推荐系统实践读书笔记-01好的推荐系统
推荐系统实践读书笔记-01好的推荐系统
在研究如何设计推荐系统前,了解什么是好的推荐系统至关重要。只有了解了优秀推荐系统的特征,我们才能在设计推荐系统时根据实际情况进行取舍。本章分3个步骤来回答这个问题:首先,本章将介绍什么是推荐系统、推荐系统的主要任务、推荐系统和分类目录以及搜索引擎的区别等;然后,本章将按照不同领域分门别类地介绍目前业界常见的个性化推荐应用;最后,本章将介绍推荐系统的评测,通过介绍评测指标给出“好”的定义,从而最终解答“什么是好的推荐系统”这个问题。
提示:本系列文章为阅读《推荐系统实践》一书的读书笔记,只用于本人学习记录
文章目录
- 推荐系统实践读书笔记-01好的推荐系统
-
- 1.1 什么是推荐系统
- 1.2 个性化推荐系统的应用
-
- 1.2.1 电子商务
- 1.2.2 电影和视频网站
- 1.2.3 个性化音乐网络电台
- 1.2.4 社交网络
- 1.2.5 个性化阅读
- 1.2.6 基于位置的服务
- 1.2.7 个性化邮件
- 1.2.8 个性化广告
- 1.3 推荐系统评测
-
- 1.3.1 推荐系统实验方法
- 1.3.2 评测指标
- 1.3.3 评测维度
1.1 什么是推荐系统
如果想买一包花生米,你有多少种办法?假设附近有一个24小时便利店,你可以走进店里,看看所有的货架,转一圈找到花生米,然后比较几个牌子的口碑或者价格找到自己喜欢的牌子,掏钱付款。如果家附近有一家沃尔玛,你可以走进店里,按照分类指示牌走到食品所在的楼层,接着按照指示牌找到卖干果的货架,然后在货架上仔细寻找你需要的花生米,找到后付款。如果你很懒,不想出门,可以打开当当或者淘宝,在一个叫做搜索框的东西里输入花生米3个字,然后你会看到一堆花生米,找到喜欢的牌子,付费,然后等待送货上门。上面这几个例子描述了用户在有明确需求的情况下,面对信息过载所采用的措施。在24小时便利店,因为店面很小,用户可以凭自己的经验浏览所有货架找到自己需要的东西。在沃尔玛,商品已经被放在无数的货架上,此时用户就需要借用分类信息找到自己需要的商品。而在淘宝或者当当,由于商品数目巨大,用户只能通过搜索引擎找到自己需要的商品。
但是,如果用户没有明确的需求呢?比如你今天很无聊,想下载一部电影看看。但当你打开某个下载网站,面对100年来发行的数不胜数的电影,你会手足无措,不知道该看哪一部。此时,你遇到了信息过载的问题,需要一个人或者工具来帮助你做筛选,给出一些建议供你选择。如果这时候有个喜欢看电影的朋友在身边,你可能会请他推荐几部电影。不过,总不能时时刻刻都去麻烦“专家”给你推荐,你需要的是一个自动化的工具,它可以分析你的历史兴趣,从庞大的电影库中找到几部符合你兴趣的电影供你选择。这个工具就是个性化推荐系统。
随着信息技术和互联网的发展,人们逐渐从信息匮乏的时代走入了信息过载(information overload)的时代。在这个时代,无论是信息消费者还是信息生产者都遇到了很大的挑战:作为信息消费者,如何从大量信息中找到自己感兴趣的信息是一件非常困难的事情;作为信息生产者,如何让自己生产的信息脱颖而出,受到广大用户的关注,也是一件非常困难的事情。推荐系统就是解决这一矛盾的重要工具。推荐系统的任务就是联系用户和信息,一方面帮助用户发现对自己有价值的信息,另一方面让信息能够展现在对它感兴趣的用户面前,从而实现信息消费者和信息生产者的双赢(如图1-1所示)。(本书后面将信息统称为“物品”,即可以供用户消费的东西。)

众所周知,为了解决信息过载的问题,已经有无数科学家和工程师提出了很多天才的解决方案,其中代表性的解决方案是分类目录和搜索引擎。而这两种解决方案分别催生了互联网领域的两家著名公司——雅虎和谷歌。著名的互联网公司雅虎凭借分类目录起家,而现在比较著名的分类目录网站还有国外的DMOZ、国内的Hao123等。这些目录将著名的网站分门别类,从而方便用户根据类别查找网站。但是随着互联网规模的不断扩大,分类目录网站也只能覆盖少量的热门网站,越来越不能满足用户的需求。因此,搜索引擎诞生了。以谷歌为代表的搜索引擎可以让用户通过搜索关键词找到自己需要的信息。但是,搜索引擎需要用户主动提供准确的关键词来寻找信息,因此不能解决用户的很多其他需求,比如当用户无法找到准确描述自己需求的关键词时,搜索引擎就无能为力了。和搜索引擎一样,推荐系统也是一种帮助用户快速发现有用信息的工具。和搜索引擎不同的是,推荐系统不需要用户提供明确的需求,而是通过分析用户的历史行为给用户的兴趣建模,从而主动给用户推荐能够满足他们兴趣和需求的信息。因此,从某种意义上说,推荐系统和搜索引擎对于用户来说是两个互补的工具。搜索引擎满足了用户有明确目的时的主动查找需求,而推荐系统能够在用户没有明确目的的时候帮助他们发现感兴趣的新内容。
从物品的角度出发,推荐系统可以更好地发掘物品的长尾(long tail)。美国《连线》杂志主编Chris Anderson在2004年发表了“The Long Tail”(长尾)一文并于2006年出版了《长尾理论》一书。该书指出,传统的80/20原则(80%的销售额来自于20%的热门品牌)在互联网的加入下会受到挑战。互联网条件下,由于货架成本极端低廉,电子商务网站往往能出售比传统零售店更多的商品。虽然这些商品绝大多数都不热门,但与传统零售业相比,这些不热门的商品数量极其庞大,因此这些长尾商品的总销售额将是一个不可小觑的数字,也许会超过热门商品(即主流商品)带来的销售额。主流商品往往代表了绝大多数用户的需求,而长尾商品往往代表了一小部分用户的个性化需求。因此,如果要通过发掘长尾提高销售额,就必须充分研究用户的兴趣,而这正是个性化推荐系统主要解决的问题。推荐系统通过发掘用户的行为,找到用户的个性化需求,从而 将长尾商品准确地推荐给需要它的用户,帮助用户发现那些他们感兴趣但很难发现的商品。
要了解推荐系统是如何工作的,可以先回顾一下现实社会中用户面对很多选择时做决定的过程。仍然以看电影为例,一般来说,我们可能用如下方式决定最终看什么电影。
向朋友咨询。我们也许会打开聊天工具,找几个经常看电影的好朋友,问问他们有没有什么电影可以推荐。甚至,我们可以打开微博,发表一句“我要看电影”,然后等待热心人推荐电影。这种方式在推荐系统中称为社会化推荐(social recommendation),即让好友给自己推荐物品。
我们一般都有喜欢的演员和导演,有些人可能会打开搜索引擎,输入自己喜欢的演员名,然后看看返回结果中还有什么电影是自己没有看过的。比如我非常喜欢周星驰的电影,于是就去豆瓣搜索周星驰,发现他早年的一部电影我还没看过,于是就会看一看。这种方式是寻找和自己之前看过的电影在内容上相似的电影。推荐系统可以将上述过程自动化,通过分析用户曾经看过的电影找到用户喜欢的演员和导演,然后给用户推荐这些演员或者导演的其他电影。这种推荐方式在推荐系统中称为基于内容的推荐(content-based filtering)。
我们还可能查看排行榜,比如著名的IMDB电影排行榜,看看别人都在看什么电影,别人都喜欢什么电影,然后找一部广受好评的电影观看。这种方式可以进一步扩展:如果能找到和自己历史兴趣相似的一群用户,看看他们最近在看什么电影,那么结果可能比宽泛的热门排行榜更能符合自己的兴趣。这种方式称为基于协同过滤(collaborative filtering)的推荐。
从上面3种方法可以看出,推荐算法的本质是通过一定的方式将用户和物品联系起来,而不同的推荐系统利用了不同的方式。图1-2展示了联系用户和物品的常用方式,比如利用好友、用户的历史兴趣记录以及用户的注册信息等。
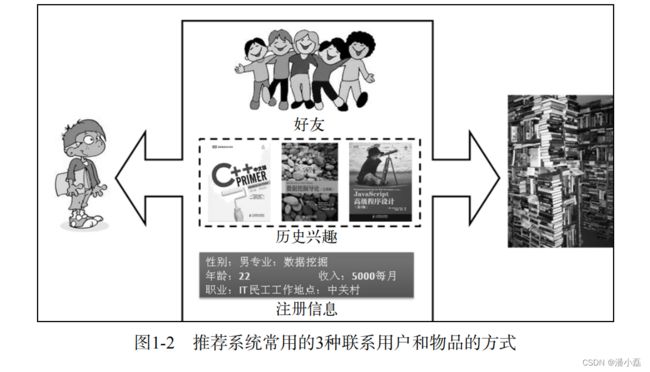
通过这一节的讨论,我们可以发现推荐系统就是自动联系用户和物品的一种工具,它能够在信息过载的环境中帮助用户发现令他们感兴趣的信息,也能将信息推送给对它们感兴趣的用户。下一节将通过推荐系统的实际例子让大家加深对推荐系统的了解。
1.2 个性化推荐系统的应用
和搜索引擎不同,个性化推荐系统需要依赖用户的行为数据,因此一般都是作为一个应用存在于不同网站之中。在互联网的各类网站中都可以看到推荐系统的应用,而个性化推荐系统在这些网站中的主要作用是通过分析大量用户行为日志,给不同用户提供不同的个性化页面展示,来提高网站的点击率和转化率。广泛利用推荐系统的领域包括电子商务、电影和视频、音乐、社交网络、阅读、基于位置的服务、个性化邮件和广告等。
尽管不同的网站使用不同的推荐系统技术,但总地来说,几乎所有的推荐系统应用都是由前台的展示页面、后台的日志系统以及推荐算法系统3部分构成的。因此,本节在介绍不同的个性化推荐系统应用时,都尽量围绕这3个不同的部分进行。
1.2.1 电子商务
电子商务网站是个性化推荐系统的一大应用领域。著名的电子商务网站亚马逊是个性化推荐系统的积极应用者和推广者,被RWW(读写网)称为“推荐系统之王”。亚马逊的推荐系统深入到了其各类产品中,其中最主要的应用有个性化商品推荐列表和相关商品的推荐列表。
图1-3是亚马逊的个性化推荐列表,这个界面是个性化推荐系统的标准用户界面,它包含以下几个组成部分。

推荐结果的标题、缩略图以及其他内容属性 告诉用户给他们推荐的是什么。
推荐结果的平均分 平均分反应了推荐结果的总体质量,也代表了大部分用户对这本书的看法。
推荐理由 亚马逊根据用户的历史行为给用户做推荐,因此如果它给你推荐了一本金庸的小说,大都是因为你曾经在亚马逊上对武侠方面的书给过表示喜欢的反馈。此外,亚马逊对每个推荐结果都给出了一个按钮Fix this recommendation(修正这一推荐),单击后可以看到推荐理由。如图1-4所示,亚马逊的推荐结果中有一本关于机器学习的书(Introduction to Machine Learning),单击该推荐结果的Fix this recommendaion按钮后,会弹出如图1-4所示的页面,该页面给用户提供了5种对这个推荐结果进行反馈的方式,包括Add to Cart(加入到购物车)、Add to Wish List(加入到心愿单)、Rate this item(给书打分)、 I own it(我已经有这本书了)和Not interested(对这本书没兴趣)。同时,在推荐结果的下面还展示了推荐原因,此处是因为我曾经给Probabilistic Graphical Models:Principles and Techniques和Data Mining:Practical Machine Learning Tools and Techniques,Second Edition这两本书打过5分。亚马逊允许用户禁用推荐理由,这主要是出于隐私的考虑。有些用户可能不喜欢他对某些物品的行为被系统用来生成推荐结果,这个时候就可以禁用这些行为。
图1-3提到的个性化推荐列表采用了一种基于物品的推荐算法(item-based method),该算法给用户推荐那些和他们之前喜欢的物品相似的物品。除此之外,亚马逊还有另外一种个性化推荐列表,就是按照用户在Facebook的好友关系,给用户推荐他们的好友在亚马逊上喜欢的物品。如图1-5所示,基于好友的个性化推荐界面同样由物品标题、缩略图、物品平均分和推荐理由组成。不过这里的推荐理由换成了喜欢过相关物品的用户好友的头像。
除了个性化推荐列表,亚马逊另一个重要的推荐应用就是相关推荐列表。当你在亚马逊购买一个商品时,它会在商品信息下面展示相关的商品。亚马逊有两种相关商品列表,一种是包含购买了这个商品的用户也经常购买的其他商品(如图1-6所示),另一种是包含浏览过这个商品的用户经常购买的其他商品(如图1-7所示)。这两种相关推荐列表的区别就是使用了不同用户行为计算物品的相关性。此外,相关推荐列表最重要的应用就是打包销售(cross selling)①。当你在购买某个物品的时候,亚马逊会告诉你其他用户在购买这个商品的同时也会购买的其他几个商品,然后让你选择是否要同时购买这些商品。如果你单击了同时购买,它会把这几件商品“打包”,有时会提供一定的折扣,然后卖给你(如图1-8所示)。这种销售手段是推荐算法最重要的应用,后来被很多电子商务网站作为标准的应用。

在看过亚马逊的推荐产品后,读者最关心的应该是这些推荐的应用,究竟给亚马逊带来了多少商业利益。关于这方面的准确数字,亚马逊官方并没有明确公开过,但我们收集到了一些相关的资料。亚马逊的前科学家Greg Linden在他的博客里曾经说过,在他离开亚马逊的时候,亚马逊至少有20%(之后的一篇博文则变更为35%)的销售来自于推荐算法。此外,亚马逊的前首席科学家Andreas Weigend在斯坦福曾经讲过一次推荐系统的课,据听他课的同学透露,亚马逊有20%~30%的销售来自于推荐系统。

至于个性化推荐系统对亚马逊的意义,其CEO Jeff Bezos在接受采访时曾经说过,亚马逊相对于其他电子商务网站的最大优势就在于个性化推荐系统,该系统让每个用户都能拥有一个自己的在线商店,并且能在商店中找到自己感兴趣的商品。
1.2.2 电影和视频网站
在电影和视频网站中,个性化推荐系统也是一种重要的应用。它能够帮助用户在浩瀚的视频库中找到令他们感兴趣的视频。在该领域成功使用推荐系统的一家公司就是Netflix,它和亚马逊是推荐系统领域最具代表性的两家公司。
Netflix原先是一家DVD租赁网站,最近这几年也开始涉足在线视频业务。Netflix非常重视个性化推荐技术,并且在2006年起开始举办著名的Netflix Prize推荐系统比赛。该比赛悬赏100万美元,希望研究人员能够将Netflix的推荐算法的预测准确度提升10%。该比赛举办3年后,由AT&T的研究人员获得了最终的大奖。该比赛对推荐系统的发展起到了重要的推动作用:一方面该比赛给学术界提供了一个实际系统中的大规模用户行为数据集(40万用户对2万部电影的上亿条评分记录);另一方面,3年的比赛中,参赛者提出了很多推荐算法,大大降低了推荐系统的预测误差。此外,比赛吸引了很多优秀的科研人员加入到推荐系统的研究中来,大大提高了推荐系统在业界和学术界的影响力。
图1-9是Netflix的电影推荐界面,从中可以看到Netflix的推荐结果展示页面包含了以下几个部分
电影的标题和海报。
用户反馈模块——包括Play(播放)、评分和Not Interested(不感兴趣)3种。
推荐理由——因为用户曾经喜欢过别的电影。

从Netflix的推荐理由来看,它们的算法和亚马逊的算法类似,也是基于物品的推荐算法,即给用户推荐和他们曾经喜欢的电影相似的电影。至于推荐系统在Netflix中起到的作用,Netflix在宣传资料中宣称,有60%的用户是通过其推荐系统找到自己感兴趣的电影和视频的。
YouTube作为美国最大的视频网站,拥有大量用户上传的视频内容。由于视频库非常大,用户在YouTube中面临着严重的信息过载问题。为此,YouTube在个性化推荐领域也进行了深入研究,尝试了很多算法。在YouTube最新的论文中,他们的研究人员表示现在使用的也是基于物品的推荐算法。为了证明个性化推荐的有效性,YouTube曾经做个一个实验,比较了个性化推荐的点击率和热门视频列表的点击率,实验结果表明个性化推荐的点击率是热门视频点击率的两倍。
和YouTube类似,美国另一家著名的视频网站Hulu也有自己的个性化推荐页面。如图1-10所示,Hulu在展示推荐结果时也提供了视频标题、缩略图、视频的平均分、推荐理由和用户反馈模块。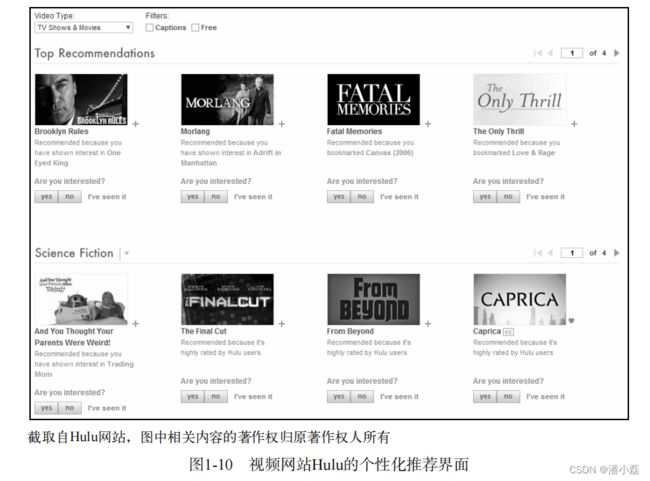
1.2.3 个性化音乐网络电台
个性化推荐的成功应用需要两个条件。第一是存在信息过载,因为如果用户可以很容易地从所有物品中找到喜欢的物品,就不需要个性化推荐了。第二是用户大部分时候没有特别明确的需求,因为用户如果有明确的需求,可以直接通过搜索引擎找到感兴趣的物品。
在这两个条件下,个性化网络电台无疑是最合适的个性化推荐产品。首先,音乐很多,用户不可能听完所有的音乐再决定自己喜欢听什么,而且每年新的歌曲在以很快的速度增加,因此用户无疑面临着信息过载的问题。其次,人们听音乐时,一般都是把音乐作为一种背景乐来听,很少有人必须听某首特定的歌。对于普通用户来说,听什么歌都可以,只要能够符合他们当时的心情就可以了。因此,个性化音乐网络电台是非常符合个性化推荐技术的产品。
目前有很多知名的个性化音乐网络电台。国际上著名的有Pandora(参见图1-11)和Last.fm(参见图1-12),国内的代表则是豆瓣电台(参见图1-13)。这3种应用虽然都是个性化网络电台,但背后的技术却不太一样。
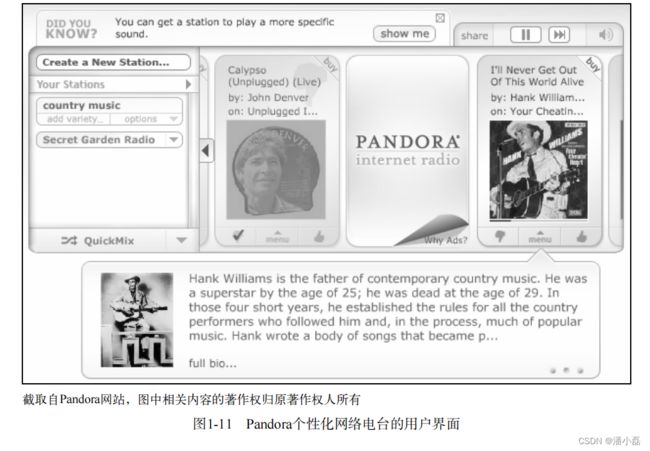
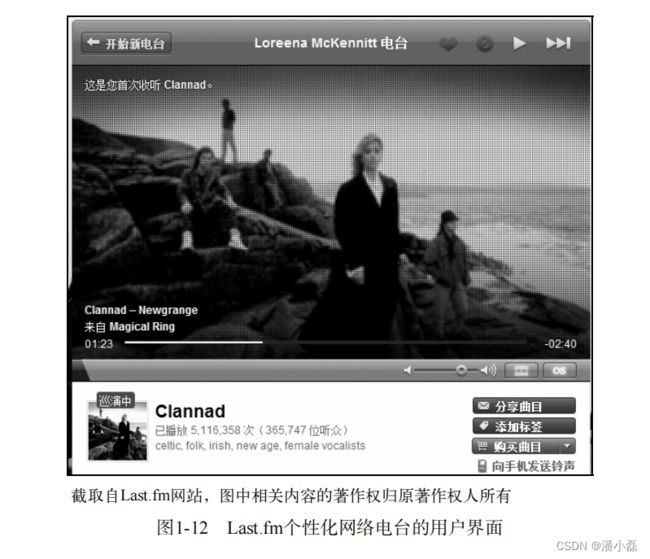
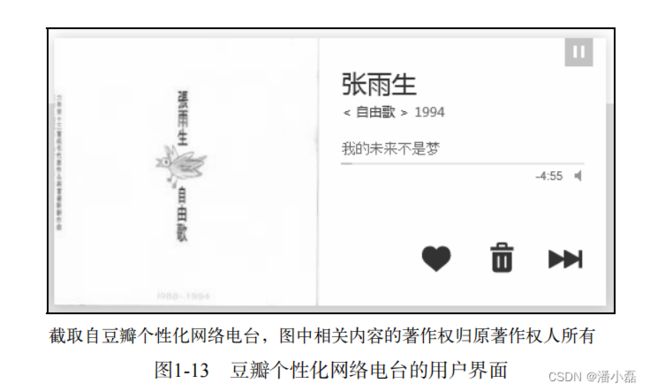
从前端界面上看,这3个个性化网络电台很类似。它们都不允许用户点歌,而是给用户几种反馈方式——喜欢、不喜欢和跳过。经过用户一定时间的反馈,电台就可以从用户的历史行为中习得用户的兴趣模型,从而使用户的播放列表越来越符合用户对歌曲的兴趣。
Pandora背后的音乐推荐算法主要来自于一个叫做音乐基因工程的项目。这个项目起始于2000年1月6日,它的成员包括音乐家和对音乐有兴趣的工程师。Pandora的算法主要基于内容,其音乐家和研究人员亲自听了上万首来自不同歌手的歌,然后对歌曲的不同特性(比如旋律、节奏、编曲和歌词等)进行标注,这些标注被称为音乐的基因。然后,Pandora会根据专家标注的基因计算歌曲的相似度,并给用户推荐和他之前喜欢的音乐在基因上相似的其他音乐。
Last.fm于2002年在英国成立。Last.fm记录了所有用户的听歌记录以及用户对歌曲的反馈,在这一基础上计算出不同用户在歌曲上的喜好相似度,从而给用户推荐和他有相似听歌爱好的其他用户喜欢的歌曲。同时,Last.fm也建立了一个社交网络,让用户能够和其他用户建立联系,同时也能让用户给好友推荐自己喜欢的歌曲。和Pandora相比,Last.fm没有使用专家标注,而是主要利用用户行为计算歌曲的相似度。
音乐推荐是推荐系统里非常特殊的领域。2011年的Recsys大会专门邀请了Pandora的研究人员对音乐推荐进行了演讲。演讲人总结了音乐推荐的如下特点。
物品空间大 物品数很多,物品空间很大,这主要是相对于书和电影而言。
消费每首歌的代价很小 对于在线音乐来说,音乐都是免费的,不需要付费。
物品种类丰富 音乐种类丰富,有很多的流派。
听一首歌耗时很少 听一首音乐的时间成本很低,不太浪费用户的时间,而且用户大都把音乐作为背景声音,同时进行其他工作。
物品重用率很高 每首歌用户会听很多遍,这和其他物品不同,比如用户不会反复看一个电影,不会反复买一本书。
用户充满激情 用户很有激情,一个用户会听很多首歌。
上下文相关 用户的口味很受当时上下文的影响,这里的上下文主要包括用户当时的心情(比如沮丧的时候喜欢听励志的歌曲)和所处情境(比如睡觉前喜欢听轻音乐)。
次序很重要 用户听音乐一般是按照一定的次序一首一首地听。
很多播放列表资源 很多用户都会创建很多个人播放列表。
不需要用户全神贯注 音乐不需要用户全神贯注地听,很多用户将音乐作为背景声音。
高度社会化 用户听音乐的行为具有很强的社会化特性,比如我们会和好友分享自己喜欢的音乐。
上面这些特点决定了音乐是一种非常适合用来推荐的物品。因此,尽管现在很多推荐系统都是作为一个应用存在于网站中,比如亚马逊的商品推荐和Netflix的电影推荐,唯有音乐推荐可以支持独立的个性化推荐网站,比如Pandora、Last.fm和豆瓣网络电台。
1.2.4 社交网络
最近5年,互联网最激动人心的产品莫过于以Facebook和Twitter为代表的社交网络应用。在社交网络中,好友们可以互相分享、传播信息。社交网络中的个性化推荐技术主要应用在3个方面:
利用用户的社交网络信息对用户进行个性化的物品推荐;
信息流的会话推荐;
给用户推荐好友。
Facebook最宝贵的数据有两个,一个是用户之间的社交网络关系,另一个是用户的偏好信息。因此,Facebook推出了一个推荐API,称为Instant Personalization。该工具根据用户好友喜欢的信息,给用户推荐他们的好友最喜欢的物品。很多网站都使用了Facebook的API来实现网站的个性化。表1-1中是使用了Facebook的Instant Personalization的具有代表性的网站。图1-14是著名的电视剧推荐网站Clicker使用Instant Personalization给用户进行个性化视频推荐的界面。


除了利用用户在社交网站的社交网络信息给用户推荐本站的各种物品,社交网站本身也会利用社交网络给用户推荐其他用户在社交网站的会话。如图1-15所示,每个用户在Facebook的个人首页都能看到好友的各种分享,并且能对这些分享进行评论。每个分享和它的所有评论被称为一个会话,如何给这些会话排序是社交网站研究中的一个重要话题。为此,Facebook开发了EdgeRank算法对这些会话排序,使用户能够尽量看到熟悉的好友的最新会话。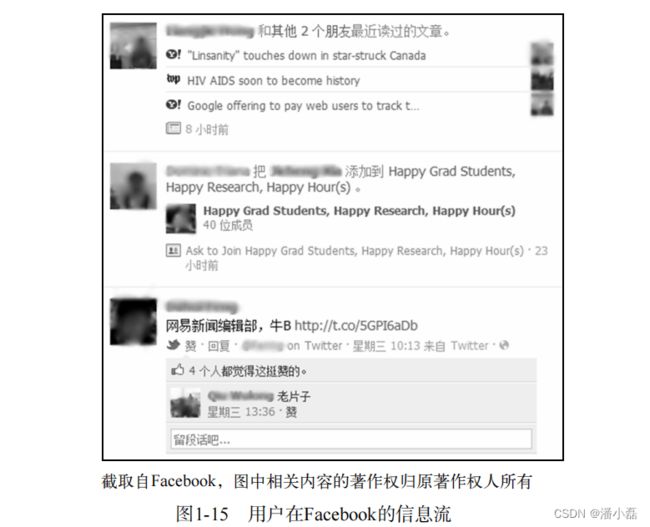
除了根据用户的社交网络以及用户行为给用户推荐内容,社交网站还通过个性化推荐服务给用户推荐好友。图1-16显示了著名社交网站的好友推荐界面。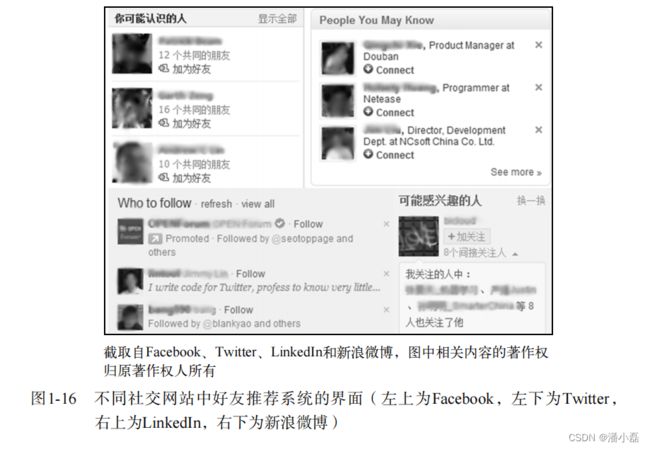
1.2.5 个性化阅读
阅读文章是很多互联网用户每天都会做的事情。个性化阅读同样符合前面提出的需要个性化推荐的两个因素:首先,互联网上的文章非常多,用户面临信息过载的问题;其次,用户很多时候并没有必须看某篇具体文章的需求,他们只是想通过阅读特定领域的文章了解这些领域的动态。
目前互联网上的个性化阅读工具很多,国际知名的有Google Reader,国内有鲜果网等。同时,随着移动设备的流行,移动设备上针对个性化阅读的应用也很多,其中具有代表性的有Zite和Flipboard。
Google Reader是一款流行的社会化阅读工具。它允许用户关注自己感兴趣的人,然后看到所关注用户分享的文章。如图1-17所示,如果单击左侧的People you follow(你关注的人),就可以看到其他用户分享的文章。
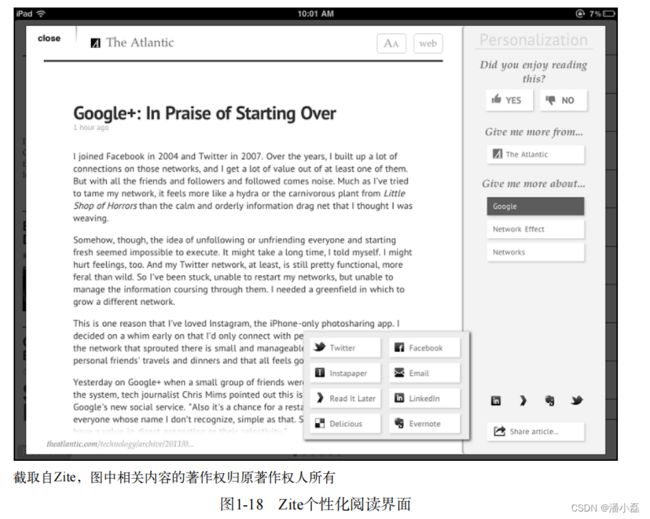
和Google Reader不同,个性化阅读工具Zite则是收集用户对文章的偏好信息。如图1-18所示,在每篇文章右侧,Zite都允许用户给出喜欢或不喜欢的反馈,然后通过分析用户的反馈数据不停地更新用户的个性化文章列表。Zite推出后获得了巨大的成功,后被CNN收购。
另一家著名的新闻阅读网站Digg也在首页尝试了推荐系统。Digg首先根据用户的Digg历史计算用户之间的兴趣相似度,然后给用户推荐和他兴趣相似的用户喜欢的文章。根据Digg自己的统计,在使用推荐系统后,用户的digg行为明显更加活跃,digg总数提高了40%,用户的好友数平均增加了24%,评论数增加了11%。
1.2.6 基于位置的服务
在中关村闲逛时,肚子饿了,打开手机,发现上面给你推荐了几家中关村不错的饭馆,价格、环境、服务、口味都如你所愿,这几乎就是基于位置的个性化推荐系统最理想的场景了。随着移动设备的飞速发展,用户的位置信息已经非常容易获取,而位置是一种很重要的上下文信息,基于位置给用户推荐离他近的且他感兴趣的服务,用户就更有可能去消费。
基于位置的服务往往和社交网络结合在一起。比如Foursquare推出了探索功能,给用户推荐好友在附近的行为(如图1-19所示)。
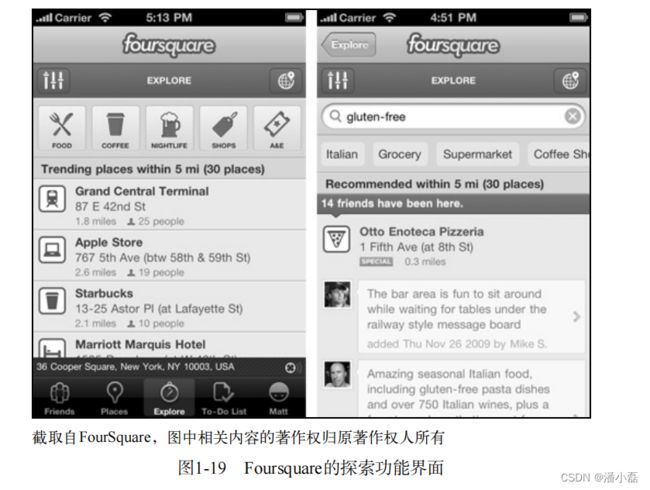
1.2.7 个性化邮件
我们每天都会收到大量的邮件,这些邮件有些对我们很重要(比如领导交代任务的邮件),有些比较次要(比如别人邀约周末打球的邮件),还有些是垃圾邮件。垃圾邮件可以通过垃圾邮件过滤器去除,这是一个专门的研究领域,这里就不讨论了。但在正常的邮件中,如果能够找到对用户重要的邮件让用户优先浏览,无疑会大大提高用户的工作效率。
其实,目前在文献中能够查到的第一个推荐系统Tapestry①就是一个个性化邮件推荐系统,它通过分析用户阅读邮件的历史行为和习惯对新邮件进行重新排序,从而提高用户的工作效率。
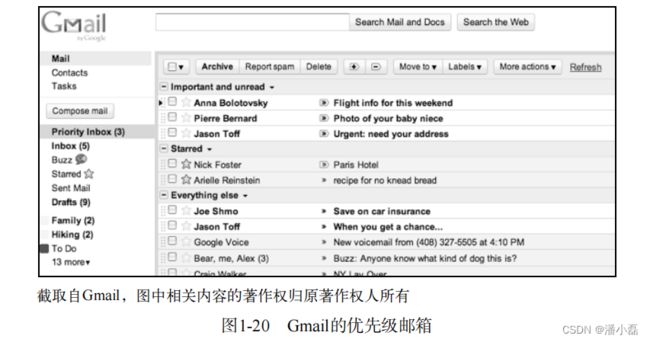
谷歌的研究人员在这个问题上也进行了深入研究,于2010年推出了优先级收件箱功能。如图1-20所示,该产品通过分析用户对邮件的历史行为,找到用户感兴趣的邮件,展示在一个专门的收件箱里。用户每天可以先浏览这个邮箱里的邮件,再浏览其他邮件。
谷歌的研究表明,该产品可以帮助用户节约6%的时间。在如今这个时间就是金钱的年代,6%的节约无疑是一大进步。
1.2.8 个性化广告
广告是互联网公司生存的根本。很多互联网公司的盈利模式都是基于广告的,而广告的CPC、CPM直接决定了很多互联网公司的收入。目前,很多广告都是随机投放的,即每次用户来了,随机选择一个广告投放给他。这种投放的效率显然很低,比如给男性投放化妆品广告或者给女性投放西装广告多半都是一种浪费。因此,很多公司都致力于广告定向投放(Ad Targeting)的研究,即如何将广告投放给它的潜在客户群。个性化广告投放目前已经成为了一门独立的学科——计算广告学——但该学科和推荐系统在很多基础理论和方法上是相通的,比如它们的目的都是联系用户和物品,只是在个性化广告中,物品就是广告。
个性化广告投放和狭义个性化推荐的区别是,个性化推荐着重于帮助用户找到可能令他们感兴趣的物品,而广告推荐着重于帮助广告找到可能对它们感兴趣的用户,即一个是以用户为核心,而另一个以广告为核心。目前的个性化广告投放技术主要分为3种。
上下文广告 通过分析用户正在浏览的网页内容,投放和网页内容相关的广告。代表系统是谷歌的Adsense。
搜索广告 通过分析用户在当前会话中的搜索记录,判断用户的搜索目的,投放和用户目的相关的广告。
个性化展示广告 我们经常在很多网站看到大量展示广告(就是那些大的横幅图片),它们是根据用户的兴趣,对不同用户投放不同的展示广告。雅虎是这方面研究的代表。
广告的个性化定向投放是很多互联网公司的核心技术,很多公司都秘而不宣。不过,雅虎公司是个例外,它发表了大量个性化广告方面的论文。
在个性化广告方面最容易获得成功的无疑是Facebook,因为它拥有大量的用户个人资料,可以很容易地获取用户的兴趣,让广告商选择自己希望对其投放广告的用户。图1-21展示了Facebook的广告系统界面,该界面允许广告商选择自己希望的用户群,然后Facebook会根据广告商的选择告诉他们这些限制条件下广告将会覆盖的用户数量。

1.3 推荐系统评测
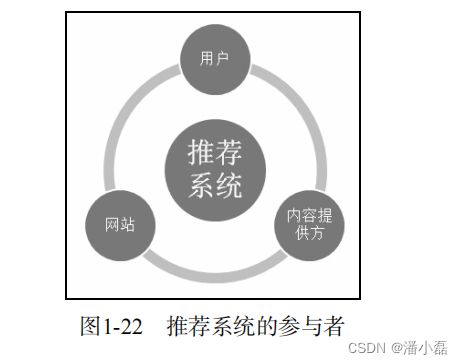
什么才是好的推荐系统?这是推荐系统评测需要解决的首要问题。一个完整的推荐系统一般存在3个参与方(如图1-22所示):用户、物品提供者和提供推荐系统的网站。以图书推荐为例,首先,推荐系统需要满足用户的需求,给用户推荐那些令他们感兴趣的图书。其次,推荐系统要让各出版社的书都能够被推荐给对其感兴趣的用户,而不是只推荐几个大型出版社的书。最后,好的推荐系统设计,能够让推荐系统本身收集到高质量的用户反馈,不断完善推荐的质量,增加用户和网站的交互,提高网站的收入。因此在评测一个推荐算法时,需要同时考虑三方的利益,一个好的推荐系统是能够令三方共赢的系统。
在推荐系统的早期研究中,很多人将好的推荐系统定义为能够作出准确预测的推荐系统。比如,一个图书推荐系统预测一个用户将来会购买《C++ Primer中文版》这本书,而用户后来确实购买了,那么这就被看做一次准确的预测。预测准确度是推荐系统领域的重要指标(没有之一)。这个指标的好处是,它可以比较容易地通过离线方式计算出来,从而方便研究人员快速评价和选择不同的推荐算法。但是,很多研究表明,准确的预测并不代表好的推荐。①比如说,该用户早就准备买《C++ Primer中文版》了,无论是否给他推荐,他都准备购买,那么这个推荐结果显然是不好的,因为它并未使用户购买更多的书,而仅仅是方便用户购买一本他本来就准备买的书。
那么,对于用户来说,他会觉得这个推荐结果很不新颖,不能令他惊喜。同时,对于《C++ Primer中文版》的出版社来说,这个推荐也没能增加这本书的潜在购买人数。所以,这是一个看上去很好,但其实却很失败的推荐。举一个更极端的例子,某推测系统预测明天太阳将从东方升起,虽然预测准确率是100%,却是一种没有意义的预测。
所以,好的推荐系统不仅仅能够准确预测用户的行为,而且能够扩展用户的视野,帮助用户发现那些他们可能会感兴趣,但却不那么容易发现的东西。同时,推荐系统还要能够帮助商家将那些被埋没在长尾中的好商品介绍给可能会对它们感兴趣的用户。这也正是《长尾理论》的作者在书中不遗余力介绍推荐系统的原因。
为了全面评测推荐系统对三方利益的影响,本章将从不同角度出发,提出不同的指标。这些指标包括准确度、覆盖度、新颖度、惊喜度、信任度、透明度等。这些指标中,有些可以离线计算,有些只有在线才能计算,有些只能通过用户问卷获得。下面各节将会依次介绍这些指标的出发点、含义,以及一些指标的计算方法。
1.3.1 推荐系统实验方法
在介绍推荐系统的指标之前,首先看一下计算和获得这些指标的主要实验方法。在推荐系统中,主要有3种评测推荐效果的实验方法,即离线实验(offline experiment)、用户调查(user study)和在线实验(online experiment)。下面将分别介绍这3种实验方法的优缺点。
1. 离线实验
离线实验的方法一般由如下几个步骤构成:
(1) 通过日志系统获得用户行为数据,并按照一定格式生成一个标准的数据集;
(2) 将数据集按照一定的规则分成训练集和测试集;
(3) 在训练集上训练用户兴趣模型,在测试集上进行预测;
(4) 通过事先定义的离线指标评测算法在测试集上的预测结果。
从上面的步骤可以看到,推荐系统的离线实验都是在数据集上完成的,也就是说它不需要一个实际的系统来供它实验,而只要有一个从实际系统日志中提取的数据集即可。这种实验方法的好处是不需要真实用户参与,可以直接快速地计算出来,从而方便、快速地测试大量不同的算法。
它的主要缺点是无法获得很多商业上关注的指标,如点击率、转化率等,而找到和商业指标非常相关的离线指标也是很困难的事情。表1-2简单总结了离线实验的优缺点。
2. 用户调查
注意,离线实验的指标和实际的商业指标存在差距,比如预测准确率和用户满意度之间就存在很大差别,高预测准确率不等于高用户满意度。因此,如果要准确评测一个算法,需要相对比较真实的环境。最好的方法就是将算法直接上线测试,但在对算法会不会降低用户满意度不太有把握的情况下,上线测试具有较高的风险,所以在上线测试前一般需要做一次称为用户调查的测试。
用户调查需要有一些真实用户,让他们在需要测试的推荐系统上完成一些任务。在他们完成任务时,我们需要观察和记录他们的行为,并让他们回答一些问题。最后,我们需要通过分析他们的行为和答案了解测试系统的性能。
用户调查是推荐系统评测的一个重要工具,很多离线时没有办法评测的与用户主观感受有关的指标都可以通过用户调查获得。比如,如果我们想知道推荐结果是否很令用户惊喜,那我们最好直接询问用户。但是,用户调查也有一些缺点。首先,用户调查成本很高,需要用户花大量时间完成一个个任务,并回答相关的问题。有些时候,还需要花钱雇用测试用户。因此,大多数情况下很难进行大规模的用户调查,而对于参加人数较少的用户调查,得出的很多结论往往没有统计意义。因此,我们在做用户调查时,一方面要控制成本,另一方面又要保证结果的统计意义。
此外,测试用户也不是随便选择的。需要尽量保证测试用户的分布和真实用户的分布相同,比如男女各半,以及年龄、活跃度的分布都和真实用户分布尽量相同。此外,用户调查要尽量保证是双盲实验,不要让实验人员和用户事先知道测试的目标,以免用户的回答和实验人员的测试受主观成分的影响。
用户调查的优缺点也很明显。它的优点是可以获得很多体现用户主观感受的指标,相对在线实验风险很低,出现错误后很容易弥补。缺点是招募测试用户代价较大,很难组织大规模的测试用户,因此会使测试结果的统计意义不足。此外,在很多时候设计双盲实验非常困难,而且用户在测试环境下的行为和真实环境下的行为可能有所不同,因而在测试环境下收集的测试指标可能在真实环境下无法重现。
3. 在线实验
在完成离线实验和必要的用户调查后,可以将推荐系统上线做AB测试,将它和旧的算法进行比较。
AB测试是一种很常用的在线评测算法的实验方法。它通过一定的规则将用户随机分成几组,并对不同组的用户采用不同的算法,然后通过统计不同组用户的各种不同的评测指标比较不同算法,比如可以统计不同组用户的点击率,通过点击率比较不同算法的性能。对AB测试感兴趣的可以浏览一下网站http://www.abtests.com/,该网站给出了很多通过实际AB测试提高网站用户满意度的例子,从中我们可以学习到如何进行合理的AB测试。
AB测试的优点是可以公平获得不同算法实际在线时的性能指标,包括商业上关注的指标。AB测试的缺点主要是周期比较长,必须进行长期的实验才能得到可靠的结果。因此一般不会用AB测试测试所有的算法,而只是用它测试那些在离线实验和用户调查中表现很好的算法。其次,一个大型网站的AB测试系统的设计也是一项复杂的工程。一个大型网站的架构分前端和后端,从前端展示给用户的界面到最后端的算法,中间往往经过了很多层,这些层往往由不同的团队控制,而且都有可能做AB测试。如果为不同的层分别设计AB测试系统,那么不同的AB测试之间往往会互相干扰。比如,当我们进行一个后台推荐算法的AB测试,同时网页团队在做推荐页面的界面AB测试,最终的结果就是你不知道测试结果是自己算法的改变,还是推荐界面的改变造成的。因此,切分流量是AB测试中的关键,不同的层以及控制这些层的团队需要从一个统一的地方获得自己AB测试的流量,而不同层之间的流量应该是正交的。
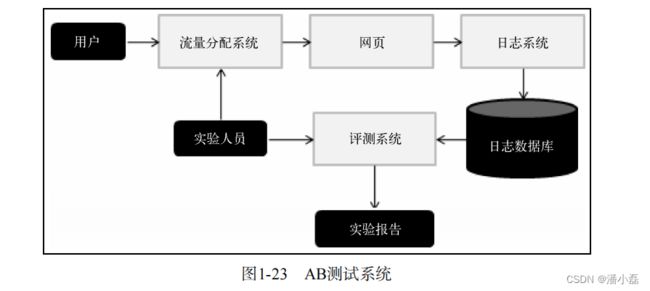
图1-23是一个简单的AB测试系统。用户进入网站后,流量分配系统决定用户是否需要被进行AB测试,如果需要的话,流量分配系统会给用户打上在测试中属于什么分组的标签。然后用户浏览网页,而用户在浏览网页时的行为都会被通过日志系统发回后台的日志数据库。此时,如果用户有测试分组的标签,那么该标签也会被发回后台数据库。在后台,实验人员的工作首先是配置流量分配系统,决定满足什么条件的用户参加什么样的测试。其次,实验人员需要统计日志数据库中的数据,通过评测系统生成不同分组用户的实验报告,并比较和评测实果。
一般来说,一个新的推荐算法最终上线,需要完成上面所说的3个实验。
首先,需要通过离线实验证明它在很多离线指标上优于现有的算法。
然后,需要通过用户调查确定它的用户满意度不低于现有的算法。
最后,通过在线的AB测试确定它在我们关心的指标上优于现有的算法。
介绍完3种主要的实验方法后,下一节将开始介绍推荐系统常用的实验指标,这些指标大部分都可以通过本节介绍的3种实验方法获得。
1.3.2 评测指标
本节将介绍各种推荐系统的评测指标。这些评测指标可用于评价推荐系统各方面的性能。这些指标有些可以定量计算,有些只能定性描述,有些可以通过离线实验计算,有些需要通过用户调查获得,还有些只能在线评测。对于重要的评测指标,后面几章将会详细讨论如何优化它们,本章只给出指标的定义。但对于一些次要的指标,本章在给出定义的同时也会顺便讨论一下应该如何优化。下面几节将详细讨论各个不同的指标。
1. 用户满意度
用户作为推荐系统的重要参与者,其满意度是评测推荐系统的最重要指标。但是,用户满意度没有办法离线计算,只能通过用户调查或者在线实验获得。
用户调查获得用户满意度主要是通过调查问卷的形式。用户对推荐系统的满意度分为不同的层次。GroupLens曾经做过一个论文推荐系统的调查问卷,该问卷的调查问题是请问下面哪句话最能描述你看到推荐结果后的感受?
推荐的论文都是我非常想看的。
推荐的论文很多我都看过了,确实是符合我兴趣的不错论文。
推荐的论文和我的研究兴趣是相关的,但我并不喜欢。
不知道为什么会推荐这些论文,它们和我的兴趣丝毫没有关系。
由此可以看出,这个调查问卷不是简单地询问用户对结果是否满意,而是从不同的侧面询问用户对结果的不同感受。比如,如果仅仅问用户是否满意,用户可能心里认为大体满意,但是对某个方面还有点不满,因而可能很难回答这个问题。因此在设计问卷时需要考虑到用户各方面的感受,这样用户才能针对问题给出自己准确的回答。
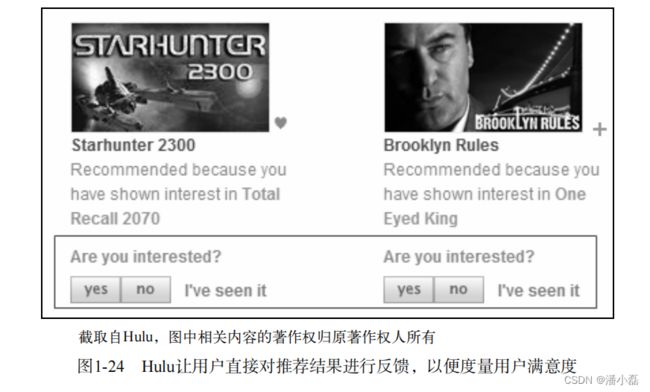
在在线系统中,用户满意度主要通过一些对用户行为的统计得到。比如在电子商务网站中,用户如果购买了推荐的商品,就表示他们在一定程度上满意。因此,我们可以利用购买率度量用户的满意度。此外,有些网站会通过设计一些用户反馈界面收集用户满意度。比如在视频网站Hulu的推荐页面(如图1-24所示)和豆瓣网络电台(如图1-25所示)中,都有对推荐结果满意或者不满意的反馈按钮,通过统计两种按钮的单击情况就可以度量系统的用户满意度。更一般的情况下,我们可以用点击率、用户停留时间和转化率等指标度量用户的满意度。

2. 预测准确度
预测准确度度量一个推荐系统或者推荐算法预测用户行为的能力。这个指标是最重要的推荐系统离线评测指标,从推荐系统诞生的那一天起,几乎99%与推荐相关的论文都在讨论这个指标。这主要是因为该指标可以通过离线实验计算,方便了很多学术界的研究人员研究推荐算法。
在计算该指标时需要有一个离线的数据集,该数据集包含用户的历史行为记录。然后,将该数据集通过时间分成训练集和测试集。最后,通过在训练集上建立用户的行为和兴趣模型预测用户在测试集上的行为,并计算预测行为和测试集上实际行为的重合度作为预测准确度。
由于离线的推荐算法有不同的研究方向,因此下面将针对不同的研究方向介绍它们的预测准确度指标。
● 评分预测
很多提供推荐服务的网站都有一个让用户给物品打分的功能(如图1-26所示)。那么,如果知道了用户对物品的历史评分,就可以从中习得用户的兴趣模型,并预测该用户在将来看到一个他没有评过分的物品时,会给这个物品评多少分。预测用户对物品评分的行为称为评分预测。
评分预测的预测准确度一般通过均方根误差(RMSE)和平均绝对误差(MAE)计算。对于测试集中的一个用户u和物品i,令rui是用户u对物品i的实际评分,而 rˆui 是推荐算法给出的预测评分,那么RMSE的定义为: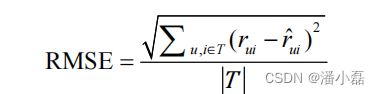
MAE采用绝对值计算预测误差,它的定义为: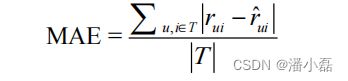
假设我们用一个列表records存放用户评分数据,令records[i] = [u,i,rui,pui],其中rui是用户u对物品i的实际评分,pui是算法预测出来的用户u对物品i的评分,那么下面的代码分别实现了RMSE和MAE的计算过程。
def RMSE(records):
return math.sqrt(\
sum([(rui-pui)*(rui-pui) for u,i,rui,pui in records])\
/ float(len(records)))
def MAE(records):
return sum([abs(rui-pui) for u,i,rui,pui in records])\
/ float(len(records))
关于RMSE和MAE这两个指标的优缺点, Netflix认为RMSE加大了对预测不准的用户物品评分的惩罚(平方项的惩罚),因而对系统的评测更加苛刻。研究表明,如果评分系统是基于整数建立的(即用户给的评分都是整数),那么对预测结果取整会降低MAE的误差。
● TopN推荐
网站在提供推荐服务时,一般是给用户一个个性化的推荐列表,这种推荐叫做TopN推荐。TopN推荐的预测准确率一般通过准确率(precision)/召回率(recall)度量。
令R(u)是根据用户在训练集上的行为给用户作出的推荐列表,而T(u)是用户在测试集上的行为列表。那么,推荐结果的召回率定义为:

推荐结果的准确率定义为:
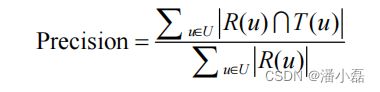
下面的Python代码同时计算出了一个推荐算法的准确率和召回率
def PrecisionRecall(test, N):
hit = 0
n_recall = 0
n_precision = 0
for user, items in test.items():
rank = Recommend(user, N)
hit += len(rank & items)
n_recall += len(items)
n_precision += N
return [hit / (1.0 * n_recall), hit / (1.0 * n_precision)]
有的时候,为了全面评测TopN推荐的准确率和召回率,一般会选取不同的推荐列表长度N,计算出一组准确率/召回率,然后画出准确率/召回率曲线(precision/recall curve)。
● 关于评分预测和TopN推荐的讨论
评分预测一直是推荐系统研究的热点,绝大多数推荐系统的研究都是基于用户评分数据的评分预测。这主要是因为,一方面推荐系统的早期研究组GroupLens的研究主要就是基于电影评分数据MovieLens进行的,其次,Netflix大赛也主要面向评分预测问题。因而,很多研究人员都将研究精力集中在优化评分预测的RMSE上。
对此,亚马逊前科学家Greg Linden有不同的看法。2009年, 他在Communications of the ACM网站发表了一篇文章,指出电影推荐的目的是找到用户最有可能感兴趣的电影,而不是预测用户看了电影后会给电影什么样的评分。因此,TopN推荐更符合实际的应用需求。也许有一部电影用户看了之后会给很高的分数,但用户看的可能性非常小。因此,预测用户是否会看一部电影,应该比预测用户看了电影后会给它什么评分更加重要。因此,本书主要也是讨论TopN推荐。
3. 覆盖率
覆盖率(coverage)描述一个推荐系统对物品长尾的发掘能力。覆盖率有不同的定义方法,最简单的定义为推荐系统能够推荐出来的物品占总物品集合的比例。假设系统的用户集合为U,推荐系统给每个用户推荐一个长度为N的物品列表R(u)。那么推荐系统的覆盖率可以通过下面的公式计算:
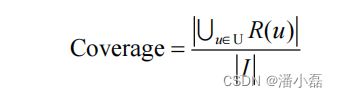
从上面的定义可以看到,覆盖率是一个内容提供商会关心的指标。以图书推荐为例,出版社可能会很关心他们的书有没有被推荐给用户。覆盖率为100%的推荐系统可以将每个物品都推荐给至少一个用户。此外,从上面的定义也可以看到,热门排行榜的推荐覆盖率是很低的,它只会推荐那些热门的物品,这些物品在总物品中占的比例很小。一个好的推荐系统不仅需要有比较高的用户满意度,也要有较高的覆盖率。
但是上面的定义过于粗略。覆盖率为100%的系统可以有无数的物品流行度分布。为了更细致地描述推荐系统发掘长尾的能力,需要统计推荐列表中不同物品出现次数的分布。如果所有的物品都出现在推荐列表中,且出现的次数差不多,那么推荐系统发掘长尾的能力就很好。因此,可以通过研究物品在推荐列表中出现次数的分布描述推荐系统挖掘长尾的能力。如果这个分布比较平,那么说明推荐系统的覆盖率较高,而如果这个分布较陡峭,说明推荐系统的覆盖率较低。在信息论和经济学中有两个著名的指标可以用来定义覆盖率。第一个是信息熵:
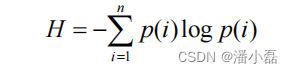
这里p(i)是物品i的流行度除以所有物品流行度之和。
第二个指标是基尼系数(Gini Index):

这里,ij是按照物品流行度p()从小到大排序的物品列表中第j个物品。下面的代码可以用来计算给定物品流行度分布后的基尼系数:
def GiniIndex(p):
j = 1
n = len(p)
G = 0
for item, weight in sorted(p.items(), key=itemgetter(1)):
G += (2 * j - n - 1) * weight
return G / float(n - 1)
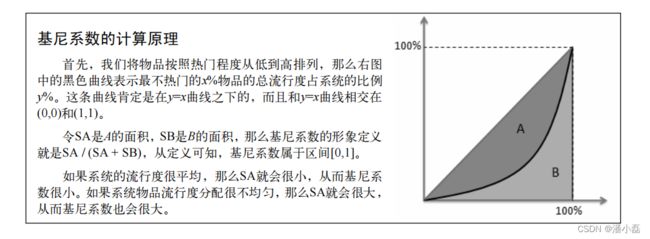
社会学领域有一个著名的马太效应,即所谓强者更强,弱者更弱的效应。如果一个系统会增大热门物品和非热门物品的流行度差距,让热门的物品更加热门,不热门的物品更加不热门,那么这个系统就有马太效应。比如,首页的热门排行榜就有马太效应。进入排行榜的都是热门的物品,但它们因为被放在首页的排行榜展示有了更多的曝光机会,所以会更加热门。相反,没有进入排行榜的物品得不到展示,就会更不热门。搜索引擎的PageRank算法也具有一定的马太效应,如果一个网页的某个热门关键词排名很高,并因此被展示在搜索结果的第一条,那么它就会获得更多的关注,从而获得更多的外链,PageRank排名也越高。
那么,推荐系统是否有马太效应呢?推荐系统的初衷是希望消除马太效应,使得各种物品都能被展示给对它们感兴趣的某一类人群。但是,很多研究表明现在主流的推荐算法(比如协同过滤算法)是具有马太效应的。评测推荐系统是否具有马太效应的简单办法就是使用基尼系数。如果G1是从初始用户行为中计算出的物品流行度的基尼系数,G2是从推荐列表中计算出的物品流行度的基尼系数,那么如果G2 > G1,就说明推荐算法具有马太效应。
4. 多样性
用户的兴趣是广泛的,在一个视频网站中,用户可能既喜欢看《猫和老鼠》一类的动画片,也喜欢看成龙的动作片。那么,为了满足用户广泛的兴趣,推荐列表需要能够覆盖用户不同的兴趣领域,即推荐结果需要具有多样性。多样性推荐列表的好处用一句俗话表述就是“不在一棵树上吊死”。尽管用户的兴趣在较长的时间跨度中是一样的,但具体到用户访问推荐系统的某一刻,其兴趣往往是单一的,那么如果推荐列表只能覆盖用户的一个兴趣点,而这个兴趣点不是用户这个时刻的兴趣点,推荐列表就不会让用户满意。反之,如果推荐列表比较多样,覆盖了用户绝大多数的兴趣点,那么就会增加用户找到感兴趣物品的概率。因此给用户的推荐列表也需要满足用户广泛的兴趣,即具有多样性。
多样性描述了推荐列表中物品两两之间的不相似性。因此,多样性和相似性是对应的。假设si j ( , ) [0,1] 定义了物品i和j之间的相似度,那么用户u的推荐列表R(u)的多样性定义如下:
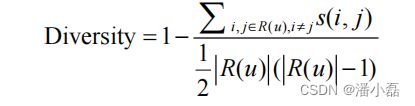
而推荐系统的整体多样性可以定义为所有用户推荐列表多样性的平均值:
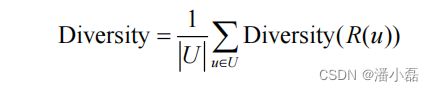
从上面的定义可以看到,不同的物品相似度度量函数s(i, j)可以定义不同的多样性。如果用内容相似度描述物品间的相似度,我们就可以得到内容多样性函数,如果用协同过滤的相似度函数描述物品间的相似度,就可以得到协同过滤的多样性函数。
关于推荐系统多样性最好达到什么程度,可以通过一个简单的例子说明。假设用户喜欢动作片和动画片,且用户80%的时间在看动作片,20%的时间在看动画片。那么,可以提供4种不同的推荐列表:A列表中有10部动作片,没有动画片;B列表中有10部动画片,没有动作片;C列表中有8部动作片和2部动画片;D列表有5部动作片和5部动画片。在这个例子中,一般认为C列表是最好的,因为它具有一定的多样性,但又考虑到了用户的主要兴趣。A满足了用户的主要兴趣,但缺少多样性,D列表过于多样,没有考虑到用户的主要兴趣。B列表即没有考虑用户的主要兴趣,也没有多样性,因此是最差的。
5. 新颖性
新颖的推荐是指给用户推荐那些他们以前没有听说过的物品。在一个网站中实现新颖性的最简单办法是,把那些用户之前在网站中对其有过行为的物品从推荐列表中过滤掉。比如在一个视频网站中,新颖的推荐不应该给用户推荐那些他们已经看过、打过分或者浏览过的视频。但是,有些视频可能是用户在别的网站看过,或者是在电视上看过,因此仅仅过滤掉本网站中用户有过行为的物品还不能完全实现新颖性。
O’scar Celma在博士论文“Music Recommendation and Discovery in the Long Tail”中研究了新颖度的评测。评测新颖度的最简单方法是利用推荐结果的平均流行度,因为越不热门的物品越可能让用户觉得新颖。因此,如果推荐结果中物品的平均热门程度较低,那么推荐结果就可能有比较高的新颖性。
但是,用推荐结果的平均流行度度量新颖性比较粗略,因为不同用户不知道的东西是不同的。因此,要准确地统计新颖性需要做用户调查。
最近几年关于多样性和新颖性的研究越来越受到推荐系统研究人员的关注。ACM的推荐系统会议在2011年有一个专门的研讨会讨论推荐的多样性和新颖性。该研讨会的组织者认为,通过牺牲精度来提高多样性和新颖性是很容易的,而困难的是如何在不牺牲精度的情况下提高多样性和新颖性。关心这两个指标的读者可以关注一下这个研讨会最终发表的论文。
6. 惊喜度
惊喜度(serendipity)是最近这几年推荐系统领域最热门的话题。但什么是惊喜度,惊喜度与新颖性有什么区别是首先需要弄清楚的问题。注意,这里讨论的是惊喜度和新颖度作为推荐指标在意义上的区别,而不是这两个词在中文里的含义区别(因为这两个词是英文词翻译过来的,所以它们在中文里的含义区别和英文词的含义区别并不相同),所以我们首先要摒弃大脑中关于这两个词在中文中的基本含义。
可以举一个例子说明这两种指标的区别。假设一名用户喜欢周星驰的电影,然后我们给他推荐了一部叫做《临歧》的电影(该电影是1983年由刘德华、周星驰、梁朝伟合作演出的,很少有人知道这部有周星驰出演的电影),而该用户不知道这部电影,那么可以说这个推荐具有新颖性。但是,这个推荐并没有惊喜度,因为该用户一旦了解了这个电影的演员,就不会觉得特别奇怪。但如果我们给用户推荐张艺谋导演的《红高粱》,假设这名用户没有看过这部电影,那么他看完这部电影后可能会觉得很奇怪,因为这部电影和他的兴趣一点关系也没有,但如果用户看完电影后觉得这部电影很不错,那么就可以说这个推荐是让用户惊喜的。这个例子的原始版本来自于Guy Shani的论文①,他的基本意思就是,如果推荐结果和用户的历史兴趣不相似,但却让用户觉得满意,那么就可以说推荐结果的惊喜度很高,而推荐的新颖性仅仅取决于用户是否听说过这个推荐结果。
目前并没有什么公认的惊喜度指标定义方式,这里只给出一种定性的度量方式。上面提到,令用户惊喜的推荐结果是和用户历史上喜欢的物品不相似,但用户却觉得满意的推荐。那么,定义惊喜度需要首先定义推荐结果和用户历史上喜欢的物品的相似度,其次需要定义用户对推荐结果的满意度。前面也曾提到,用户满意度只能通过问卷调查或者在线实验获得,而推荐结果和用户历史上喜欢的物品相似度一般可以用内容相似度定义。也就是说,如果获得了一个用户观看电影的历史,得到这些电影的演员和导演集合A,然后给用户推荐一个不属于集合A的导演和演员创作的电影,而用户表示非常满意,这样就实现了一个惊喜度很高的推荐。因此提高推荐惊喜度需要提高推荐结果的用户满意度,同时降低推荐结果和用户历史兴趣的相似度。
惊喜度的问题最近几年获得了学术界的一定关注,但这方面的工作还不是很成熟。相关工作可以参考Yuan Cao Zhang等的论文和Tomoko Murakami等的论文,本书就不对该问题进一步展开讨论了。
7. 信任度
如果你有两个朋友,一个人你很信任,一个人经常满嘴跑火车,那么如果你信任的朋友推荐你去某个地方旅游,你很有可能听从他的推荐,但如果是那位满嘴跑火车的朋友推荐你去同样的地方旅游,你很有可能不去。这两个人可以看做两个推荐系统,尽管他们的推荐结果相同,但用户却可能产生不同的反应,这就是因为用户对他们有不同的信任度。
对于基于机器学习的自动推荐系统,同样存在信任度(trust)的问题,如果用户信任推荐系统,那就会增加用户和推荐系统的交互。特别是在电子商务推荐系统中,让用户对推荐结果产生信任是非常重要的。同样的推荐结果,以让用户信任的方式推荐给用户就更能让用户产生购买欲,而以类似广告形式的方法推荐给用户就可能很难让用户产生购买的意愿。
度量推荐系统的信任度只能通过问卷调查的方式,询问用户是否信任推荐系统的推荐结果。因为本书后面的章节不太涉及如何提高推荐系统信任度的问题,因此这里简单介绍一下如何提高用户对推荐结果的信任度,以及关于信任度的一些研究现状。
提高推荐系统的信任度主要有两种方法。首先需要增加推荐系统的透明度(transparency),而增加推荐系统透明度的主要办法是提供推荐解释。只有让用户了解推荐系统的运行机制,让用户认同推荐系统的运行机制,才会提高用户对推荐系统的信任度。其次是考虑用户的社交网络信息,利用用户的好友信息给用户做推荐,并且用好友进行推荐解释。这是因为用户对他们的好友一般都比较信任,因此如果推荐的商品是好友购买过的,那么他们对推荐结果就会相对比较信任。
关于推荐系统信任度的研究主要集中在评论网站Epinion的推荐系统上。这是因为Epinion创建了一套用户之间的信任系统来建立用户之间的信任关系,帮助用户判断是否信任当前用户对某一个商品的评论。如图1-27所示,当用户在Epinion上浏览一个商品时,他会通过用户评论判断是否购买该商品。Epinion为了防止垃圾评论或者广告评论影响用户的决策,在每条用户评论的右侧都显示了评论作者的信息,并且让用户判断是信任该评论人还是将他加入黑名单。如果网站具有Epinion的用户信任系统,那么可以在给用户做推荐时,尽量推荐他信任的其他用户评论过的物品。

8. 实时性
在很多网站中,因为物品(新闻、微博等)具有很强的时效性,所以需要在物品还具有时效性时就将它们推荐给用户。比如,给用户推荐昨天的新闻显然不如给用户推荐今天的新闻。因此,在这些网站中,推荐系统的实时性就显得至关重要。
推荐系统的实时性包括两个方面。首先,推荐系统需要实时地更新推荐列表来满足用户新的行为变化。比如,当一个用户购买了iPhone,如果推荐系统能够立即给他推荐相关配件,那么肯定比第二天再给用户推荐相关配件更有价值。很多推荐系统都会在离线状态每天计算一次用户推荐列表,然后于在线期间将推荐列表展示给用户。这种设计显然是无法满足实时性的。与用户行为相应的实时性,可以通过推荐列表的变化速率来评测。如果推荐列表在用户有行为后变化不大,或者没有变化,说明推荐系统的实时性不高。
实时性的第二个方面是推荐系统需要能够将新加入系统的物品推荐给用户。这主要考验了推荐系统处理物品冷启动的能力。关于如何将新加入系统的物品推荐给用户,本书将在后面的章节进行讨论,而对于新物品推荐能力,我们可以利用用户推荐列表中有多大比例的物品是当天新加的来评测
9. 健壮性
任何一个能带来利益的算法系统都会被人攻击,这方面最典型的例子就是搜索引擎。搜索引擎的作弊和反作弊斗争异常激烈,这是因为如果能让自己的商品成为热门搜索词的第一个搜索果,会带来极大的商业利益。推荐系统目前也遇到了同样的作弊问题,而健壮性(即robust,鲁棒性)指标衡量了一个推荐系统抗击作弊的能力。
2011年的推荐系统大会专门有一个关于推荐系统健壮性的教程。作者总结了很多作弊方法,其中最著名的就是行为注入攻击(profile injection attack)。众所周知,绝大部分推荐系统都是通过分析用户的行为实现推荐算法的。比如,亚马逊有一种推荐叫做“购买商品A的用户也经常购买的其他商品”。它的主要计算方法是统计购买商品A的用户购买其他商品的次数。那么,我们可以很简单地攻击这个算法,让自己的商品在这个推荐列表中获得比较高的排名,比如可以注册很多账号,用这些账号同时购买A和自己的商品。还有一种攻击主要针对评分系统,比如豆瓣的电影评分。这种攻击很简单,就是雇用一批人给自己的商品非常高的评分,而评分行为是推荐系统依赖的重要用户行为。
算法健壮性的评测主要利用模拟攻击。首先,给定一个数据集和一个算法,可以用这个算法给这个数据集中的用户生成推荐列表。然后,用常用的攻击方法向数据集中注入噪声数据,然后利用算法在注入噪声后的数据集上再次给用户生成推荐列表。最后,通过比较攻击前后推荐列表的相似度评测算法的健壮性。如果攻击后的推荐列表相对于攻击前没有发生大的变化,就说明算法比较健壮。在实际系统中,提高系统的健壮性,除了选择健壮性高的算法,还有以下方法。
设计推荐系统时尽量使用代价比较高的用户行为。比如,如果有用户购买行为和用户浏览行为,那么主要应该使用用户购买行为,因为购买需要付费,所以攻击购买行为的代价远远大于攻击浏览行为。
在使用数据前,进行攻击检测,从而对数据进行清理。
10. 商业目标
很多时候,网站评测推荐系统更加注重网站的商业目标是否达成,而商业目标和网站的盈利模式是息息相关的。一般来说,最本质的商业目标就是平均一个用户给公司带来的盈利。不过这种指标不是很难计算,只是计算一次需要比较大的代价。因此,很多公司会根据自己的盈利模式设计不同的商业目标。
不同的网站具有不同的商业目标。比如电子商务网站的目标可能是销售额,基于展示广告盈利的网站其商业目标可能是广告展示总数,基于点击广告盈利的网站其商业目标可能是广告点击总数。因此,设计推荐系统时需要考虑最终的商业目标,而网站使用推荐系统的目的除了满足用户发现内容的需求,也需要利用推荐系统加快实现商业上的指标。
11. 总结
本节提到了很多指标,其中有些指标可以离线计算,有些只能在线获得。但是,离线指标很多,在线指标也很多,那么如何优化离线指标来提高在线指标是推荐系统研究的重要问题。关于这个问题,目前仍然没有什么定论,只是不同系统的研究人员有不同的感性认识。
表1-3对前面提到的指标进行了总结。

对于可以离线优化的指标,我个人的看法是应该在给定覆盖率、多样性、新颖性等限制条件下,尽量优化预测准确度。用一个数学公式表达,离线实验的优化目标是:最大化预测准确度使得 覆盖率 > A多样性 > B新颖性 > C 其中,A、B、C的取值应该视不同的应用而定。
1.3.3 评测维度
上一节介绍了很多评测指标,但是在评测系统中还需要考虑评测维度,比如一个推荐算法,虽然整体性能不好,但可能在某种情况下性能比较好,而增加评测维度的目的就是知道一个算法在什么情况下性能最好。这样可以为融合不同推荐算法取得最好的整体性能带来参考。
一般来说,评测维度分为如下3种。
用户维度 主要包括用户的人口统计学信息、活跃度以及是不是新用户等。
物品维度 包括物品的属性信息、流行度、平均分以及是不是新加入的物品等。
时间维度 包括季节,是工作日还是周末,是白天还是晚上等。
如果能够在推荐系统评测报告中包含不同维度下的系统评测指标,就能帮我们全面地了解推荐系统性能,找到一个看上去比较弱的算法的优势,发现一个看上去比较强的算法的缺点。