1.CNN Locale keypoint
2.Light CNN general design
3.Scale Var Light CNN design
1. CNN Locale keypoint
LF-Net 和 RF-Net都在局部特征点的精度上取得了很高的成绩,但是这些网络的速度远达不到机器人SLAM实时使用的程度。
受到近年来轻量级网络设计的启发,我们在LF-Net 和 RF-Net基础上改进了网络结构,面对通道信息沟通不畅问题,我们借鉴了ShuffleNetV2的思想 ,有效提高了精度和速度。
针对LF-Net 和 RF-Net都存在的尺度空间上不平衡的问题,我们改进了提取尺度方式,得到了有效的解决。
最终我们的成果能够实际应用在SLAM系统中,并具有很高的精度和鲁棒性。
2. Light CNN general design
"Tuning deep neural architectures to strike an optimal balance between accuracy and performance has been an area of active research for the last several years."
To achieve this goal generally there are two approaches, one is to compress pretrained networks which called Model Compression the other is to directly design small networks.
Recently there has been many achievements in faster convolutional blocks, Including SqueezeNet, MobileNetV1/2, ShuffleNetV1/2, IGC v1/v2/v3.
The direct metric depends on many factors such as memory access cost, ...
2.1 Depthwise Separable Convolutions
The basic idea about Depthwise Separable Convolutions is that a full convolutional operator can be split into two separate layers : a depthwise convolution and a 1X1 convolution which called pointwise convolution.
Traditional convolutional operater apply a K*K size kernal to filter all input feature maps, thus each feature map of the output maps contain information from all maps of the input map. For example consider input is a W X H X C size maps, we want output to be W X H X K size, we apply 3 X 3 X K shape convolution kernal, the operation is :

Depthwise separable convolutions are a drop-in replacement for standard convolutional layers.
Firstly, we do a channel-by-channel convolution (Depth-wise convolution), which means for the input feature maps one channel is only filtered by one convolution kernal.
Secondly, after Depth-wise convolution the feature maps are seperated by channels,because "Each feature map of the output maps should contain information from all other maps of the input layer" we do Pointwise convolution
to help output maps exchange information. Pointwise convolution is simplely a 1X1 convolution.
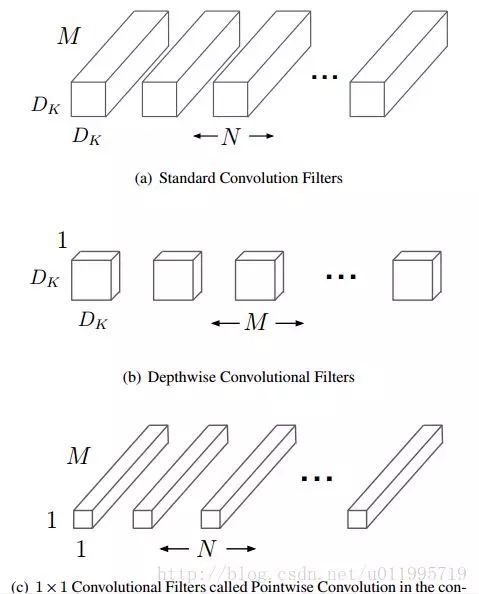

Depthwise Separable Convolutions can not only reduce network parameters but also drop computation costs.
Convolution Size : D_K
Input Channels : M
Output Channels : N
Output feature map size : D_F
Tradition convolution:
parameters:
computation:
Depthwise separable convolution:
parameters:
computation:
So the computational complexity decreases to the original:
2.2 MobileNet
The main idea about MobileNet is :
- Use depth-wise convolution operation. Compared with standard convolution operation, under the same parameter number , it can reduce the amount of calculation by several times, so as to improve the speed of network.
- To solve the "poor information flow" problem of using depth-wise convolution, MobileNet uses point-wise convolution.
2.3 MobileNet V2
MobileNet V2 mainly solves the problem that V1 is easily degraded in training process, so V2 has improvement compared with V1.
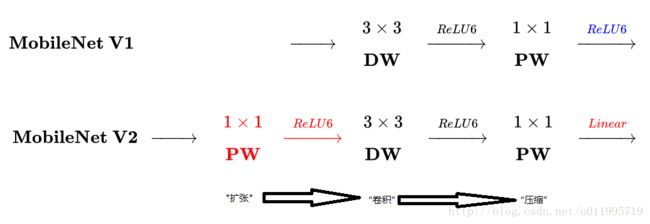
2.4 ShuffleNet
Use group convolution and channel shuffle, thus reduce the cost of 1X1 convolution in MobileNet.
To solve the proble “outputs from a certain channel are only derived from a small fraction of input channels.“
Channel shuffle is as shown below:
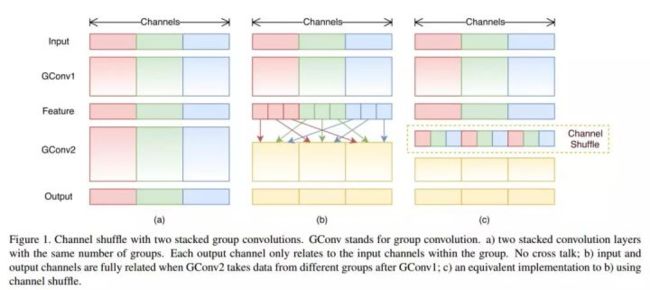
Channel shuffle's operation is simple. Like ResNet architecture ShuffleNet create the basic bottleneck unit, and then uses basic bottleneck units stacked to obtain ShuffleNet.

The main contributions in this artical are as follows:
- Like MobileNet, depth-wise convolution is adopted in ShuffleNet, but it uses a channel shuffle operation to solve the side effect of depth-wise convolution.
- It is critical that tiny networks usually have an insufficient number of channels to process the information.
- In terms of network topology, ShuffleNet adopts the idea of resnet, while mobielnet adopts the idea of VGG.
2.5 ShuffleNet V2
Comparison Module Design of ShuffleNet_V2 and ShuffleNet_V1:

ShuffleNet V2 abandons the 1x1 group convolution operation and directly uses 1x1 ordinary convolution with the same number of input/output channels. It also proposes a new Channel-Split operation, which divides the input channels of module into two parts, one part is passed down directly, the other part is calculated backwards. At the end of module, the output channels from two branches are connected directly, thus avoiding the operation of Element-wise sum in ShuffleNet v1. Then we do the Random Shuffle operation on the output feature maps to get the final output, so that the information between the channels can communicate with each other.
2.6 Conclusion
- Use Depthwise Separable Convolutions to speed Network
- Find ways to solve channel information exchange
3. Multi-Scale CNN design
- 图像级别金字塔
- Feature Map 级别金字塔
- Backbone 金字塔
- 多种融合
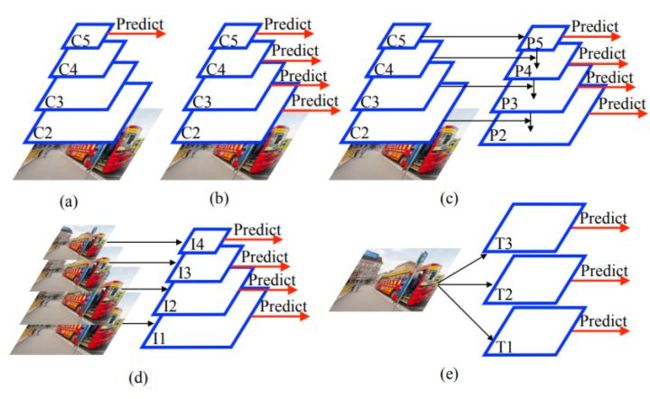
LF-Net, RF-Net use feature pyramids
LIFT, Key.Net use image pyramids
SuperPoint, D2-Net do not use scale
LF-Net and RF-Net both achieve high accuracy in Locale keypoints detection and description. but they are very slow and has some problems.
SE是一个注意力机制,就相当于给每一个Feature map一个权重。首先通过一个Avgpool得到一个一维的向量,元素个数和Feature map数目一样。然后两个带ReLU的全连接层,最后加一个带h-sigmoid的全连接层。