LSTM神经网络和GRU
说到LSTM,无可避免的首先要提到最简单最原始的RNN。
在循环神经网络(RNN)中学习了RNN的原理和模型结构,这里再简单回顾一下,引出LSTM模型。
一、RNN
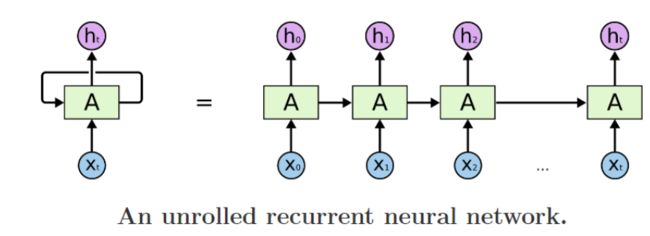
循环神经网络(Recurrent Neural Network,RNN)是一种用于处理序列数据的神经网络。相比一般的神经网络来说,他能够处理序列变化的数据。比如某个单词的意思会因为上文提到的内容不同而有不同的含义,RNN就能够很好地解决这类问题。
二、LSTM神经网络
长短时记忆网络(Long Short Term Memory Network, LSTM)是一种时间递归神经网络,它出现的原因是为了解决RNN的一个致命的缺陷。
原生的RNN会遇到一个很大的问题,叫做The vanishing gradient problem for RNNs,也就是后面时间的节点会出现老年痴呆症,也就是忘事儿,这使得RNN在很长一段时间内都没有受到关注,网络只要一深就没法训练。
而LSTM网络具有“记忆性”,其原因在于不同“时间点”之间的网络存在连接,而不是单个时间点处的网络存在前馈或者反馈;并且LSTM擅长于处理多个变量的问题,该特性使其有助于解决时间序列预测问题。
想要了解LSTM的原理可以参考:零基础入门深度学习(6) - 长短时记忆网络(LSTM)
三、LSTM和RNN的区别
长短时记忆网络(Long Short Term Memory Network, LSTM) 是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
LSTM结构(图右)和普通RNN的主要输入输出区别如下所示:
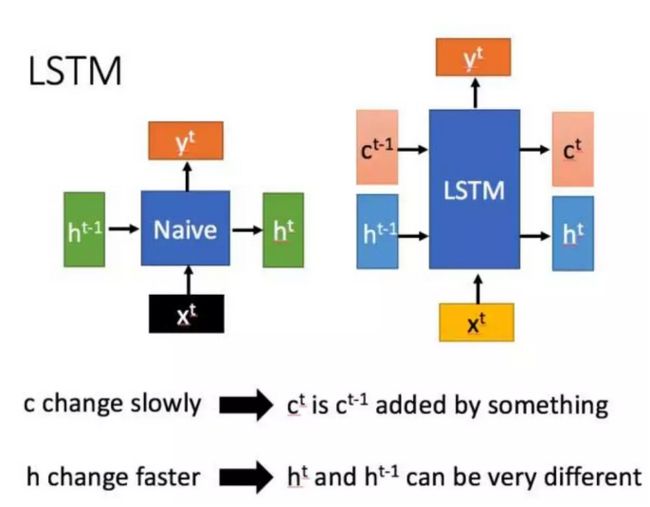
相比RNN只有一个传递状态ht,LSTM有两个传输状态,一个ct(cell state)和一个 ht(hidden state)。
注:RNN中的 ht 相当于LSTM的 ct。
其实对于传递下去的 ct 改变的很慢,通常输出的 ct 是上一个状态传过来的c t − 1 ^{t-1} t−1加上一些数值。而 ht 则在不同节点下往往会有很大的区别。
四、深入LSTM结构
LSTM和普通RNN如贵族和乞丐,RNN什么信息它都存下来,因为它没有挑选的能力,而LSTM不一样,它会选择性的存储信息,因为它能力强,它有门控装置,它可以尽情的选择。
如下图,普通RNN只有中间的Memory Cell用来存所有的信息,而从下图我们可以看到,LSTM多了三个Gate,也就是三个门,什么意思呢?在现实生活中,门就是用来控制进出的,门关上了,你就进不去房子了,门打开你就能进去,同理,这里的门是用来控制每一时刻信息记忆与遗忘的。

依次来解释一下这三个门:
- Input Gate:中文是输入门,在每一时刻从输入层输入的信息会首先经过输入门,输入门的开关会决定这一时刻是否会有信息输入到Memory Cell。
- Output Gate:中文是输出门,每一时刻是否有信息从Memory Cell输出取决于这一道门。
- Forget Gate:中文是遗忘门,每一时刻Memory Cell里的值都会经历一个是否被遗忘的过程,就是由该门控制的,如果打卡,那么将会把Memory Cell里的值清除,也就是遗忘掉。
按照上图的顺序,信息在传递的顺序,是这样的:
先经过输入门,看是否有信息输入,再判断遗忘门是否选择遗忘Memory Cell里的信息,最后再经过输出门,判断是否将这一时刻的信息进行输出。
下面具体对LSTM内部结构剖析:
首先使用LSTM的当前输入xt 和上一个状态传递下来的h t − 1 ^{t-1} t−1 拼接训练得到四个状态。
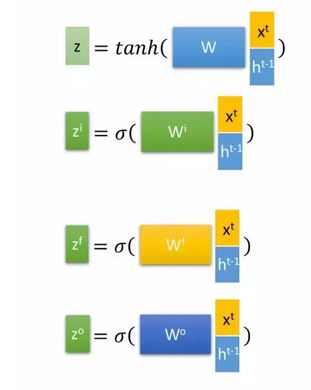

下面开始进一步介绍这四个状态在LSTM内部的使用。

LSTM内部主要的三个阶段:
- 忘记阶段。这个阶段主要是对上一个节点传进来的输入进行选择性忘记,简单的说就是会“忘记不重要的,记住重要的”。具体来说是通过计算得到的zf (f表示forget) 来作为忘记控门,来控制上一个状态 c t − 1 ^{t-1} t−1 哪些需要留哪些需要忘。
- 选择记忆阶段。这个阶段的输入有选择性的进行“记忆”,主要是会对输入 xt 进行选择记忆。哪些重要则着重记录下来,不重要,则少记一些。当前的输入内容由前面计算得到的 z 表示。而选择的门控信号由 zi (i代表information)来进行控制。
- 输出阶段。这个阶段将决定哪些将会被当成当前状态的输出。主要是通过 zo 来进行控制的。并且还对上一个阶段得到的 co 进行了放缩(通过一个tanh激活函数进行变化)。
以上,就是LSTM的内部结构。通过门控状态来控制传输状态,记住需要长时间记忆的,忘记不重要的信息;而不像普通的RNN那样只能够“呆萌”地仅有一种记忆叠加方式。对很多需要“长期记忆”的任务来说,尤其好用。
但也因为引入了很多内容,导致参数变多,也使得训练难度加大了很多。因此很多时候我们往往会使用效果和LSTM相当但参数更少的GRU来构建大训练量的模型。
五、GRU
GRU(Gate Recurrent Unit)是循环神经网络(Recurrent Neural Network, RNN)的一种。和LSTM(Long-Short Term Memory)一样,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的。
相比LSTM,使用GRU能够达到相当的效果,并且相比之下更容易进行训练,能够很大程度上提高训练效率,因此很多时候会更倾向于使用GRU。
GRU的具体内部结构:

首先,我们先通过上一个传输下来的状态 h t − 1 ^{t-1} t−1 和当前节点的输入 xt 来获取两个门控状态。其中 r 控制重置的门控(reset gate), z 为控制更新的门控(update gate)。

得到门控信号之后,首先使用重置门控来得到“重置”之后的数据 h t − 1 ′ ^{t-1'} t−1′ = h t − 1 ^{t-1} t−1 与 r 矩阵对应元素相乘,再将 h t − 1 ′ ^{t-1'} t−1′ 与输入 xt 进行拼接,再通过一个tanh激活函数来将数据放缩到**-1~1**的范围内。

这里的h’ 主要是包含了当前输入的 xt 数据。有针对性地对h’ 添加到当前的隐藏状态,相当于”记忆了当前时刻的状态“。
最后介绍GRU最关键的一个步骤,我们可以称之为”更新记忆“阶段。
在这个阶段,我们同时进行了遗忘了记忆两个步骤。我们使用了先前得到的更新门控 z (update gate)。
更新表达式:
![]()
首先再次强调一下,门控信号(这里的 z])的范围为0~1。门控信号越接近1,代表”记忆“下来的数据越多;而越接近0则代表”遗忘“的越多。
GRU很聪明的一点就在于,我们使用了同一个门控 z 就同时可以进行遗忘和选择记忆(LSTM则要使用多个门控)。
GRU总结:
GRU输入输出的结构与普通的RNN相似,其中的内部思想与LSTM相似。
与LSTM相比,GRU内部少了一个”门控“,参数比LSTM少,但是却也能够达到与LSTM相当的功能。考虑到硬件的计算能力和时间成本,因而很多时候我们也就会选择更加”实用“的GRU啦。
参考:
史上最详细循环神经网络讲解(RNN/LSTM/GRU)
深度学习:人人都能看懂的LSTM
零基础入门深度学习(6) - 长短时记忆网络(LSTM)
LSTM梳理,理解,和keras实现 (一)
人人都能看懂的GRU