度量学习DML之Contrastive Loss及其变种
度量学习DML之Contrastive Loss及其变种_程大海的博客-CSDN博客
度量学习DML之Triplet Loss_程大海的博客-CSDN博客
度量学习DML之Lifted Structure Loss_程大海的博客-CSDN博客
度量学习DML之Circle Loss_程大海的博客-CSDN博客
度量学习DML之Cross-Batch Memory_程大海的博客-CSDN博客
度量学习DML之MoCO_程大海的博客-CSDN博客
数据增强之SpecAugment_程大海的博客-CSDN博客
数据增强之MixUp_程大海的博客-CSDN博客
度量学习的目标:
- 相似的或者属于同一类的样本提取到的embedding向量之间具有更高的相似度,或者具有更小的空间距离
- 对于out-of samples的样本,也就是未见过的样本,希望也能提取到有效的embedding,也就是模型的泛化能力更好
Contrastive Loss(对比损失)
论文:《Dimensionality Reduction by Learning an Invariant Mapping》
假设![]() 和
和![]() 表示两个样本的embedding向量,
表示两个样本的embedding向量,![]() 表示
表示![]() 和
和![]() 是同类(或者说相似),
是同类(或者说相似),![]() 表示
表示![]() 和
和![]() 不同类(或者说不相似),
不同类(或者说不相似),![]() 表示
表示![]() 和
和![]() 之间的距离(如欧式距离)或者相似度(如余弦相似度),表示如下:
之间的距离(如欧式距离)或者相似度(如余弦相似度),表示如下:
![]()
其中![]() 表示通过参数学习到的一个非线性embedding转换函数,
表示通过参数学习到的一个非线性embedding转换函数,![]() 表示学习到的参数。
表示学习到的参数。
那么,对于一个对于contrastive loss,一个训练样本就由![]() 这个三元组组成,这个三元组的损失函数表示如下:
这个三元组组成,这个三元组的损失函数表示如下:
![]()
看到这个是不是眼前一亮,这不是Logistic Regression损失的形式吗?其中,![]() 表示相似样本对之间的损失,
表示相似样本对之间的损失,![]() 表示不相似样本对之间的损失。那么对于一个batch中的所有训练样本的损失就可以表示如下:
表示不相似样本对之间的损失。那么对于一个batch中的所有训练样本的损失就可以表示如下:
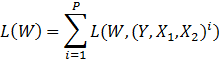
对于![]() 这个损失函数的优化目标是,对于相似的
这个损失函数的优化目标是,对于相似的![]() 和
和![]() ,训练得到较小的
,训练得到较小的![]() ,对于不相似的
,对于不相似的![]() 和
和![]() ,训练得到较大的
,训练得到较大的![]() 。
。
为了防止模型偷懒,直接将所有的样本都学习到同一个embedding,这种情况下导致计算的![]() 和总体的损失值
和总体的损失值![]() 全为0,完全没毛病,符合loss下降到0的要求。为了防止这种情况发生,需要再强加一个margin参数
全为0,完全没毛病,符合loss下降到0的要求。为了防止这种情况发生,需要再强加一个margin参数![]() 来进行限制,加了限制之后的损失函数如下:
来进行限制,加了限制之后的损失函数如下:
![]()
损失来源:
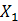 和
和 本来就相似,也就是
本来就相似,也就是 ,但是计算得到的
,但是计算得到的 不等于0,此时第一项产生loss
不等于0,此时第一项产生loss 和
和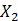 本来就不相似,也就是
本来就不相似,也就是 ,但是计算得到的
,但是计算得到的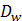 小于
小于 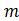 ,此时第二项产生loss
,此时第二项产生loss
总结来说就是,如果Y=0,只要![]() 不为0就不行,如果Y=1,只要D小于alpha就不行。
不为0就不行,如果Y=1,只要D小于alpha就不行。
修改后的公式与原始公式相比多了![]() 以及平方,这个不用管,是为了在进行求导时方便设置的,新增的参数
以及平方,这个不用管,是为了在进行求导时方便设置的,新增的参数![]() 是一个大于0的实数。对于这个公式,当
是一个大于0的实数。对于这个公式,当![]() 和
和![]() 不相似时,如果模型计算得到的
不相似时,如果模型计算得到的![]() 和
和![]() 之间的距离
之间的距离![]() 比
比![]() 小,说明模型没有将
小,说明模型没有将![]() 和
和![]() 区分的足够开,说明模型在这一对样本上还要进一步训练,所以就产生了损失值。如果模型计算得到的
区分的足够开,说明模型在这一对样本上还要进一步训练,所以就产生了损失值。如果模型计算得到的![]() 和
和![]() 之间的距离
之间的距离![]() 比
比![]() 大,说明模型已经很好的将不相似的样本
大,说明模型已经很好的将不相似的样本![]() 和
和 区分的足够开了,说明在这对样本上模型已经不需要训练了,此时的
区分的足够开了,说明在这对样本上模型已经不需要训练了,此时的![]() 为0。
为0。
关于![]() 的取值范围:假如距离度量函数采用欧式距离,在进行度量学习时,通常会对提取的特征向量
的取值范围:假如距离度量函数采用欧式距离,在进行度量学习时,通常会对提取的特征向量![]() 和
和![]() 进行归一化,那么特征向量
进行归一化,那么特征向量![]() 和
和![]() 的度量距离的范围
的度量距离的范围![]() ,所以
,所以![]() 的取值就可以取0-2之间的值,
的取值就可以取0-2之间的值,![]() 越小,表示限制越弱,学习到的不相似样本之间的差异就越小,
越小,表示限制越弱,学习到的不相似样本之间的差异就越小,![]() 越大,表示限制越强,学习到的不相似样本之间的差异就越大。
越大,表示限制越强,学习到的不相似样本之间的差异就越大。
Self-Supervised Contrastive Loss(自监督对比损失)
基于自监督的对比损失训练数据没有标签,需要自己想办法构造标签。
假设一个batch中的所有样本表示为![]() ,
,![]() 是batch的大小,对每个输入样本做两次随机的data augment数据增强,得到一个新的样本集合
是batch的大小,对每个输入样本做两次随机的data augment数据增强,得到一个新的样本集合![]() ,其中
,其中![]() 和
和![]() 是由
是由![]() 经过数据增强得到的,
经过数据增强得到的,![]() 。
。
假设![]() 表示batch中所有样本的索引编号,
表示batch中所有样本的索引编号,![]() 表示batch中与索引编号
表示batch中与索引编号![]() 对应的样本属于同一个父亲的样本,
对应的样本属于同一个父亲的样本,![]() 与
与![]() 的关系也就是上面所说的
的关系也就是上面所说的![]() 和
和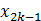 的关系,那么自监督的损失函数表示如下:
的关系,那么自监督的损失函数表示如下:
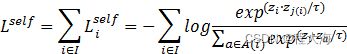
其中,![]() 与
与![]() 同源,对应于triplet loss中的说法,
同源,对应于triplet loss中的说法,![]() 叫做anchor,
叫做anchor,![]() 叫做positive,
叫做positive,![]() 是不同于
是不同于![]() 的其他类别,叫做negatives,相比于triplet loss中每个三元组只有一个anchor,一个positve和一个negative,Self-Supervised Contrastive Loss中包含一个anchor是
的其他类别,叫做negatives,相比于triplet loss中每个三元组只有一个anchor,一个positve和一个negative,Self-Supervised Contrastive Loss中包含一个anchor是![]() ,一个positive是
,一个positive是![]() 和一组
和一组![]() 个negatives是
个negatives是![]() ,并且使用的是cross-entropy交叉熵损失函数。
,并且使用的是cross-entropy交叉熵损失函数。
Supervised Contrastive Loss(监督对比损失)
论文:《Supervised Contrastive Learning》
基于监督的对比损失训练数据有标签,每个标签下面有若干个样本。在上述Self-Supervised Contrastive Loss中,计算loss的时候只有一个anchor,一个positive(通过data augment数据增强得到),若干个negatives,而在Supervised Contrastive Loss中,有若干个positive,每个positive都可以作为anchor,所以就有若干个anchor,还有若干个nagatives。由Self-Supervised Contrastive Loss的计算公式进一步可以拓展得到Supervised Contrastive Loss的如下两种形式:


这两种形式的区别就是log的位置是在求和的外面(out),还是在求和的里面(in),作者实验表明out形式的loss效果更好。![]() 是mini-batch中的positive样本集合,
是mini-batch中的positive样本集合,![]() 是
是![]() 中与
中与![]() 的ID身份相同的positive集合,
的ID身份相同的positive集合,![]() 是
是![]() 集合中样本的数量。所以,上述两个损失函数分两步计算:1)、分别计算mini-batch中每个类别的损失并求平均,也就是嵌套在里面的那个求和操作;2)、求和计算mini-batch中所有类别的总体损失。上述两种损失函数公式都体现了Supervised Contrastive Loss的输入可以是多个positive(同一类的数据)和多个negative(与positive不同类的数据)。Supervised Contrastive Loss比Self-Supervised Contrastive Loss在参与loss计算的样本数量上多,训练能力更强。
集合中样本的数量。所以,上述两个损失函数分两步计算:1)、分别计算mini-batch中每个类别的损失并求平均,也就是嵌套在里面的那个求和操作;2)、求和计算mini-batch中所有类别的总体损失。上述两种损失函数公式都体现了Supervised Contrastive Loss的输入可以是多个positive(同一类的数据)和多个negative(与positive不同类的数据)。Supervised Contrastive Loss比Self-Supervised Contrastive Loss在参与loss计算的样本数量上多,训练能力更强。
同时,论文中还提了一下Supervised Contrastive Loss与Triplet Loss和N-Pairs Loss的关系,论文表示Triplet Loss是Supervised Contrastive Loss的一个特殊形式,当只有一个positive和一个negative的时候,Supervised Contrastive Loss就是Triplet Loss,当有多个positive的时候,Supervised Contrastive Loss就是N-Pairs Loss。
参考:深度度量学习-论文简评 - 知乎
参考:深度度量学习中的损失函数 - 知乎
参考:GitHub - KevinMusgrave/pytorch-metric-learning: The easiest way to use deep metric learning in your application. Modular, flexible, and extensible. Written in PyTorch.
参考:PyTorch Metric Learning