时间、空间复杂度:衡量算法执行小路的指标,数据结构与算法离不开时间、空间复杂度分析,复杂度分析是算法的精髓。
为什么需要分析复杂度
为什么不直接去运行代码然后测试运行速度?
1、环境影响大
不同的硬件条件下处理器的处理速度不一样导致的性能差
2、数据集对结果的影响
如果数据规模较小,测试结果就无法真实反映算法效率
复杂度分析是一个不需要具体测试数据来测试,粗略计算出执行效率的一种方法。
大O复杂度表示法
算法复杂度其实就是算法代码执行的时间。
如何不运行代码粗略估算时间:
int sum(int n){
int i=0;
int sum=0;
for(;i用上面这个累加算法为例子说明,因为是粗略计算,现在假定CPU执行一行代码的时间为t,然后整个sum方法的执行时间为:1+1+n+n+1=(2n+3)*t;可以看出代码总的执行时间和n成正比,总结出大O表示公式为:
其中,T(n)表示代码执行的时间,n为数据集规模,f(n)是一个公式,以上述例子说明就是2n+3,所以T(n)=O(2n+3),
大O表示法只是代表代码执行的时间的变化趋势,并不能得出真正执行时间,所以也叫渐进时间复杂度,简称时间复杂度。当n趋向于很大时,常数项的影响微乎其微,所以我们常常将常公式中公式中的低阶、常量、系数三部分去掉。所以,上述例子就可以表示为:
常用时间复杂度分析方法:
1、只关注循环最多的一段代码
由于大O复杂度表示方法只是表示一种变化趋势,常量、低阶和系数这些并不会对变化趋势造成很大影响,所以我们一般选择忽略。
2、加法法则
如下代码:
int cal(int n) {
int sum_1 = 0;
int p = 1;
//T1
for (; p < 100; ++p) {
sum_1 = sum_1 + p;
}
int sum_2 = 0;
int q = 1;
//T2
for (; q < n; ++q) {
sum_2 = sum_2 + q;
}
int sum_3 = 0;
int i = 1;
int j = 1;
//T3
for (; i <= n; ++i) {
j = 1;
for (; j <= n; ++j) {
sum_3 = sum_3 + i * j;
}
}
return sum_1 + sum_2 + sum_3;
}
我们只关注循环部分,T1、T2、T3,由于T1只循环100此,跟n无关,可以忽略,T2=O(n),T3=O(n^2),有这么一个结论:代码总的时间复杂度等于量级最大的那段代码的时间复杂度:
所以上面这个例子的时间复杂度为O(n^2)
3、乘法法则
例子:
//Tn
int fun1(int n) {
int sum1 = 0;
int i = 1;
//T1
for (; i < n; ++i) {
sum = ret + f(i);
}
}
int fun2(int n) {
int sum2 = 0;
int i = 1;
//T2
for (; i < n; ++i) {
sum2 = sum2 + i;
}
return sum2;
}
由于T1里循环执行了fun2方法,fun2里T2=O(n),T1也是O(n),所以总的时间复杂度就是:
总结乘法公式:
若:T1(n)=O(f(n)),T2(n)=O(g(n)),则Tn=T1(n)T2(n)=O(f(n))O(g(n))=O(f(n)*g(n))
常见复杂度量级
| 多项式量级 | 非多项式量级 |
|---|---|
| 常量阶O(1) | 指数阶O(2^n) |
| 对数阶O(logn) | 阶乘阶O(n!) |
| 线性阶O(n) | |
| 线性对数阶O(nlogn) | |
| N次方台阶O(n^N) |
差别:非多项式阶在数据随着n增大,时间会爆炸式增加,这类是非常低效的算法,不推荐使用。
1、O(1)
常量级复杂度,比如代码只有5行10行或者1000行这些,只要代码的执行时间不随n增大而增大,有限数量级的都归为O(1)复杂度;我们平时在分析时,只要代码不存在循环、递归语句,代码再多,也可以算是O(1)复杂度。
2、O(logn)、O(nlogn)
对数阶复杂度,比如下面这样的代码:
int i=1;
while(i<=n){
i=i*2;
}
循环终结条件是i<=n,
n=2^x,求出x就能得出代码,其中

举个栗子:我们上面的2换成3,会有复杂度为:
上面说过分析复杂度时常数可以去掉不算,推导下来还是会算回以2为底时一样的复杂度,因此,我们可以将对数的底忽略掉,统一用O(logn)表示。
3、O(m+n)
m、n为两个不同数量级的数据,且无法确定谁大谁小,也就不能根据前面的加法法则来说胜率掉某一个,这个时候算法复杂度就得改为:
T(n)=T1(m)+T2(n)=O(f(m))+O(f(n))=O(m+n)
空间复杂度
算法复杂度分时间复杂度和空间复杂度,上面分析了时间复杂度,空间复杂度分析原理是一样的,时间复杂度算的是代码运行的时间,而空间复杂度则算代码所占用的内存大小,举个栗子:
void fun(int n){
int i=1;
int[] arr=new int[n];
for(;i跟时间复杂度一样,i常量声明所占用的空间为1,可以忽略,我们着重看循环部分,没循环一次就要申请一次内存,所以整个代码的空间复杂度为O(n)。
最好、最坏时间复杂度
例子:
int findItem(int[] array,int x){
int n=array.lenth;
int item=-1;
for(int i=0;i上面这段代码是在一个数组中找到某个值的下标,这段代码的复杂度如果用上面介绍的几种方法是没办法准确得出复杂度的,分析它需要用到新的复杂度概念:最好、最坏时间复杂度;加入我们要找的元素在第一个位置,那么只要运行一次的循环就可以结束代码,那么复杂度就是O(1),如果很不幸,我们要找的元素根本不在数组中,那么就会出现需要循环n次才能结束代码,那么此时的复杂度就变为O(n)了,这两个就是分别对应最好、最坏时间复杂度。
平均时间复杂度
前面的最好最坏时间复杂度对应的都是极端情况下的复杂度,没办法作为衡量算法好坏的标准,所以就引入了平均时间复杂度。我们继续分析上面的代码例子,首先列出所有的可能,一共会有n+1中情况,当我们要找的元素在数组n到n-1中某一个时有n中可能,此时需要遍历的次数分别为1到n次,再加上一种就是元素不在数组中,此时也需要遍历n次,所以一共需要遍历的次数加起来就是1+2+3+...+n+n,然后算一下每一项的概率,由于存在在或者不在数组的情况,假定概率都为1/2,然后在的情况下每项的概率又为1/n,所以组合起来就是1/2n,然后开始求和,公式为:
N=1*1/2n+2*1/2n+3*1/2n+...+n*1/2n+n*1/2
最后这个n为要找的元素不在数组里,所以乘上的概率是1/2.
所以平均时间复杂度O(n)为:
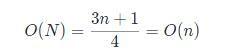
均摊时间复杂度
均摊时间复杂度分析的情况是,比如一个算法,在大多数情况下复杂度都为O(1),但当符合某个条件时会变为O(n),然后这个时候均摊时间复杂度就能有所用处了。比如java中ArrayList的自动扩容:
add()方法的源码如下:
public boolean add(E e) {
ensureCapacityInternal(size + 1);
elementData[size++] = e;//添加对象时,自增size
return true;
}
private void ensureCapacityInternal(int minCapacity) {
modCount++;//定义于ArrayList的父类AbstractList,用于存储结构修改次数
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);//新容量扩大到原容量的1.5倍,右移一位相关于原数值除以2。
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;//MAX_ARRAY_SIZE和Integer.MAX_VALUE为常量,详细请参阅下面的注解
}
在容量充足的情况下,只需要执行插入操作,此时复杂度为O(1),但是当容量满了的时候,就需要扩容,此时的复杂度变为O(n),然后算均摊时间复杂度,假设在到达刚好扩容的数据一共有n个,那么前n种复杂度都为O(1),第n此为O(n),每种情况的概率都为1/n+1,最后:
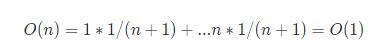
总结
基本复杂度分析到这就学完了,这些方法都会贯穿整个算法学习的全部,所以要牢固掌握。