共轭梯度法及其浅显分析
更多内容请关注我的个人博客
浩源小站
背景
无处不在的线性方程组,昭示着一个优秀的算法能带来的巨大效益。对于简单的低阶方程组,只需要用普通的高斯消元法就能得到相当不错的结果,但是对于大型的方程组,常常与之相伴的就是稀疏性,如果还坚持使用高斯消元法,那么将带来的是空间上的巨大浪费。为此,迭代法求解方程组便应运而生。
共轭梯度法就是其中的佼佼者。
由来
二次型的最小值
我们熟知的线性方程组,常常可以写成的形式,实际上当是实对称矩阵时,就是二次型对的导数为0时的表达式。
当为实对称矩阵的时候,就等价于.
而我们求解线性方程组的问题,也可以转化成求解
举个例子,当
时,的图如下

等高线图如下

看得出,此时的函数具有唯一的最小值。
由代数学的知识,我们知道,当矩阵为正定、半正定、负定、以及不定的时候,方程组具有不同的解的情况。对应则是不同的最小值情况。
下面这幅图说明了矩阵A的性质对于的影响,依次是正定、负定、半正定和不定的情况。

可以看到,当不定的时候,具有鞍点,这个时候无法通过导数为0来求得最值。
在接下来的共轭梯度方法中,我们都首先假定,具有良好的性质,也就是对称和正定。
最速下降法(梯度下降法)
如何得到的最小值?
有一个形象的方法,从任意一点出发,每次沿着当前位置下滑最快的方向走,也就是该点处的梯度方向。
从而得到一系列的解序列:直到两次下降的差小于给定的误差限为止。
由上面的结论,,下面记误差(error)为,残差(residual)为
于是有
其中为第步沿着方向的步长
如何选取步长呢?朴素的想法是选取的步长尽量要让的值最小,这样才能更快的到达的全局最小值。
从简单的微积分知识中,我们把看作是的函数,要使得步长最合适,也就相当于
根据链式法则
也就是说,与正交
也就是说,每一步的步长都可以根据当前的残差来确定
总结一下,最速下降法就是:
这样迭代下去,直到达到事先给定的误差限为止
当然,有的时候,出于减小复杂度的考虑,我们会换用这种手段来求
这个公式是在的两边左乘再加上得到的。
这样每次迭代过程我们只需要算一次矩阵乘法,可以减少运算。
雅可比迭代法
在开始共轭梯度法前,我们还需要再来看看它的同行们都是怎么干活的。
对于方程,我们把分成两个矩阵和,其中是对角阵,而是剩下的部分,也就是说:
这里由于是对角阵,所以能保证它的可逆性。
这里为了便于分析,把上面的式子写作
其中
下面考察该方法迭代过程的收敛性,依旧把误差(error)记作
故而
这里判断迭代过程的敛散性主要看矩阵的性质,如果是实对称矩阵,那么就可以用的特征向量线性表示,迭代过程就可以写成:(下面以二阶矩阵为例)
其中分别是矩阵的特征向量的特征值。
由此看得出,如果的最大的特征值小于1,这个迭代过程就收敛,不然迭代过程会发散。
而一个矩阵的最大特征值也就是它的谱半径(spectral radius)
对于B不是实对称矩阵的情况,也有类似的结论,只是说明过于复杂,在此不提。
总之,雅可比迭代法收敛的充分条件是迭代矩阵的谱半径
下面还是以最初的方程举例子,来分析雅可比迭代的具体过程,这有助于改进迭代过程,得到更好的算法
迭代过程现在是
此时的特征向量以及与其对应的特征值分别为
$$
x_1=\left[
\begin{matrix}
\sqrt2\1
\end{matrix}
\right],\lambda_1=-\frac{\sqrt2}{3}\
x_2=\left[
\begin{matrix}
-\sqrt2\1
\end{matrix}
\right],\lambda_1=\frac{\sqrt2}{3}\
$$
下图是迭代过程中,二次型函数的等高线图,注意两个箭头分别表示特征向量
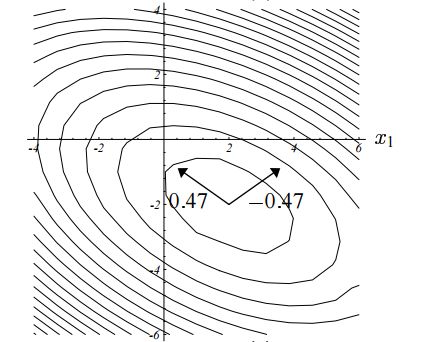
而下图则是迭代过程

考虑每一次迭代与特征向量的关系
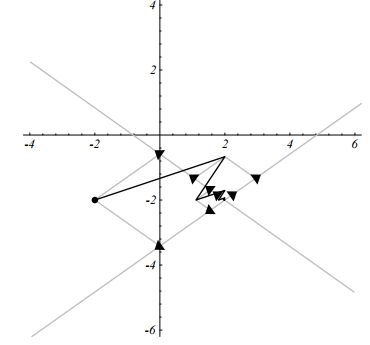
我们会发现,每一次的迭代都朝着两个特征向量的线性组合方向前进。
最速下降法的分析
前面我们得到了最速下降法的迭代过程,并且得到了一个十分有意思的结论
$$
r_{(i+1)}^Tr_{(i)}=0
$$
这意味着,最速下降法每一次的迭代过程,下降的方向都与上一次的方向正交。
用具体例子来表述是这样的:
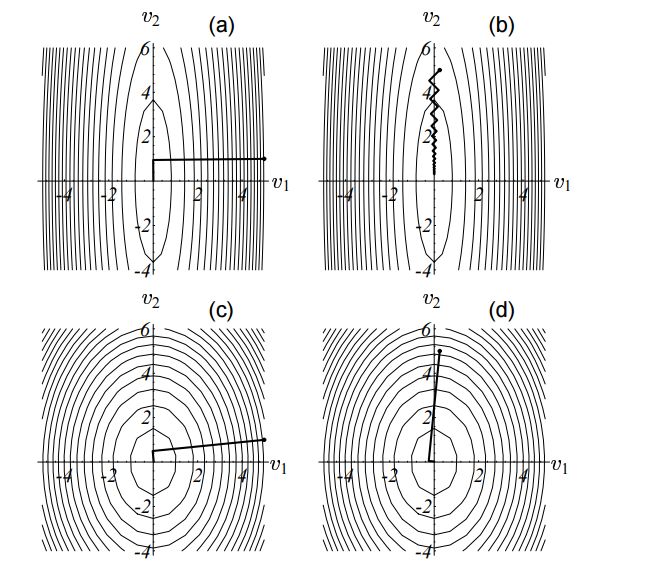
可以看到,(b)是最差的情况,需要蜿蜒前进很多次才接近解,而其他比较好的情况则两次迭代就收敛了.
但即便迭代的次数不同,每一次迭代的方向都与上一次正交,这就是最速下降法的特点。
在(b)中还有一个情况值得注意,由于这是一个二维的图形,故而如果每一次都和上一次正交,那么相邻一次迭代的方向是平行的!
换句话来说,在最速下降法中,有一个很糟糕的现象,为了收敛到解附近,同样的迭代方向可能走了不止一次。
这个现象不只是最速下降法中会出现,雅可比迭代法中也同样的出现了,表现就是每一次的方向都是特征向量的线性组合,而且大多数情况下,前一次迭代过的特征向量方向上的分量,在下一次的迭代中还继续存在。
共轭的想法
如果我能选取一系列线性无关的方向向量,沿着每个方向只走一次,最后就能到达解处,是不是能很好的解决前面雅可比迭代和最速下降法的问题?
最直接的想法来源于直角坐标系,如果每一个方向都是正交的,既自然,有具有很好的性质,是不是能得到很好的结果呢?
如果这样选取了方向,那么应该有误差与方向正交
所以
但是这里步长大小依赖于当前的误差,而不知道正确解是无法求出误差来的,故而这种想法虽然很自然,但是无法得到有用的结果。
考虑到矩阵具有变换向量的作用,不妨记为向量关于矩阵共轭。
接下来选取的一系列方向向量都关于矩阵两两共轭,
我们从上一个想法得到灵感,要求这里的也与共轭,这是很自然的,只需要想象是对原本的空间做了一个变换,原本不正交的向量在这里正交,那么这里的要求就是合乎情理的了。
下面也一样,对步长大小进行简单的分析
所以得
这里得到的步长不仅可以算,而且可以证明,这样迭代,对于n阶的方程组,至多n步就可以收敛到正确解。
简单的证明
首先,把误差表示为方向向量的线性组合
两侧左乘 有:
上式利用了之前提到的共轭性质,由此得
与上面的步长比较,有
于是对于第步迭代的误差
由此可知,当的时候,
并且我们能从上面的证明中得到这样一个事实,第迭代时,有关前次迭代的方向上都已经没有误差了,也就是这样的方法,每次都完全消除某个方向上的误差,这样至多步得到精确解就是很自然的了。
共轭梯度法
上面的由来中,已经充分做好了准备来得到共轭梯度法,现在只剩一个问题,那一组两两共轭的方向向量该如何选取?
选取了一组基后,只需要进行Gram-Schmidt正交化就可以得到一组正交基,那么同样的也可以用这样的方法来得到一组共轭的方向向量。
问题是,如果随便选取一组线性无关的方向基,就进行Gram-Schmidt共轭化是否足够好呢?
我们总希望这组方向基不仅容易得到,而且具有很好的性质,减少计算量。
考虑到之前得到的结论,每一次迭代之间的残差都是相互正交的,我们不妨就选残差
作为共轭化之前的基。由于使用共轭化的方向向量来迭代至多只有n步,且每步都将该方向上的误差消灭掉,故而这一组基不仅线性无关,而且由于它们是残差,还具有正交的良好性质。
推导
首先,对于第+1次迭代后的残差有
接着我们来推导一下Gram-Schmidt共轭化的公式
第次的方向向量为,我们希望从中得到
,也就是
在上式的两侧同左乘上有
下面来结合残差,继续做一些推演
在两侧同左乘
$$
\begin{align*}
r_{(i)}Tr_{(j+1)}&=r_{(i)}Tr_{(j)}-\alpha_{(j)}r_{(i)}^TAd_{(j)}\
\alpha_{(j)}r_{(i)}TAd_{(j)}&=r_{(i)}Tr_{(j)}-r_{(i)}^Tr_{(i)}\
\end{align*}
$$
故而
结合的值,有
$$
\beta_{ij}=
\left{
\begin{align}
\frac{1}{\alpha_{i-1}}\frac{r_{(i)}Tr_{(i)}}{d_{(i-1)}TAd_{(i-1)}}&,\quad i=j+1\
0&,\quad i>j
\end{align}
\right.
$$
考虑到完全可以把写成,因为只能取固定的值。
神奇的事情发生了,原本需要个才能确定的方向向量,在共轭化的条件下,只需要当前的数据和前一步的数据就可以得到,而不必存储之前所有走过的路径信息。
结合前面得到的
实际上,上面的式子还能够写成更加漂亮的样子
先由
做其与的内积有
令有
带入中有
这样,Gram-Schmidt共轭化就完美的实现了,不仅实现了每一个方向只迭代一次,而且需要存储的数据只有上一步的残差。
下面是共轭梯度法涉及到的所有公式
最后给出共轭梯度法的Matlab实现
function x=Conjugate_gradient(A,b,x0)
x=x0;
d=b-A*x0;
r=d;
for k=0:size(A)-1
if r==0
break;
end
alpha=(r'*r)/(d'*A*d);
x=x+alpha*d;
temp=r'*r;
r=r-alpha*A*d;
belta=(r'*r)/(temp);
d=r+belta*d;
end
end
分析
正交性是共轭梯度法成功的关键,注意到每一次迭代中,新的残差与前面所有的正交,如果一个那么方程已经解完了。
否则在n步迭代后,和n个两两正交的向量所张成的空间正交,而这n个向量是空间中的所有正交向量,由此必须是零向量,所以
比较
共轭梯度法从某种程度上要简单于高斯消元法,不必考虑行和列的相消,而且代码实现也十分简洁。下面来比较一下共轭梯度法和高斯消元法在复杂度上的优势。
共轭梯度法的每一次迭代都要做一次矩阵向量乘法和一些向量内积的计算,复杂度为,当做完n次迭代后,复杂度变成了,而高斯消元法只是左右,从这一点上,当矩阵不是稀疏矩阵的时候,共轭梯度法没有优势,而当矩阵变得稀疏的时候,n大的惊人,高斯消元法如果要得到解,就必须要做完所有的运算才能得到解,这样需要消耗大量的资源。而共轭梯度法不一样,它每一次迭代都能在某个分量上得到解,并且可以通过残差来度量解的精确情况,我们并不需要将算法进行到底,只需要解达到精度要求就可以退出。
同样的,与其他迭代法相比,共轭梯度法又能在确定的步数内收敛,这就是共轭梯度法的优势。
但是,当矩阵变成病态矩阵的时候,由于每一步的误差的累计,很有可能导致方向向量出现偏差,从而出现很糟糕的结果,这也是共轭梯度法的一个缺陷,我们可以通过预条件处理来减小病态矩阵带来的误差。
预条件处理
预条件处理的思想是降低方程系数矩阵的条件数,方法是左乘一个矩阵。
即
其中是可逆的n阶矩阵,称为预条件子
常用的预条件子有:
- 雅可比预条件子:,是的对角矩阵
- 高斯-塞尔德预条件子:,其中,分别是下三角、对角、上三角矩阵,是介于0和2之间的常数