有个别称就是分数卷积层。
上采样最常见的场景可以说就是GAN中的生成器网络。虽然论文作者使用的是conv,但由于它的步长为1/2,所以代表的就是转置卷积层。
FCN:
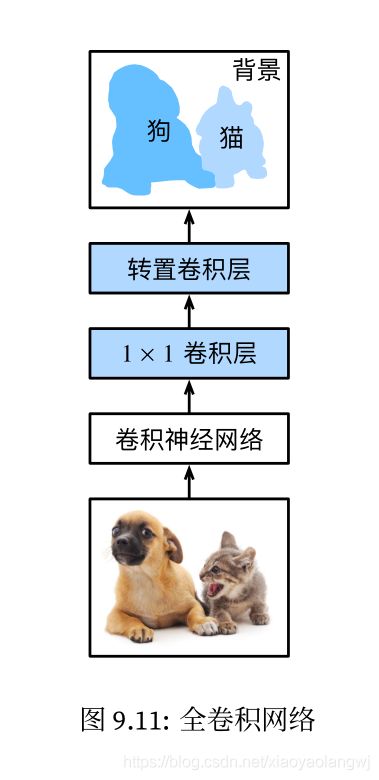
全卷积网络先使用卷积神经网络抽取图像特征,然后通过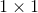 卷积层将通道数变换为类别个数,最后通过转置卷积层将特征图的高和宽变换为输入图像的尺寸。模型输出和输入图像的高和宽相同,并在空间位置上一一对应:最终输出的通道包含了该空间位置像素的类别预测。
卷积层将通道数变换为类别个数,最后通过转置卷积层将特征图的高和宽变换为输入图像的尺寸。模型输出和输入图像的高和宽相同,并在空间位置上一一对应:最终输出的通道包含了该空间位置像素的类别预测。
十一、样式迁移 style transfer
如何使用卷积神经网络自动将图像的样式应用在另一图像上,即样式迁移(style transfer)。
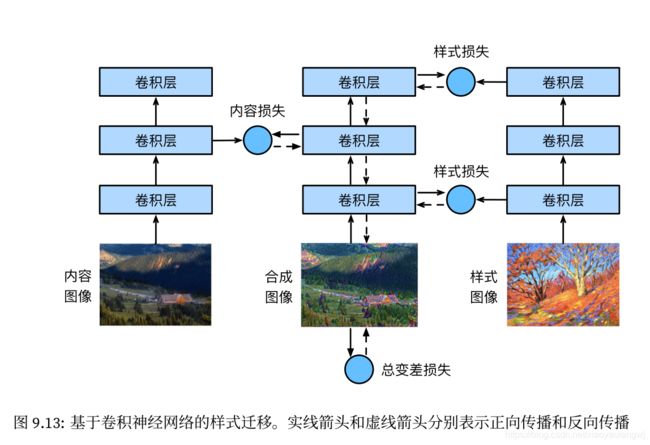
小结:
-
样式迁移常用的损失函数由3部分组成:内容损失使合成图像与内容图像在内容特征上接近,样式损失令合成图像与样式图像在样式特征上接近,而总变差损失则有助于减少合成图像中的噪点。
-
可以通过预训练的卷积神经网络来抽取图像的特征,并通过最小化损失函数来不断更新合成图像。
-
用格拉姆矩阵表达样式层输出的样式。