经典机器学习方法(6)—— 非线性支持向量机器与核技巧
- 参考:
- 《统计学习方法(第二版)》第 7 章
- 白板机器学习
- 菜菜的 sklearn 课堂
支持向量机器(support vector machines, SVM)可以看作之前介绍过的 经典机器学习方法(4)—— 感知机 的升级版,它们都是用于处理二分类问题的判别模型,SVM 进一步解决了感知机只能处理线性可分样本数据、结果不唯一、只能给出线性分类面等问题。SVM 方法包含从简单到复杂的一系列模型,其中简单模型是复杂模型的特殊情况;复杂模型是简单模型的推广,和感知机对比如下模型 适用问题 数据要求 求解策略 得到分类超平面 感知机 线性二分类问题 线性可分 误分类最小化 线性,不唯一 线性可分支持向量机器 线性二分类问题 线性可分 硬间隔最大化 线性,唯一 线性支持向量机器 线性二分类问题 近似线性可分 软间隔最大化 线性,不唯一 非线性支持向量机器 非线性二分类问题 无 核计巧 + 软间隔最大化 非线性,唯一 - 需要注意的一点是,无论感知机还是 SVM 本质都是线性分类器,它们都是先把输入空间(欧式空间或离散集合)中的样本特征映射到特征空间(欧式空间或希尔伯特空间)中,使之成为特征空间里的一个线性二分类问题进行求解
- 上篇文章 经典机器学习方法(5)—— 线性支持向量机器 介绍了这里的前两种 SVM 模型,它们分别要求数据线性可分和近似线性可分,这时特征空间和输入空间相同
- 本文介绍最后一种非线性 SVM,其思想是先用映射函数将输入空间的非线性可分数据映射为特征空间中的线性可分数据,然后就能在特征空间直接用线性 SVM 算法进行分类了,这时特征空间和输入空间不同。特征空间通常是高维的,常用核技巧降低计算复杂度
文章目录
- 1. 核技巧
-
- 1.1 从 SVM 二分类模型到核函数
-
- 1.1.1 非线性带来高维转换
- 1.1.2 对偶问题带来内积
- 1.2 核函数
-
- 1.2.1 两种等价定义
- 1.2.2 核的再生性(证明等价定义)
- 1.2.3 深入分析再生核希尔伯特空间
- 1.2.4 常用核函数
- 2. 非线性支持向量机
- 3. 利用 sklearn 实现支持向量机
-
- 3.1 SVC 类
- 3.2 线性 SVM 分类器
-
- 3.2.1 处理线性可分数据
- 3.2.2 处理非线性数据
- 3.3 非线性 SVM 分类器
-
- 3.3.1 SVC在非线性数据上的推广
- 3.3.2 sklearn 中的核函数
- 3.3.3 对比不同的核函数
1. 核技巧
- 核技巧是统计学习中的一个常用 trick,除了非线性 SVM 外还应用于许多其他问题。
1.1 从 SVM 二分类模型到核函数
- 本节介绍 SVM 背景下,引入核技巧的两个原因:“非线性带来高维转换” & “对偶问题带来内积”
1.1.1 非线性带来高维转换
非线性分类问题是指通过非线性模型才能很好地进行分类的问题,其输入空间中的分离超平面是非线性的。比如
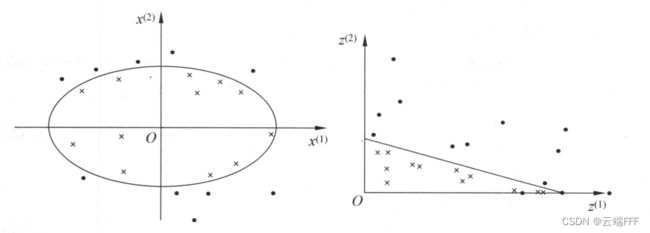
左图是输入空间中的原始样本和最优分离超平面,由于非线性问题不好求解,我们想通过一个非线性变换将样本和分离超平面都变换到右图所示的特征空间中,使数据线性可分。设输入空间为 X ∈ R 2 , x = ( x ( 1 ) , x ( 2 ) ) ⊤ ∈ X \mathcal{X}\in \mathbb{R}^2, x =(x^{(1)},x^{(2)})^{\pmb{\top}}\in \mathcal{X} X∈R2,x=(x(1),x(2))⊤⊤∈X,特征空间为 Z ∈ R 2 , z = ( z ( 1 ) , z ( 2 ) ) ⊤ ∈ Z \mathcal{Z}\in \mathbb{R}^2, z =(z^{(1)},z^{(2)})^{\pmb{\top}}\in \mathcal{Z} Z∈R2,z=(z(1),z(2))⊤⊤∈Z,为了实现上图所示的变换,可以定义非线性映射为
z = ϕ ( x ) = ( ( x ( 1 ) ) 2 , ( x ( 2 ) ) 2 ) ⊤ z = \phi(x) = ((x^{(1)})^2,(x^{(2)})^2)^{\pmb{\top}} z=ϕ(x)=((x(1))2,(x(2))2)⊤⊤ 这样处理后,输入空间中的椭圆分离曲面
w 1 ( x ( 1 ) ) 2 + w 2 ( x ( 2 ) ) 2 + b = 0 w_1(x^{(1)})^2 + w_2(x^{(2)})^2 + b=0 w1(x(1))2+w2(x(2))2+b=0 就变成了特征空间中的直线分离平面
w 1 z ( 1 ) + w 1 z ( 2 ) + b = 0 w_1z^{(1)} + w_1z^{(2)} + b =0 w1z(1)+w1z(2)+b=0- 核技巧应用于支持向量机,其基本想法就是通过一个非线性变换 ϕ \phi ϕ 将输入空间 X \mathcal{X} X(欧式空间 R n \mathbb{R}^n Rn 或离散集合)的数据映射到特征空间 H \mathcal{H} H(希尔伯特空间),使得在输入空间中的超曲面模型对应于特征空间中的超平面模型,这样,分类问题通过在特征空间中求解线性支持向量机就能完成
需要注意的是,特征空间通常维度很高,这里有一个
Cover定理,可以定性地描述为:将复杂的模式分类问题非线性地投射到高维空间中,将比投射到低维空间更可能是线性可分的。把数据变化到越高维的空间,就越容易找出线性的分离超平面
1.1.2 对偶问题带来内积
- 回顾上篇文章的推导,可以发现线性 SVM 对偶问题中,无论优化目标函数
min α − 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j ( x i ⊤ x j ) + ∑ i = 1 N α i s.t. ∑ i = 1 N α i y i = 0 0 ≤ α i ≤ C , i = 1 , 2 , ⋯ , N \begin{aligned} &\min_{\pmb{\alpha}} &&-\frac{1}{2} \sum_{i=1}^N \sum_{j=1}^N \alpha_i \alpha_j y_i y_j\left(\pmb{x}_i^{\pmb{\top}} \pmb{x}_j\right)+\sum_{i=1}^N \alpha_i\\ &\text { s.t. } && \sum_{i=1}^N \alpha_i y_i=0 \\ && &0\leq \alpha_i \leq C, \quad i=1,2, \cdots, N \end{aligned} ααmin s.t. −21i=1∑Nj=1∑Nαiαjyiyj(xxi⊤⊤xxj)+i=1∑Nαii=1∑Nαiyi=00≤αi≤C,i=1,2,⋯,N 还是决策函数(分离超平面)
f ( x ) = sign ( ∑ i = 1 N α i ∗ y i ( x ⊤ x j ) + b ∗ ) f(\pmb{x}) = \text{sign}\Big(\sum_{i=1}^N\alpha^*_iy_i(\pmb{x}^{\pmb{\top}} \pmb{x}_j)+b^*\Big) f(xx)=sign(i=1∑Nαi∗yi(xx⊤⊤xxj)+b∗) 都只涉及输入样本特征向量之间的内积 - 如果我们按 1.1 节的思路,使用映射函数 ϕ : X → H \phi:\mathcal{X}\to \mathcal{H} ϕ:X→H 将输入空间中样本的特征向量转换到特征空间中操作,就要计算大量内积 ϕ ( x i ) ⊤ ϕ ( x j ) \phi(\pmb{x}_i)^{\pmb{\top}}\phi(\pmb{x}_j) ϕ(xxi)⊤⊤ϕ(xxj),由于特征空间维度可能很高(甚至是无穷维),计算高维内积的复杂度非常高,如果我们能找到一个函数 K : X × X → R K:\mathcal{X}\times \mathcal{X}\to \mathbb{R} K:X×X→R 使得 ∀ x , z ∈ X \forall \pmb{x},\pmb{z}\in \mathcal{X} ∀xx,zz∈X 满足
K ( x , z ) = ϕ ( x ) ⊤ ϕ ( z ) K(\pmb{x},\pmb{z}) =\phi(\pmb{x})^{\pmb{\top}}\phi(\pmb{z}) K(xx,zz)=ϕ(xx)⊤⊤ϕ(zz) 那么就能大幅减少计算高维内积的复杂度,这时的优化目标和决策函数变为
优化目标 : − 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j K ( x i , x j ) + ∑ i = 1 N α i 决策函数 : f ( x ) = sign ( ∑ i = 1 N α i ∗ y i K ( x i , x ) + b ∗ ) \begin{aligned} &优化目标:-\frac{1}{2} \sum_{i=1}^N \sum_{j=1}^N \alpha_i \alpha_j y_i y_jK(\pmb{x}_i,\pmb{x}_j)+\sum_{i=1}^N \alpha_i\\ &决策函数:f(\pmb{x}) = \text{sign}\Big(\sum_{i=1}^N\alpha^*_iy_iK(\pmb{x}_i,\pmb{x})+b^*\Big) \end{aligned} 优化目标:−21i=1∑Nj=1∑NαiαjyiyjK(xxi,xxj)+i=1∑Nαi决策函数:f(xx)=sign(i=1∑Nαi∗yiK(xxi,xx)+b∗) - 实际应用中,我们并不显式地找出映射函数 ϕ \phi ϕ 和对应的特征空间 H \mathcal{H} H 来构成 K K K,而是直接找到一个满足定义的 K K K 并按上述形式使用,这就等价于隐式地利用某个 ϕ \phi ϕ 变换到某个特征空间中 H \mathcal{H} H 进行线性分类。这个技巧就称为
核技巧kernel trick,这里的 K K K 称为核函数kernel function。注意这样隐式得到的 H \mathcal{H} H 中数据也不一定是完美线性或近似线性可分,所以往往依赖 domain-knowledge 直接选择核函数,选择的有效性需要经过试验验证
1.2 核函数
- 通常所说的核函数是正定核函数positive definite kernel function,以下所有 “核函数” 都是指 “正定核函数”
1.2.1 两种等价定义
核函数:设 X \mathcal{X} X 是输入空间(欧式空间 R n \mathbb{R}^n Rn 或离散集合), H \mathcal{H} H 是特征空间(希尔伯特空间),若存在从 X \mathcal{X} X 到 H \mathcal{H} H 的映射 ϕ ( x ) : X → H \phi(x):\mathcal{X} \to \mathcal{H} ϕ(x):X→H 使得对 ∀ x , z ∈ X \forall x,z\in\mathcal{X} ∀x,z∈X,函数 K ( x , z ) K(x,z) K(x,z) 满足
K ( x , z ) = ϕ ( x ) ⊤ ϕ ( z ) K(\pmb{x},\pmb{z}) =\phi(\pmb{x})^{\pmb{\top}}\phi(\pmb{z}) K(xx,zz)=ϕ(xx)⊤⊤ϕ(zz) 则称 K ( x , z ) K(x,z) K(x,z) 为核函数, ϕ ( x ) \phi(x) ϕ(x) 为映射函数对于给定的核 K ( x , z ) K(x,z) K(x,z),特征空间 H \mathcal{H} H 和映射函数 ϕ \phi ϕ 的取法并不唯一,即使是同一个特征空间也可能取不同的映射,那么如何判定一个给定的 K K K 是不是核函数呢,或者说函数 K ( x , z ) K(x,z) K(x,z) 满足什么条件才能成为核函数,这里就要用到以下正定核函数的等价定义
核函数(等价定义):设 X ⊂ R n \mathcal{X}\subset \mathbb{R}^n X⊂Rn, K ( x , z ) K(x,z) K(x,z) 是定义在 X × X \mathcal{X}\times\mathcal{X} X×X 上的对称函数,如果对于任何 x i ∈ X , i = 1 , 2 , . . . , m x_i\in\mathcal{X},i=1,2,...,m xi∈X,i=1,2,...,m, K ( x , z ) K(x,z) K(x,z) 对应的Gram 矩阵
K = [ K ( x i , x j ) ] m × m K = [K(x_i,x_j)]_{m\times m} K=[K(xi,xj)]m×m 是半正定矩阵,则称 K ( x , z ) K(x,z) K(x,z) 是正定核
1.2.2 核的再生性(证明等价定义)
- 有时会听到
核的再生性、再生核希尔伯特等概念。简单说,给定一个核函数 K K K,我们就能用一定的方法构造出它对应的一组映射函数 ϕ \phi ϕ 和希尔伯特空间 H \mathcal{H} H,核 K K K 在空间 H \mathcal{H} H 中具有 “再生性”,因此这个 H \mathcal{H} H 称为 “再生核希尔伯特空间” - 上面说的构造方法,其实就是从核函数等价定义推出原始定义的过程,本节进行简单说明。假设 K ( x , z ) K(x,z) K(x,z) 是定义在 X × X \mathcal{X}\times\mathcal{X} X×X 上的对称函数,且 K ( x , z ) K(x,z) K(x,z) 关于 x i ∈ X , i = 1 , 2 , . . . , m x_i\in\mathcal{X},i=1,2,...,m xi∈X,i=1,2,...,m 的 Gram 矩阵是半正定的
- 定义映射 ϕ \phi ϕ 并构成向量空间 S \mathcal{S} S:定义映射函数为 ϕ : x → K ( ⋅ , x ) \phi: x\to K(\cdot,x) ϕ:x→K(⋅,x) 再对任意 x i ∈ X , α i ∈ R x_i\in\mathcal{X},\alpha_i\in\mathbb{R} xi∈X,αi∈R 定义线性组合 f ( ⋅ ) = ∑ i = 1 m α i K ( ⋅ , x i ) f(\cdot) = \sum_{i=1}^m\alpha_i K(\cdot,x_i) f(⋅)=i=1∑mαiK(⋅,xi) 考虑由线性组合 f ( ⋅ ) f(\cdot) f(⋅) 作为元素的集合 S \mathcal{S} S,显然它对线性运算加法和数乘封闭,因此 S \mathcal{S} S 是一个向量空间。另外这里 K ( ⋅ , x ) K(·,x) K(⋅,x) 作为一个向量可以视作函数,所以 S \mathcal{S} S 也是一个函数空间
Note:离散函数可以看做有限维向量;连续函数可以看做无限维向量
- 在 S \mathcal{S} S 上定义内积构成内积空间:在 S \mathcal{S} S 上定义内积运算 ∗ : ∀ f , g ∈ S *: \forall f,g\in\mathcal{S} ∗:∀f,g∈S, f ( ⋅ ) = ∑ i = 1 m α i K ( ⋅ , x i ) , g ( ⋅ ) = ∑ j = 1 l β i K ( ⋅ , z j ) \space f(\cdot)=\sum_{i=1}^m\alpha_iK(\cdot, x_i), \\ g(\cdot)=\sum_{j=1}^l\beta_iK(\cdot, z_j) f(⋅)=i=1∑mαiK(⋅,xi),g(⋅)=j=1∑lβiK(⋅,zj) 定义内积运算为
f ∗ g = ∑ i = 1 m ∑ j = 1 l α i β j K ( α i , β j ) f*g = \sum_{i=1}^m\sum_{j=1}^l \alpha_i\beta_j K(\alpha_i,\beta_j) f∗g=i=1∑mj=1∑lαiβjK(αi,βj) 利用 Gram 矩阵的对称性和半正定性质,易证它满足内积的四条性质
( c f ) ∗ g = c ( f ∗ g ) , c ∈ R ( f + g ) ∗ h = f ∗ h + g ∗ h , h ∈ S f ∗ g = g ∗ f f ∗ f ≥ 0 且 f ∗ f = 0 ⇔ f = 0 \begin{aligned} &(cf)*g = c(f*g), \space c\in\mathbb{R} \\ &(f+g)*h = f*h + g*h, \space h \in\mathcal{S} \\ &f*g= g*f \\ &f*f \geq 0\space且\space f*f=0 \Leftrightarrow f=0 \end{aligned} (cf)∗g=c(f∗g), c∈R(f+g)∗h=f∗h+g∗h, h∈Sf∗g=g∗ff∗f≥0 且 f∗f=0⇔f=0 这样 ∗ * ∗ 就是一个合法的内积, S \mathcal{S} S 升级为内积空间 - 将内积空间完备化构成希尔伯特空间:首先用内积如下诱导一个范数
∣ ∣ f ∣ ∣ = f ∗ f ||f|| = \sqrt{f*f} ∣∣f∣∣=f∗f 这样 S \mathcal{S} S 就是一个赋范向量空间。根据泛函分析理论,对于不完备的赋范向量空间 S \mathcal{S} S,一定可以使之完备化,从而得到完备的赋范向量空间,而 S \mathcal{S} S 本身又是内积空间,完备化后就升级为希尔伯特空间 H \mathcal{H} H - 核的再生性:根据上面内积的定义,注意到 ∀ f ( ⋅ ) = ∑ i = 1 m α i K ( ⋅ , x i ) ∈ S \forall f(\cdot)=\sum_{i=1}^m\alpha_iK(\cdot, x_i)\in\mathcal{S} ∀f(⋅)=∑i=1mαiK(⋅,xi)∈S,有
K ( ⋅ , x ) ∗ f ( ⋅ ) = K ( ⋅ , x ) ∗ ∑ i = 1 m α i K ( ⋅ , x i ) = ∑ i = 1 m α i K ( x , x i ) = f ( x ) K(\cdot,x) * f(\cdot) = K(\cdot,x)*\sum_{i=1}^m\alpha_iK(\cdot,x_i) = \sum_{i=1}^m\alpha_iK(x,x_i) = f(x) K(⋅,x)∗f(⋅)=K(⋅,x)∗i=1∑mαiK(⋅,xi)=i=1∑mαiK(x,xi)=f(x) 令 f ( ⋅ ) = K ( ⋅ , z ) f(\cdot) = K(\cdot,z) f(⋅)=K(⋅,z),有
K ( ⋅ , x ) ∗ K ( ⋅ , z ) = K ( x , z ) K(\cdot,x)* K(\cdot,z) = K(x,z) K(⋅,x)∗K(⋅,z)=K(x,z) 这个性质就称为核的再生性,具有此性质的核称为再生核,上面那样构造的希尔伯特空间 H \mathcal{H} H 称为再生核希尔伯特空间。结合映射函数 ϕ \phi ϕ 的定义,注意到
K ( x , z ) = ϕ ( x ) ∗ ϕ ( z ) K(x,z) = \phi(x)*\phi(z) K(x,z)=ϕ(x)∗ϕ(z) 因此按照上面1-3步操作,就能从给定的核函数 K K K 找出相应的一组映射函数 ϕ \phi ϕ 和希尔伯特空间 H \mathcal{H} H,从而满足核函数的原始定义
- 定义映射 ϕ \phi ϕ 并构成向量空间 S \mathcal{S} S:定义映射函数为 ϕ : x → K ( ⋅ , x ) \phi: x\to K(\cdot,x) ϕ:x→K(⋅,x) 再对任意 x i ∈ X , α i ∈ R x_i\in\mathcal{X},\alpha_i\in\mathbb{R} xi∈X,αi∈R 定义线性组合 f ( ⋅ ) = ∑ i = 1 m α i K ( ⋅ , x i ) f(\cdot) = \sum_{i=1}^m\alpha_i K(\cdot,x_i) f(⋅)=i=1∑mαiK(⋅,xi) 考虑由线性组合 f ( ⋅ ) f(\cdot) f(⋅) 作为元素的集合 S \mathcal{S} S,显然它对线性运算加法和数乘封闭,因此 S \mathcal{S} S 是一个向量空间。另外这里 K ( ⋅ , x ) K(·,x) K(⋅,x) 作为一个向量可以视作函数,所以 S \mathcal{S} S 也是一个函数空间
1.2.3 深入分析再生核希尔伯特空间
-
这一节对于给定核函数 K ( x , z ) K(x,z) K(x,z) 诱导的再生核希尔伯特空间 H \mathcal{H} H 的性质进行进一步说明
-
首先 K ( x , z ) K(x,z) K(x,z) 是一个对称的无穷维半正定矩阵,我们仅在实空间考虑, K ( x , z ) K(x,z) K(x,z) 是一个实对称矩阵。先考虑一个维度为 n × n n\times n n×n 的有限维的实对称矩阵 A A A,根据实对称矩阵性质
- A A A 一定有 n n n 个不同的特征值 λ 1 , . . . , λ n \lambda_1,...,\lambda_n λ1,...,λn,且对应的特征向量 x 1 , . . . , x n x_1,...,x_n x1,...,xn 两两正交
设 λ 1 , λ 2 \lambda_1,\lambda_2 λ1,λ2 是两个不同的特征值,对应特征向量为 x 1 , x 2 x_1,x_2 x1,x2,利用特征值与特征向量关系 A x i = λ i x i Ax_i=\lambda_i x_i Axi=λixi 以及对称性 A T = A A^T=A AT=A,有
λ 1 x 1 T x 2 = ( λ 1 x 1 ) T x 2 = ( A x 1 ) T x 2 = x 1 T A T x 2 = x 1 T A x 2 = x 1 T λ 2 x 2 = λ 2 x 1 T x 2 ⟹ x 1 T x 2 = 0 ⟹ x 1 ⊥ x 2 \begin{aligned} &\lambda_1x_1^Tx_2 = (\lambda_1x_1)^Tx_2 = (Ax_1)^Tx_2 = x_1^TA^Tx_2 = x_1^TAx_2 = x_1^T\lambda_2x_2 = \lambda_2x_1^Tx_2\\ \space \\ \Longrightarrow &\space x_1^Tx_2 = 0 \\ \Longrightarrow &\space x_1\perp x_2 \end{aligned} ⟹⟹λ1x1Tx2=(λ1x1)Tx2=(Ax1)Tx2=x1TATx2=x1TAx2=x1Tλ2x2=λ2x1Tx2 x1Tx2=0 x1⊥x2 - 这意味着 A A A 作为一个方阵可以相似对角化(充要条件: n n n 个线性无关特征向量 ⇔ \Leftrightarrow ⇔ 相似对角化)
- 这意味着 A A A 可以做特征值分解(充分条件:方阵可以相似对角化 ⇒ \Rightarrow ⇒ 方阵可以特征值分解)
A = Q D Q T = ( q 1 , q 2 , … , q n ) { λ 1 λ 2 λ 3 } { q 1 T q 2 T … q n T } = ( λ 1 q 1 , λ 2 q 2 , … , λ n q n ) { q 1 T q 2 T … q n T } = ∑ i = 1 n λ i q i q i T \begin{gathered} A=Q D Q^T=\left(q_1, q_2, \ldots, q_n\right)\left\{\begin{array}{lll} \lambda_1 & & \\ & \lambda_2 & \\ & &\lambda_3 \end{array}\right\}\left\{\begin{array}{c} q_1^T \\ q_2^T \\ \ldots \\ q_n^T \end{array}\right\} \\ =\left(\lambda_1 q_1, \lambda_2 q_2, \ldots, \lambda_n q_n\right)\left\{\begin{array}{c} q_1^T \\ q_2^T \\ \ldots \\ q_n^T \end{array}\right\} \\ =\sum_{i=1}^n \lambda_i q_i q_i^T \end{gathered} A=QDQT=(q1,q2,…,qn)⎩ ⎨ ⎧λ1λ2λ3⎭ ⎬ ⎫⎩ ⎨ ⎧q1Tq2T…qnT⎭ ⎬ ⎫=(λ1q1,λ2q2,…,λnqn)⎩ ⎨ ⎧q1Tq2T…qnT⎭ ⎬ ⎫=i=1∑nλiqiqiT Q Q Q 为单位化的特征向量 q q q 组成的正交矩阵( Q Q T = I QQ^T=I QQT=I), D = diag ( λ 1 , λ 2 , . . . , λ n ) D=\text{diag}(\lambda_1,\lambda_2,...,\lambda_n) D=diag(λ1,λ2,...,λn) 是特征值 λ \lambda λ 组成的对角阵
注意到,当一个矩阵可以特征值分解,其特征向量构成了这个 n n n 维空间的一组正交基
- A A A 一定有 n n n 个不同的特征值 λ 1 , . . . , λ n \lambda_1,...,\lambda_n λ1,...,λn,且对应的特征向量 x 1 , . . . , x n x_1,...,x_n x1,...,xn 两两正交
-
接下来把核函数看做无穷维的对称半正定矩阵,它有无穷个特征值 { λ } i = 1 ∞ \{\lambda\}_{i=1}^\infin {λ}i=1∞ 和对应的无穷个特征向量(函数) { ψ } i = 1 ∞ \{\psi\}_{i=1}^\infin {ψ}i=1∞,这时特征值和特征向量的关系为
∫ K ( x , y ) ψ ( x ) d x = λ ψ ( y ) \int K(x,y)\psi(x)dx = \lambda\psi(y) ∫K(x,y)ψ(x)dx=λψ(y) 类比上面有限维矩阵的情况,对于不同的特征值 λ 1 , λ 2 \lambda_1,\lambda_2 λ1,λ2 和对应的 ψ 1 ( x ) , ψ 2 ( x ) \psi_1(x),\psi_2(x) ψ1(x),ψ2(x),有
∫ λ 1 ψ 1 ( x ) ψ 2 ( x ) d x = ∫ λ 2 ψ 1 ( x ) ψ 2 ( x ) d x \int \lambda_1\psi_1(x)\psi_2(x)dx = \int \lambda_2\psi_1(x)\psi_2(x)dx ∫λ1ψ1(x)ψ2(x)dx=∫λ2ψ1(x)ψ2(x)dx 因此有 ⟨ ψ 1 ( x ) , ψ 2 ( x ) ⟩ = ∫ ψ 1 ( x ) ψ 2 ( x ) d x = 0 ⇒ ψ 1 ( x ) ⊥ ψ 2 ( x ) \langle\psi_1(x),\psi_2(x)\rangle = \int\psi_1(x)\psi_2(x)dx = 0\Rightarrow \psi_1(x)\perp \psi_2(x) ⟨ψ1(x),ψ2(x)⟩=∫ψ1(x)ψ2(x)dx=0⇒ψ1(x)⊥ψ2(x),类似也有
K ( x , y ) = ∑ i = 1 ∞ λ i ψ i ( x ) ψ i ( y ) K(x,y) = \sum_{i=1}^\infin \lambda_i\psi_i(x)\psi_i(y) K(x,y)=i=1∑∞λiψi(x)ψi(y) 这时单位化的 { λ i ψ i } i = 1 ∞ \{\sqrt{\lambda_i}\psi_i\}_{i=1}^\infin {λiψi}i=1∞ 成为 K K K 决定的希尔伯特空间 H \mathcal{H} H 的一组标准正交基, H \mathcal{H} H 中的任意一个函数(无穷维向量)都可以表示为线性组合
f = ∑ i = 1 ∞ α i λ i ψ i = [ α 1 , α 2 , . . . , α ∞ ] [ λ 1 ψ 1 , λ 2 ψ 2 , . . . , λ ∞ ψ ∞ ] T f = \sum_{i=1}^\infin \alpha_i\sqrt{\lambda_i}\psi_i = [\alpha_1,\alpha_2,...,\alpha_\infin][\sqrt{\lambda_1}\psi_1,\sqrt{\lambda_2}\psi_2,...,\sqrt{\lambda_\infin}\psi_\infin]^T f=i=1∑∞αiλiψi=[α1,α2,...,α∞][λ1ψ1,λ2ψ2,...,λ∞ψ∞]T 这样 K ( ⋅ , x ) K(\cdot,x) K(⋅,x) 作为无穷维矩阵中的一个无穷维向量(函数),可以表示为
K ( ⋅ , x ) = [ λ 1 ψ 1 ( x ) , λ 2 ψ 2 ( x ) , . . . , λ ∞ ψ ∞ ( x ) ] T K(\cdot,x) = [\sqrt{\lambda_1}\psi_1(x),\sqrt{\lambda_2}\psi_2(x),...,\sqrt{\lambda_\infin}\psi_\infin(x)]^T K(⋅,x)=[λ1ψ1(x),λ2ψ2(x),...,λ∞ψ∞(x)]T 同样的有
K ( ⋅ , y ) = [ λ 1 ψ 1 ( y ) , λ 2 ψ 2 ( y ) , . . . , λ ∞ ψ ∞ ( y ) ] T K(\cdot,y) = [\sqrt{\lambda_1}\psi_1(y),\sqrt{\lambda_2}\psi_2(y),...,\sqrt{\lambda_\infin}\psi_\infin(y)]^T K(⋅,y)=[λ1ψ1(y),λ2ψ2(y),...,λ∞ψ∞(y)]T 这样也能证明核的再生性
K ( x , y ) = ∑ i = 1 ∞ λ i ψ i ( x ) ψ i ( y ) = ⟨ K ( ⋅ , x ) , K ( ⋅ , y ) ⟩ K(x,y) = \sum_{i=1}^\infin \lambda_i\psi_i(x)\psi_i(y) = \langle K(\cdot,x),K(\cdot,y)\rangle K(x,y)=i=1∑∞λiψi(x)ψi(y)=⟨K(⋅,x),K(⋅,y)⟩
1.2.4 常用核函数
- 虽然核函数的等价定义对于构造核函数很有用,但对于一个具体函数 K ( x , z ) K(x,z) K(x,z) 来说,要检验它关于任意有限输入集 { x 1 , x 2 , . . . , x m } \{x_1,x_2,...,x_m\} {x1,x2,...,xm} 的 Gram 矩阵是否半正定并不容易,因此实际问题中往往直接使用已有的核函数。常用的核函数选择有

其中高斯核对应的支持向量机就是常见的高斯径向基函数(rbf)分类器,这个核函数对应的映射函数 ϕ ( x ) = ∑ i = 0 ∞ exp ( − x 2 ) 2 i i ! x i \phi(x) = \sum_{i=0}^\infin \exp(-x^2)\sqrt{\frac{2^i}{i!}}x^i ϕ(x)=i=0∑∞exp(−x2)i!2ixi 将输入空间转换为一个无穷维的特征空间,表示能力强,比较常用
2. 非线性支持向量机
- 如上所述,利用核技巧可以将线性分类的学习方法应用到非线性分类问题中,只需像 1.1.2 节那样将线性 SVM 对偶形式中的内积换成核函数就行了
- 将 经典机器学习方法(5)—— 线性支持向量机器 中 2.3.2 节介绍的线性 SVM 对偶算法使用核函数进行改进,得到非线性 SVM 学习算法如下

3. 利用 sklearn 实现支持向量机
- 本节详细介绍如何使用 sklearn 库实现线性和非线性 SVM 分类,由于本段是 jupyter 文档转换来的,代码不一定可以直接运行,有些注释是jupyter给出的交互结果,而非运行结果!!
3.1 SVC 类
-
sklearn 内置的支持向量分类器(SVC)类位于
sklearn.svm包中,相关对象还有SVR:基于libsvm实现的支持向量机,用于回归LinearSVC:可扩展线性支持向量机,基于liblinear实现,用于分类。
-
文档说明
- C-支持向量分类。
- 该实现基于libsvm。 拟合时间至少与样本数量平方成比例,不适用于万级样本数的数据集。 对于大型数据集,考虑改用
sklearn.svm.LinearSVC或sklearn.linear_model.SGDClassifier,可能需要先进行sklearn.kernel_approximation.Nystroem转换器。 - 多分类任务使用一对一方案(one-vs-one)进行处理。
- 有关提供的内核函数的精确数学公式以及
gamma,coef0和degree如何相互影响的详细信息,请参见叙述性文档中的相应部分,见svm_kernels。
-
方法原型
SVC(*, C=1.0, kernel='rbf', degree=3, gamma='scale', coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape='ovr', break_ties=False, random_state=None) -
参数表
参数 类型 默认 说明 C float 可选参数 (default=1.0) 正则化参数。正则化的强度与C成反比,必须严格为正, 惩罚是平方L2惩罚。用于防止数据集不是分离好的, C会在间距上放大误差。随着C变大,误差的惩罚也会变大,SVM会尝试寻找一个更窄的间隔,即使它错误分类了更多数据点 kernel {‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’} 可选参数 (default=‘rbf’) 指定要在算法中使用的内核类型。如果给出了可调用对象,则该可调用对象可用于从数据矩阵中pre-computed内核矩阵。 该矩阵应该是形状为 (n_samples,n_samples)的数组degree int 可选参数(default=3) 多项式内核函数(poly)的度。所有其他内核忽略此参数 gamma {‘scale’, ‘auto’} or float 可选参数 (default=‘scale’) ‘rbf’,‘poly’ 和 'Sigmoid’的内核系数。选择 scale时,gamma = 1 /(n_features * X.var())(默认);选择auto时,gamma = 1/n_featurescoef0 float 可选参数 (default=0) 内核函数中的独立项(Independent term),仅在 ‘poly’ 和 ‘sigmoid’ 中有意义 shrinking bool 可选参数 (default=True) 是否使用缩小的启发式方法(shrinking heuristic) probability bool optional (default=None) 是否启用概率估计。 必须在调用 fit之前启用此功能,因为该方法内部使用5折交叉验证(5-fold cross-validation),会降低该方法的速度,并且predict_proba可能与predict不一致tol float 可选参数 (default=1e-3) 停止标准的阈值(Tolerance) cache_size float 可选参数 (default=200) 指定内核缓存的大小(以MB为单位) class_weight dict or ‘balanced’ 可选参数 (default=None) 对于SVC,将类i的参数C设置为 class_weight[i] * C。 如果未给出,则所有类都应具有权重1。“平衡”模式使用y的值自动将权重与输入数据中的类频率成反比地调整为n_samples /(n_classes * np.bincount(y))verbose bool 可选参数 (default=False) 启用详细输出。 请注意,此设置利用了libsvm中每个进程的运行时设置,如果启用了该设置,则该设置可能无法在多线程上下文中正常工作。 max_iter int 可选参数 (default=-1) 对求解器内的迭代进行硬性限制,或者为-1(无限制) decision_function_shape {‘ovo’, ‘ovr’} 可选参数 (default=‘ovr’) 是否返回形状为 (n_samples,n_classes)的一对余 (ovr) 决策函数作为所有其他分类器,还是返回形状为(n_samples,n_classes *(n_classes-1)/ 2))的libsvm原始一对一 (ovo) 决策函数。注意:始终将“一对一(分解)”(‘ovo’)用于多分类策略。 对于二分类将忽略该参数break_ties bool 可选参数 (default=None) 如果为true,则 decision_function_shape =‘ovr’,并且类数> 2。 predict项将根据decision_function项的置信度值断开联系; 否则,将返回绑定类中的第一类。 请注意,与简单预测相比,打破联系的计算成本较高random_state int or RandomState instance 可选参数 (default=-1) 如果int,random_state是随机数生成器使用的种子;如果是随机状态实例,random_state是随机数生成器;如果为None,则随机数生成器是np.random使用的随机状态实例 -
属性表
属性 类型 说明 support_ ndarray of shape (n_SV,) 支持向量的指标(Indices) support_vectors_ ndarray of shape (n_SV, n_features) 支持向量 n_support_ ndarray of shape (n_class,), dtype=int32 每个类的支持向量数量 dual_coef_ ndarray of shape (n_class-1, n_SV) 决策函数中支持向量的对偶系数(请参阅sgd_mathematical_formulation)乘以其目标。对于多类,所有1-vs-1分类器的系数。在多类情况下,系数的布局(Layout)有些微不足道。 详细信息参见用户指南 中的 multi-class部分coef_ ndarray of shape( n_class * (n_class-1)/2,n_features) 分配给特征的权重(原始问题的系数)。 这仅在linear内核的情况下可用。注意: coef_是从dual_coef_和support_vectors_派生的只读属性intercept_ ndarray of shape (n_class * (n_class-1)/ 2,) 决策函数中的常数 classes_ ndarray of shape (n_classes,) 类标签 probA_,probB_ 都是ndarray of shape (n_class * (n_class-1) / 2) 这俩是从数据集中学到的。如果 probability = False,则为空数组;如果probability = True,则它对应于在Platt scaling中学到的参数,用于根据决策值(decision values)产生概率估计(probability estimates)。 Platt scaling使用逻辑函数 1 ( 1 + exp ( d e c i s i o n _ v a l u e × p r o b A + p r o b B ) \frac{1}{(1 + \exp(decision\_value\times probA+ probB)} (1+exp(decision_value×probA+probB)1class_weight_ ndarray of shape (n_class,) 每个类的参数C的乘数。根据 class_weight参数进行计算shape_fit_ tuple of int of shape (n_dimensions_of_X,) 训练向量 X的数组尺寸
3.2 线性 SVM 分类器
3.2.1 处理线性可分数据
- 通过在构造 SVC 对象时设置
kernel = "linear"来构造线性 SVM 分类器,使用.fit(X,y)方法拟合from sklearn.datasets import make_blobs from sklearn.svm import SVC import matplotlib.pyplot as plt import numpy as np def plot_svc_decision_function(model,ax=None): if ax is None: ax = plt.gca() # 等高线方法 contour 可以利用有限的具有高度信息的关键点拟合整个空间的高度信息 # 为了借助等高线绘制分离超平面和分隔边界,把样本到决策边界的距离作为高度,使用模型对特征空间中的给定网格点计算“高度” 作为contour输入 # 这里绘制的是线性边界,更多的网格点不会带来更高的精度,最少仅使用分布均匀的四个点即可以绘制同样的决策边界,但对于非线性边界,显然网格数目会影响绘制精度, # 构造网格点 xlim = ax.get_xlim() ylim = ax.get_ylim() x = np.linspace(xlim[0],xlim[1],30) y = np.linspace(ylim[0],ylim[1],30) Y,X = np.meshgrid(y,x) xy = np.vstack([X.ravel(), Y.ravel()]).T print(xy.shape) # 计算网格点高度信息 Z = model.decision_function(xy).reshape(X.shape) # 借助等高线方法绘制分离超平面和分隔边界 ax.contour(X, Y, Z,colors="k",levels=[-1,0,1],alpha=0.5,linestyles=["--","-","--"]) ax.set_xlim(xlim) ax.set_ylim(ylim) # 绘制网格点 #plt.scatter(xy[:,0],xy[:,1],s=1,cmap="rainbow") # 创建数据集 X,y = make_blobs(n_samples=50, # 数据点数 centers=2, # 簇数 #random_state=0, # 随机数种子 cluster_std=0.6) # 簇标准差 # 训练线性 SVM 分类器 clf = SVC(kernel = "linear").fit(X,y) # 绘制分类面 plt.scatter(X[:,0],X[:,1],c=y,s=50,cmap="rainbow") plot_svc_decision_function(clf)

3.2.2 处理非线性数据
- 如果数据是非线性可分的,使用线性 SVM 分类器效果不佳
from sklearn.datasets import make_circles from sklearn.svm import SVC import matplotlib.pyplot as plt import numpy as np # 使用n*n网格点绘制等高线 def plot_svc_decision_function_by_grid(model,ax): if ax is None: ax = plt.gca() xlim = ax.get_xlim() ylim = ax.get_ylim() x = np.linspace(xlim[0],xlim[1],30) # (30,) y = np.linspace(ylim[0],ylim[1],30) # (30,) Y,X = np.meshgrid(y,x) # (30,30) (30,30) xy = np.vstack([X.ravel(), Y.ravel()]).T # (900,2) Z = model.decision_function(xy).reshape(X.shape) # (30,30) CS = ax.contour(X, Y, Z,colors="k",levels=[-1,0,1],alpha=0.5,linestyles=["--","-","--"]) # 三条等高线 #CS = ax.contour(X, Y, Z,alpha=0.5) ax.clabel(CS, inline=1, fontsize=10) ax.set_xlim(xlim) # x轴坐标 ax.set_ylim(ylim) # y轴坐标 #ax.scatter(xy[:,0],xy[:,1],s=1,cmap="rainbow") # 网格点 # 数据集 X,y = make_circles(n_samples=1000, noise=0.1, factor=0.2,) # 分类器 clf = SVC(kernel = "linear").fit(X,y) # 绘制数据集点 fig = plt.figure(figsize=(6,6)) ax = plt.gca() ax.scatter(X[:,0],X[:,1],c=y,s=50,alpha=0.3,cmap="rainbow") # 绘制决策边界和超平面 plot_svc_decision_function_by_grid(clf,ax) print('训练集性能:',clf.score(X,y)) # 训练集性能: 0.69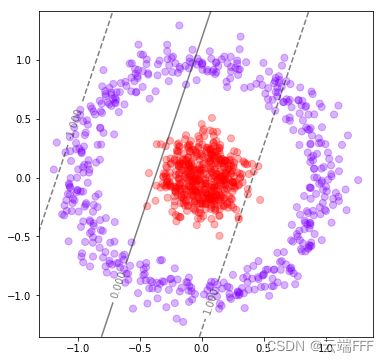
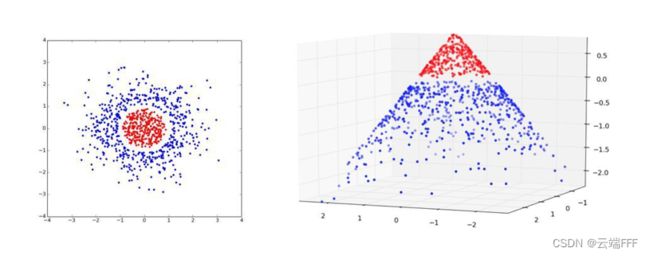
- 这时可以根据 x 轴特征新计算了一个特征,作为新加入的第三维度,从而把数据投影到三维空间中。令 x 值越靠近 0 时新特征值越大,这样就能在高位空间中用一个平面将两类数据隔开,使数据集再次线性可分
from sklearn.datasets import make_circles from sklearn.svm import SVC import matplotlib.pyplot as plt import numpy as np # 数据集 X,y = make_circles(n_samples=500, noise=0.1, factor=0.3) # 绘制数据集点 fig = plt.figure(figsize=(12,6)) a0 = fig.add_subplot(1,2,1,label='a0') a0.scatter(X[:,0],X[:,1],c=y,s=50,alpha=0.3,cmap="rainbow") # 增加一个维度,由原先的第0维计算得到,把此维度并入特征数组X r = np.exp(-(X**2).sum(1)) r = r.reshape(r.size,1) X = np.hstack((X,r)) # 绘制升维后的数据集点 a1 = fig.add_subplot(1,2,2,label='a1',projection='3d') a1.scatter(X[:,0],X[:,1],X[:,2],c=y,s=50,alpha=0.3,cmap="rainbow") # 分类器 clf = SVC(kernel = "linear").fit(X,y) print('训练集性能:',clf.score(X,y)) # 训练集性能: 0.998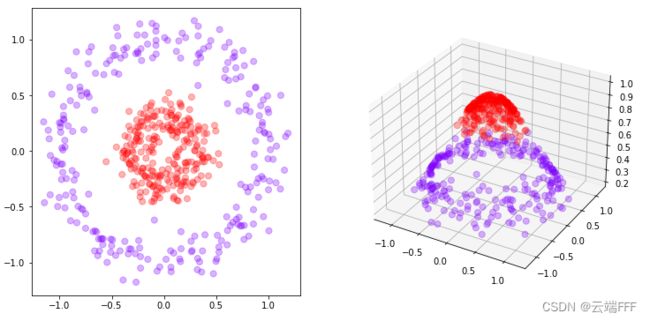
这里做的数据升维的过程就是一种 “核变换”,将数据从二维输入空间映射到投影到高维特征空间中,以寻找能够将让数据线性可分的高维空间和超平面
3.3 非线性 SVM 分类器
3.3.1 SVC在非线性数据上的推广
- 为了找出非线性数据的决策边界,需要把数据从输入空间投影到高维空间中,使其在高维空间中线性可分
- Φ \Phi Φ 是一个映射函数,代表了对数据空间某种非线性变换。假设 Φ \Phi Φ 可以把升维数据使其线性可分,则这种非线性SVM分类器的决策边界的推导过程和线性可分SVM一致,仅需把 x x x 转换为 Φ ( x ) \Phi(x) Φ(x) 即可
- 原始决策边界 f ( x t e s t ) = s i g n ( w ⋅ x t e s t + b ) = s i g n ( ∑ i = 1 N α i y i x i ⋅ x t e s t + b ) f(\pmb{x_{test}}) = sign(\pmb{w}\cdot\pmb{x_{test}}+b) = sign(\sum_{i=1}^N\alpha_i y_i \pmb{x_i}\cdot\pmb{x_{test}}+b) f(xtestxtest)=sign(ww⋅xtestxtest+b)=sign(∑i=1Nαiyixixi⋅xtestxtest+b)
- 升维决策边界 f ( x t e s t ) = s i g n ( w ⋅ Φ ( x t e s t ) + b ) = s i g n ( ∑ i = 1 N α i y i Φ ( x i ) ⋅ Φ ( x t e s t ) + b ) f(\pmb{x_{test}}) = sign(\pmb{w}\cdot\Phi(\pmb{x_{test}})+b) = sign(\sum_{i=1}^N\alpha_i y_i \Phi(\pmb{x_i})\cdot\Phi(\pmb{x_{test}})+b) f(xtestxtest)=sign(ww⋅Φ(xtestxtest)+b)=sign(∑i=1NαiyiΦ(xixi)⋅Φ(xtestxtest)+b)
- 这种变换巧妙而有效,但是也有一些问题。
- 可能不清楚应该对各类数据使用什么类型的映射函数 Φ \Phi Φ,以确保高维空间中的数据投影线性可分
- 映射后的空间也可能维度过高,导致冗余的推导和计算。极端情况下,数据可能被映射到无限维空间中
- 即使已知适当的映射函数, Φ ( x i ) ⋅ Φ ( x t e s t ) \Phi(\pmb{x_i})\cdot\Phi(\pmb{x_{test}}) Φ(xixi)⋅Φ(xtestxtest) 这样的点积计算量也非常大
3.3.2 sklearn 中的核函数
-
sklearn 中,通过在构造 SVC 对象时设置
kernel参数确定使用的核函数

- 可见,除了
linear以外的其他核函数都能处理非线性情况。 poly核有次数参数d,d=1时可以处理线性问题,d更大时可以处理非线性问题。- 3.3.2节中的升维方法其实就是应用了
rbf核
- 可见,除了
-
使用
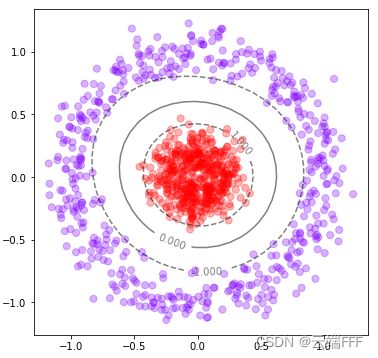
rbf核找圆形数据集的决策边界from sklearn.datasets import make_circles from sklearn.svm import SVC import matplotlib.pyplot as plt import numpy as np # 使用n*n网格点绘制等高线 def plot_svc_decision_function_by_grid(model,ax): if ax is None: ax = plt.gca() xlim = ax.get_xlim() ylim = ax.get_ylim() x = np.linspace(xlim[0],xlim[1],30) # (30,) y = np.linspace(ylim[0],ylim[1],30) # (30,) Y,X = np.meshgrid(y,x) # (30,30) (30,30) xy = np.vstack([X.ravel(), Y.ravel()]).T # (900,2) Z = model.decision_function(xy).reshape(X.shape) # (30,30) CS = ax.contour(X, Y, Z,colors="k",levels=[-1,0,1],alpha=0.5,linestyles=["--","-","--"]) # 三条等高线 #CS = ax.contour(X, Y, Z,alpha=0.5) ax.clabel(CS, inline=1, fontsize=10) ax.set_xlim(xlim) # x轴坐标 ax.set_ylim(ylim) # y轴坐标 #ax.scatter(xy[:,0],xy[:,1],s=1,cmap="rainbow") # 网格点 # 数据集 X,y = make_circles(n_samples=1000, noise=0.1, factor=0.2,) # 分类器 clf = SVC(kernel = "rbf").fit(X,y) # 绘制数据集点 fig = plt.figure(figsize=(6,6)) ax = plt.gca() ax.scatter(X[:,0],X[:,1],c=y,s=50,alpha=0.3,cmap="rainbow") # 绘制决策边界和超平面 plot_svc_decision_function_by_grid(clf,ax) print('训练集性能:',clf.score(X,y)) # 训练集性能: 1.0
3.3.3 对比不同的核函数
- 对比不同核函数在不同分布数据集上的性能
import numpy as np import matplotlib.pyplot as plt from matplotlib.colors import ListedColormap from sklearn.svm import SVC from sklearn.datasets import make_circles, make_moons, make_blobs,make_classification # 准备不同类型的数据集 n_samples = 100 datasets = [make_moons(n_samples=n_samples, noise=0.2, random_state=0), make_circles(n_samples=n_samples, noise=0.2, factor=0.5, random_state=1), make_blobs(n_samples=n_samples, centers=2, random_state=5), make_classification(n_samples=n_samples,n_features = 2,n_informative=2,n_redundant=0, random_state=5)] # 四种核函数 Kernel = ["linear","poly","rbf","sigmoid"] # 创建子图,4数据集*(1原始图+4种核函数) nrows=len(datasets) ncols=len(Kernel) + 1 fig, axes = plt.subplots(nrows, ncols,figsize=(20,16)) # 内置函数enumerate把一个可迭代的(iterable)/可遍历的对象(如列表、字符串)组成一个索引序列,利用它可以同时获得索引和值 # 数据集循环 for ds_cnt,(X,Y) in enumerate(datasets): # 图像第一列显示原始数据分布 ax = axes[ds_cnt, 0] if ds_cnt == 0: ax.set_title("Input data") ax.scatter(X[:, 0], X[:, 1], c=Y, cmap=plt.cm.Paired,edgecolors='k') # edgecolors参数给散点图的点描边 ax.set_xticks(()) # 坐标轴显示空 ax.set_yticks(()) # 坐标轴显示空 # 核函数循环 for est_idx, kernel in enumerate(Kernel): # 定义子图位置,第i个核对应第(i+1)列子图 ax = axes[ds_cnt, est_idx + 1] # 训练分类器 clf = SVC(kernel=kernel, gamma=2).fit(X, Y) score = clf.score(X, Y) # 训练集上的分类精度 # 绘制图像本身分布的散点图 ax.scatter(X[:, 0], X[:, 1], c=Y, zorder=10, cmap=plt.cm.Paired, edgecolors='k') # 圈出支持向量,即在支持向量处画一个圈 ax.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1], s=300, # 尺寸较大 facecolors='none', # 无填充颜色 zorder=10, # zorder越大,图层越靠上 edgecolors='k') # 建立网格 x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5 y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5 # np.mgrid,合并了np.linspace和np.meshgrid的用法,一次性使用最大值和最小值来生成网格 # 参数表示为[起始值:结束值:步长] # 如果步长是复数(j结尾),则其整数部分就是起始值和结束值之间创建的点的数量,并且结束值被包含在内(即左闭右闭区间) XX, YY = np.mgrid[x_min:x_max:200j, y_min:y_max:200j] # np.c_,类似于np.vstack的功能 Z = clf.decision_function(np.c_[XX.ravel(), YY.ravel()]).reshape(XX.shape) # 填充等高线不同区域的颜色 ax.pcolormesh(XX, YY, Z > 0, shading='auto',zorder=5,cmap=plt.cm.Paired) # 绘制等高线 ax.contour(XX, YY, Z, colors=['k', 'k', 'k'], zorder=7,linestyles=['--', '-', '--'],levels=[-1, 0, 1]) # 设定坐标轴为不显示 ax.set_xticks(()) ax.set_yticks(()) # 将标题放在第一行的顶上 if ds_cnt == 0: ax.set_title(kernel) # 为每张图添加分类的分数 ax.text(0.95, 0.06, # 文字位置 ('%.2f' % score).lstrip('0'), # 精度 size=15, zorder=7, bbox=dict(boxstyle='round', alpha=0.8, facecolor='white'), # 添加一个白色的格子作为底色 transform=ax.transAxes, # 确定文字所对应的坐标轴,就是ax子图的坐标轴本身 horizontalalignment='right') #位于坐标轴的什么方向 plt.tight_layout() plt.show()
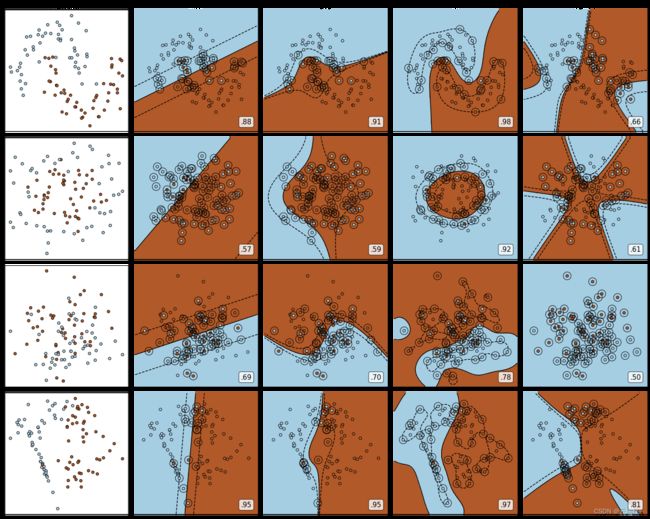
- 可以观察到
linear核函数和poly核函数在非线性数据上表现会浮动,如果数据相对线性可分,即便有扰动项,表现也不错;如果是像环形数据那样彻底不可分的,则表现糟糕。poly核函数虽然也可以处理非线性情况,但更偏向于线性的功能。sigmoid核函数就比较尴尬了,它在非线性数据上强于两个线性核函数,但效果明显不如rbf,它在线性数据上完全比不上线性的核函数们,对扰动项的抵抗也比较弱,所以它功能比较弱小,很少被用到。rbf核函数基本在任何数据集上都表现不错,属于比较万能的核函数。
- 个人经验是
- 无论如何先试试看
rbf核函数,它适用于核转换到很高的空间的情况,在各种情况下往往效果都很不错,如果rbf效果不好,那我们再试试看其他的核函数。 - 多项式核函数多被用于图像处理之中
- 无论如何先试试看