评价类模型
- 层次分析法(AHP)
- 优劣距离解法(Topsis)
在解决评价类问题之前,首先要确定的三个问题:
- 我们的评价目标是什么?
- 我们为了达到这个目标有哪几种可选的方案?
- 评价的准则或者指标是什么?以及各个指标权重的确定。
层次分析法
1.确定评价指标
根据已有发表的同主题论文,专家的看法。
搜索网站:谷歌>百度>微信>知乎
2.确定指标的权重
分而治之的思想
两个两个指标进行比较,最终根据两两比较的结果来推算出权重。
【注】两指标比较的重要程度表:(有时候重要性也可解释为满意度)
| 标度 | 含义 |
|---|---|
| 1 | 表示两个因素相比,具有同等重要性 |
| 3 | 表示两个因素相比,一个因素比另一个因素稍微重要 |
| 5 | 表示两个因素相比,一个因素比另一个因素明显重要 |
| 7 | 表示两个因素相比,一个因素比另一个因素强烈重要 |
| 9 | 表示两个因素相比,一个因素比另一个因素极端重要 |
| 2,4,6,8 | 上述两相邻判断的中值 |
| 倒数 | 如果A和B相比,标度为3,那么B和A相比就是1/3 |
设计指标重要程度比较表即判断矩阵。
【注】这个比较表是由“专家”填的
| 指标1 | 指标2 | 指标3 | … | 指标n | |
|---|---|---|---|---|---|
| 指标1 | a 11 a_{11} a11 | a 12 a_{12} a12 | a 13 a_{13} a13 | … | a 1 n a_{1n} a1n |
| 指标2 | a 21 a_{21} a21 | a 22 a_{22} a22 | a 23 a_{23} a23 | … | a 2 n a_{2n} a2n |
| 指标3 | a 31 a_{31} a31 | a 32 a_{32} a32 | a 33 a_{33} a33 | … | a 3 n a_{3n} a3n |
| ⋮ \vdots ⋮ | ⋮ \vdots ⋮ | ⋮ \vdots ⋮ | ⋮ \vdots ⋮ | ⋱ \ddots ⋱ | ⋮ \vdots ⋮ |
| 指标n | a n 1 a_{n1} an1 | a n 2 a_{n2} an2 | a n 3 a_{n3} an3 | … | a n n a_{nn} ann |
表中的n*n个元素构成n*n判断矩阵
【注】判断矩阵:判断矩阵表示针对上一层次的某元素, 本层次与它有关的元素之间相对重要性的比较
- a i j a_{ij} aij代表的含义是,与指标 j j j相比, i i i的重要程度。
- 当 i = j i=j i=j时,同等重要记为1,因此主对角线元素为1。
- a i j > 0 a_{ij}>0 aij>0且满足 a i j ∗ a j i = 1 a_{ij}*a_{ji}=1 aij∗aji=1。(满足该条件的我们称为正互反矩阵,所以判断矩阵一定是正互反矩阵)
三种方法根据判断矩阵求指标的权重
求出各个方案在不同指标下的得分
针对每一个指标填写判断矩阵
【满意程度】
| 标度 | 含义 |
|---|---|
| 1 | 表示两个因素相比,具有同等重要性 |
| 3 | 表示两个因素相比,一个因素比另一个因素稍微重要 |
| 5 | 表示两个因素相比,一个因素比另一个因素明显重要 |
| 7 | 表示两个因素相比,一个因素比另一个因素强烈重要 |
| 9 | 表示两个因素相比,一个因素比另一个因素极端重要 |
| 2,4,6,8 | 上述两相邻判断的中值 |
| 倒数 | 如果A和B相比,标度为3,那么B和A相比就是1/3 |
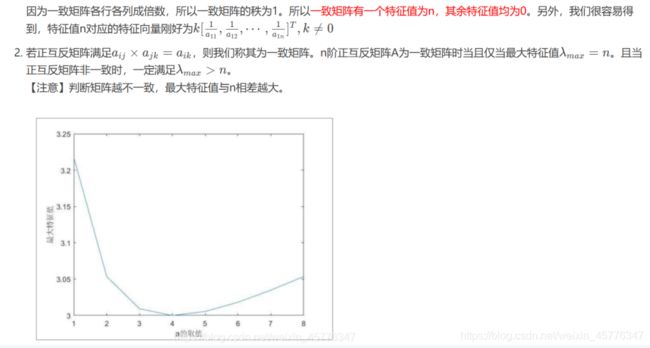
一致性检验
【注意】出现不一致现象!
判断矩阵可能会有互相矛盾的问题:A>B,B>C,A=C同时出现。
【解决】一致矩阵(一致性检验)
一致矩阵的特点:
a i j = i 的 重 要 程 度 j 的 重 要 程 度 , a j k = j 的 重 要 程 度 k 的 重 要 程 度 a_{ij}=\frac{i的重要程度}{j的重要程度},a_{jk}=\frac{j的重要程度}{k的重要程度} aij=j的重要程度i的重要程度,ajk=k的重要程度j的重要程度
所以: a i k = i 的 重 要 程 度 j 的 重 要 程 度 = a i j a j k a_{ik}=\frac{i的重要程度}{j的重要程度}=\frac{a_{ij}}{a_{jk}} aik=j的重要程度i的重要程度=ajkaij
从矩阵上来看,该特点表现为各行各列之间成倍数关系。(每一行或每一列为一个整体)
一致矩阵的定义:
矩阵中每个元素 a i j > 0 a_{ij}>0 aij>0且满足 a i j ∗ a j i = 1 a_{ij}*a_{ji}=1 aij∗aji=1,则称该矩阵为正互反矩阵。在层次分析法中我们构造的判断矩阵是正互反矩阵,若正互反矩阵满足 a i j ∗ a j k = a i k a_{ij}*a_{jk}=a_{ik} aij∗ajk=aik,我们称其为一致矩阵。
在使用判断矩阵求权重之前,必须对其进行一致性检验






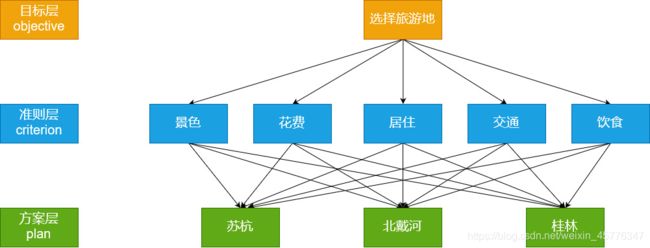
【总结】层次分析法的步骤
-
分析系统中各因素之间的关系,建立系统的递阶层次结构。
论文中一定要有层次结构图
可以使用流程图绘制软件:
【例子】选择旅游地
-
对于同一层次的个元素关于上一层次中某一项(准则)的重要性进行两两比较,构造判断矩阵。
- 任何评价类模型都具有一定的主观性,论文中判断矩阵中的数字基本都是自己填的,可以不用交代数据来源。
- 准则层——方案层中判断矩阵的数值要结合实际来写,如果题目中有其他数据,可以考虑利用这些数据进行计算。
- 判断矩阵表示针对上一层次的某元素, 本层次与它有关的元素之间相对重要性的比较
- 由判断矩阵计算被比较元素对于该准则的相对权重,并进行一致性检验(检验通过,权重才能用)
- 三种方法计算权重:(1)算术平均法(2)几何平均法(3)特征值法
- 三种方法最好都使用,为了结果的稳健性。
【例如】本文采用了三种方法分别求出权重,三种方法的结果相差不大,进一步说明了权重计算的可靠性,最终的权重采用三种方法的平均值。再根据得到的权重矩阵计算各个方案的得分,并进行排序和综合分析,这样避免了采用单一方法所造成的偏差,得出的结论更全面,更有效。 - 一致性检验的步骤,以CR=0.1为界,若未通过一致性检验,应当适当修改模型数据(判断矩阵中的数值)。
- 计算各层元素对系统目标的合成权重,并进行排序。
层次分析法的局限性
- 评价的决策层(方案层)不能太多,同样准则层也不能太多。太多的话n会很大,判断矩阵跟一致矩阵的差异可能会很大。平均随机一致性指标RI的表格中n最多是15。
- 如果决策层中的指标数据是已知的,则判断矩阵中的数值不再由自己主观填写,这个时候,层次分析法不再适用。应该利用这些客观数据使评价更加准确。
模型拓展
.
TOPSIS——优劣解距离法
针对层次分析法的局限性,TOPSIS法是一种综合评价方法,其能充分利用原始数据的信息,其结果能精确地反映各评价方案之间的差距。
【基本过程】
先将原始数据矩阵统一指标类型(指标正向化),得到正向化后的矩阵,在对正向化后的矩阵进行标准化处理以消除各指标量纲的影响,并找到优先方案中的最优方案和最劣方案,然后分别计算各评价对象与最优方案和最劣方案之间的距离,获得各评价对象与最优方案的相对接近程度,以此作为评价优劣的根据。该方法对于数据分布以及样本容量没有严格限制,数据计算简单易行。
TOSIS求解的一般步骤
将原始矩阵正向化
如果该评价任务涉及到多个指标,并且每个指标的类型也不同,则需要进行正向化
最常见的四种指标:
| 指标名称 | 指标特点 | 例子 |
|---|---|---|
| 极大型指标(效益型指标) | 越大越好 | 成绩,GDP增速,企业利润 |
| 极小型指标(成本型指标) | 越小越好 | 费用,坏品率 |
| 中间型指标 | 越接近某个值越好 | 水质量评估时PH |
| 区间型指标 | 落在某个区间最好 | 体温,水中植物性营养物量 |
将原始矩阵正向化就是指将所有的指标统一化成极大型指标(转换的函数形式不唯一)
- 极小型指标
m a x − x max-x max−x如果所有元素均为正数,那么也可以使用倒数 1 x \frac{1}{x} x1 - 中间型指标
设指标序列为 { x i } \{ x_{i}\} {xi},且最佳数值为 x b e s t x_{best} xbest,正向化后的序列为 { x ~ i } \left \{ \widetilde{x}_{i} \right \} {x i},则 M = m a x { ∣ x i − x b e s t ∣ } , x ~ i = 1 − ∣ x i − x b e s t ∣ M M=max\left \{ |x_i-x_{best}| \right \},\tilde{x}_i=1-\frac{|x_i-x_{best}|}{M} M=max{∣xi−xbest∣},x~i=1−M∣xi−xbest∣
【例子】
| PH值(转换前) | PH值(转换后) |
|---|---|
| 6 | 1-|6-7|/2=1/2 |
| 7 | 1-|7-7|/2=1 |
| 8 | 1-|8-7|/2=1/2 |
| 9 | 1-|9-7|/2=0 |
M = m a x { ∣ x i − x b e s t ∣ } = 2 , x b e s t = 7 M=max\left \{ |x_i-x_{best}| \right \}=2,x_{best}=7 M=max{∣xi−xbest∣}=2,xbest=7
- 区间型指标
{ x i } \left \{x_i \right \} {xi}是一组区间型指标,且最佳区间为[a,b],那么正向化的公式如下:
M = m a x { a − m i n { x i } , m a x { x i } − b } , x ~ i = { 1 − a − x M , x < a 1 , a ≤ x ≤ b 1 − x − b M , x > b M=max \left \{a-min\left \{x_i \right\},max\left \{x_i \right\}-b \right \},\tilde{x}_i=\left\{\begin{matrix} 1-\frac{a-x}{M},x
【例子】
| 体温转换前) | 体温(转换后) |
|---|---|
| 35.2 | 0.4286 |
| 35.8 | 0.8571 |
| 36.6 | 1 |
| 37.1 | 0.9286 |
| 37.8 | 0.4286 |
| 38.4 | 0 |
a = 36 , b = 37 , M = m a x { 36 − 35.2 , 38.4 − 37 } = 1.4 a=36,b=37 ,M=max\left \{ 36-35.2,38.4-37 \right \}=1.4 a=36,b=37,M=max{36−35.2,38.4−37}=1.4
正向化矩阵标准化
标准化的目的是为了消除不同指标量纲的影响
假设有n个要评价的对象,m个评价指标(已经正向化了的)构成正向化矩阵如下:
X = [ x 11 x 12 ⋯ x 1 m x 21 x 22 ⋯ x 2 m ⋮ ⋮ ⋱ ⋮ x n 1 x n 2 ⋯ x n m ] X=\begin{bmatrix} x_{11} & x_{12} & \cdots & x_{1m}\\ x_{21} & x_{22} & \cdots & x_{2m}\\ \vdots & \vdots & \ddots & \vdots\\ x_{n1} & x_{n2} & \cdots & x_{nm} \end{bmatrix} X=⎣⎢⎢⎢⎡x11x21⋮xn1x12x22⋮xn2⋯⋯⋱⋯x1mx2m⋮xnm⎦⎥⎥⎥⎤
那么对其标准化的矩阵记为Z,Z中每一个元素 z i j = x i j ∑ i = 1 n x i j 2 ( 每 一 个 元 素 其 所 在 列 的 元 素 的 平 方 和 ) z_{ij}=\frac{x_{ij}}{\sqrt{\sum_{i=1}^{n}x_{ij}^{2}}}(\frac{每一个元素}{\sqrt{其所在列的元素的平方和}}) zij=∑i=1nxij2xij(其所在列的元素的平方和每一个元素)
【注】,标准化的方法有很多种,主要目的就是为了去除量纲的影响,例如还有 x − x 的 均 值 x 的 标 准 差 \frac{x-x的均值}{x的标准差} x的标准差x−x的均值,具体选用哪一种方法并没有很大的限制,这里采用的方法是以前论文中用得比较多的方法。
计算得分并归一化
假设上面标准化的矩阵为 Z = [ z 11 z 12 ⋯ z 1 n z 21 z 22 ⋯ z 2 n ⋮ ⋮ ⋱ ⋮ z m 1 z m 2 ⋯ z m n ] Z=\begin{bmatrix} z_{11} & z_{12} & \cdots & z_{1n}\\ z_{21} & z_{22} & \cdots & z_{2n}\\ \vdots & \vdots & \ddots & \vdots\\ z_{m1} & z_{m2} & \cdots & z_{mn} \end{bmatrix} Z=⎣⎢⎢⎢⎡z11z21⋮zm1z12z22⋮zm2⋯⋯⋱⋯z1nz2n⋮zmn⎦⎥⎥⎥⎤
定义最大值或者最优方案: Z − = ( Z 1 + , Z 2 + , ⋯ , Z m + ) = ( m a x { z 11 , z 21 , ⋯ , z n 1 } , m a x { z 21 , z 22 , ⋯ , z 2 n } , ⋯ , m a x { z 1 m , z 2 m , ⋯ , z n m } ) \begin{aligned} Z^-&=(Z_{1}^+,Z_{2}^+,\cdots,Z_{m}^+)\\ &=(max\left \{ z_{11},z_{21},\cdots,z_{n1} \right \},max\left \{ z_{21},z_{22},\cdots,z_{2n} \right \},\cdots,max\left \{ z_{1m},z_{2m},\cdots,z_{nm} \right \}) \end{aligned} Z−=(Z1+,Z2+,⋯,Zm+)=(max{z11,z21,⋯,zn1},max{z21,z22,⋯,z2n},⋯,max{z1m,z2m,⋯,znm})
定义最小值或最劣方案: Z − = ( Z 1 − , Z 2 − , ⋯ , Z m − ) = ( m i n { z 11 , z 21 , ⋯ , z n 1 } , m i n { z 21 , z 22 , ⋯ , z 2 n } , ⋯ , m i n { z 1 m , z 2 m , ⋯ , z n m } ) \begin{aligned} Z^-&=(Z_{1}^-,Z_{2}^-,\cdots,Z_{m}^-)\\ &=(min\left \{ z_{11},z_{21},\cdots,z_{n1} \right \},min\left \{ z_{21},z_{22},\cdots,z_{2n} \right \},\cdots,min\left \{ z_{1m},z_{2m},\cdots,z_{nm} \right \}) \end{aligned} Z−=(Z1−,Z2−,⋯,Zm−)=(min{z11,z21,⋯,zn1},min{z21,z22,⋯,z2n},⋯,min{z1m,z2m,⋯,znm})
定义第 i ( i = 1 , 2 , ⋯ , n ) i(i=1,2,\cdots,n) i(i=1,2,⋯,n)个评价对象与最大值的距离 D i + = ∑ j = 1 m ( Z j + − z i j ) 2 D_{i}^+=\sqrt{\sum_{j=1}^{m}(Z_{j}^+-z_{ij})^2} Di+=∑j=1m(Zj+−zij)2
定义第 i ( i = 1 , 2 , ⋯ , n ) i(i=1,2,\cdots,n) i(i=1,2,⋯,n)个评价对象与最小值之间的距离为 D i − = ∑ j = 1 m ( Z j − − z i j ) 2 D_{i}^-=\sqrt{\sum_{j=1}^{m}(Z_{j}^--z_{ij})^2} Di−=∑j=1m(Zj−−zij)2
由此我们可以计算出第 i ( i = 1 , 2 , ⋯ , n ) i(i=1,2,\cdots,n) i(i=1,2,⋯,n)个评价对象的未归一化的得分为 S i = D i − D i + + D i − S_i=\frac{D_{i}^-}{D_{i}^++D_{i}^-} Si=Di++Di−Di−很明显 0 ≤ S i ≤ 1 0\leq S_{i}\leq 1 0≤Si≤1,且 S i 越 大 , D i + 越 小 S_{i}越大,D_{i}^+越小 Si越大,Di+越小,即越接近最大值。
【说明】构造计算评分的公式: x − m i n m a x − m i n = x − m i n m a x − x + x − m i n \frac{x-min}{max-min}=\frac{x-min}{max-x+x-min} max−minx−min=max−x+x−minx−min
对于最大值和最小值来说,不论数值是多少,只要保持是最大和最小,这个公式求出的结果都是一样的,所以可能会存在不敏感的地方。
但是往往:
- 比较的对象一般要远大于两个。(例如比较一个班级的成绩)
- 比较的指标也往往不只是一个方面,例如成绩,工时数,课外竞赛得分等。
- 有很多指标不存在理论上的最大值和最小值,例如衡量经济增长水平的指标(GDP增速)
【注意】要区别好归一化与标准化
归一化的计算步骤也可以消去量纲的影响,但更多时候我们归一化的目的是为了让我们的结果更加容易解释,或者说让我们对结果有一个更加清晰直观的印象。例如得分归一化后,可以限制在0~1区间内,对区间内的每一个得分,我们很容易地得到其所处的比例位置。
TOPSIS模型拓展
- 若不同指标的权重不同,则在计算时,前面不变,后面计算未归一化的得分时,定义第 i ( i = 1 , 2 , ⋯ , n ) i(i=1,2,\cdots,n) i(i=1,2,⋯,n)个评价对象与最大值的距离 D i + = ∑ j = 1 m ω j ( Z j + − z i j ) 2 D_{i}^+=\sqrt{\sum_{j=1}^{m}\omega _j(Z_{j}^+-z_{ij})^2} Di+=∑j=1mωj(Zj+−zij)2
定义第 i ( i = 1 , 2 , ⋯ , n ) i(i=1,2,\cdots,n) i(i=1,2,⋯,n)个评价对象与最小值之间的距离为 D i − = ∑ j = 1 m ω j ( Z j − − z i j ) 2 D_{i}^-=\sqrt{\sum_{j=1}^{m}\omega _j(Z_{j}^--z_{ij})^2} Di−=∑j=1mωj(Zj−−zij)2,后面不变。