美图离线ETL实践
美图收集的日志需要通过 ETL 程序清洗、规整,并持久化地落地于 HDFS / Hive,便于后续的统一分析处理。
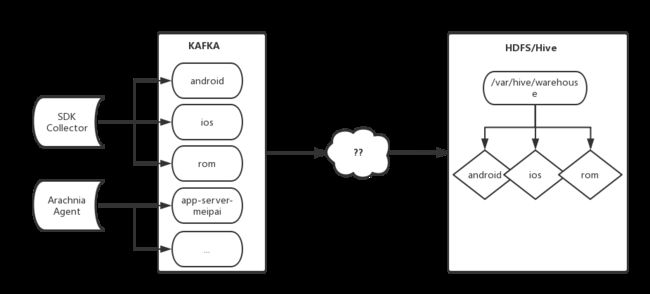
图 1
/ 什么是 ETL? /
ETL 即 Extract-Transform-Load,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。ETL 一词较常用在数据仓库,但其对象并不限于数据仓库。
在美图特有的业务环境下,ETL 需要做到以下需求:
1.大数据量、高效地清洗落地。美图业务繁多、用户基数大、数据量庞大,除此之外业务方希望数据采集后就能快速地查询到数据。
2.灵活配置、满足多种数据格式。由于不断有新业务接入,当有新业务方数据接入时要做到灵活通用、增加一个配置信息就可以对新业务数据进行清洗落地;同时每个业务方的数据格式各式各样,ETL 需要兼容多种通用数据格式,以满足不同业务的需求(如 json、avro、DelimiterText 等)。
3.约束、规范。需要满足数据库仓库规范,数据按不同层(STG 层、ODS 层等)、不同库(default.db、meipai.db 等)、不同分区(必须指定时间分区)落地。
4.容错性。考虑业务日志采集可能存在一定的脏数据,需要在达到特定的阈值时进行告警;并且可能出现 Hadoop 集群故障、Kafka 故障等各种状况,因此需要支持数据重跑恢复。
ETL 有两种形式:实时流 ETL 和 离线 ETL。
如图 2 所示,实时流 ETL 通常有两种形式:一种是通过 Flume 采集服务端日志,再通过 HDFS 直接落地;另一种是先把数据采集到 Kafka,再通过 Storm 或 Spark streaming 落地 HDFS,实时流 ETL 在出现故障的时候很难进行回放恢复。美图目前仅使用实时流 ETL 进行数据注入和清洗的工作。
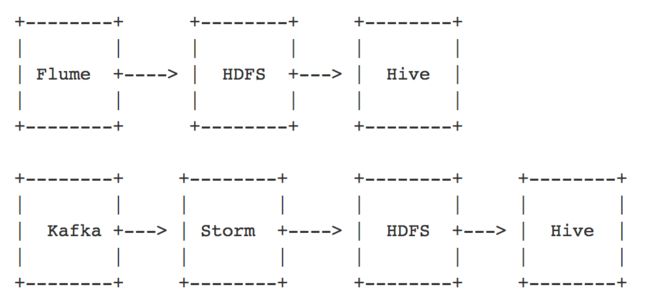
图 2
根据 Lambda 结构,如果实时流 ETL 出现故障需要离线 ETL 进行修补。离线 ETL 是从 Kafka拉取消息,经过 ETL 再从 HDFS 落地。为了提高实时性及减轻数据压力,离线 ETL 是每小时 05 分调度,清洗上一个小时的数据。为了减轻 HDFS NameNode 的压力、减少小文件,日期分区下同个 topic&partition 的数据是 append 追加到同一个日志文件。
/ 离线 ETL 的架构设计及实现原理 /
离线 ETL 采用 MapReduce 框架处理清洗不同业务的数据,主要是采用了分而治之的思想,能够水平扩展数据清洗的能力;
图 3:离线 ETL 架构
如图 3 所示,离线 ETL 分为三个模块:
Input(InputFormat):主要对数据来源(Kafka 数据)进行解析分片,按照一定策略分配到不同的 Map 进程处理;创建 RecordReader,用于对分片数据读取解析,生成 key-value 传送给下游处理。
Map(Mapper):对 key-value 数据进行加工处理。
Output (OutputFormat):创建 RecordWriter 将处理过的 key-value 数据按照库、表、分区落地;最后在 commit 阶段检测消息处理的完整性。
离线 ETL 工作流程
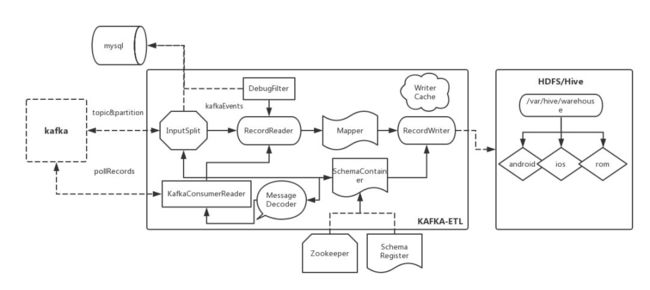
图 4
如图 4 所示是离线 ETL 的基本工作流程:
1.kafka-etl 将业务数据清洗过程中的公共配置信息抽象成一个 etl schema ,代表各个业务不同的数据;
2.在 kafka-etl 启动时会从 zookeeper 拉取本次要处理的业务数据 topic&schema 信息;
3.kafka-etl 将每个业务数据按 topic、partition 获取的本次要消费的 offset 数据(beginOffset、endOffset),并持久化 mysql;
4.kafka-etl 将本次需要处理的 topic&partition 的 offset 信息抽象成 kafkaEvent,然后将这些 kafkaEvent 按照一定策略分片,即每个 mapper 处理一部分 kafkaEvent;
5.RecordReader 会消费这些 offset 信息,解析 decode 成一个个 key-value 数据,传给下游清洗处理;
6.清洗后的 key-value 统一通过 RecordWriter 数据落地 HDFS。
离线 ETL 的模块实现
数据分片(Split)
我们从 kafka 获取当前 topic&partition 最大的 offset 以及上次消费的截止 offset ,组成本次要消费的[beginOffset、endOffset]kafkaEvent,kafkaEvent 会打散到各个 Mapper 进行处理,最终这些 offset 信息持久化到 mysql 表中。
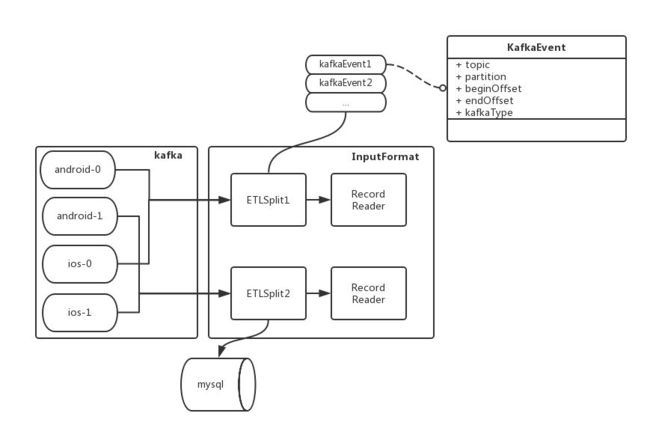
图 5
那么如何保证数据不倾斜呢?首先通过配置自定义mapper个数,并创建对应个数的ETLSplit。由于kafkaEevent包含了单个topic&partition之前消费的Offset以及将要消费的最大Offset,即可获得每个 kafkaEvent 需要消费的消息总量。最后遍历所有的 kafkaEevent,将当前 kafkaEevent 加入当前最小的 ETLSplit(通过比较需要消费的数据量总和,即可得出),通过这样生成的 ETLSplit 能尽量保证数据均衡。
数据解析清洗(Read)
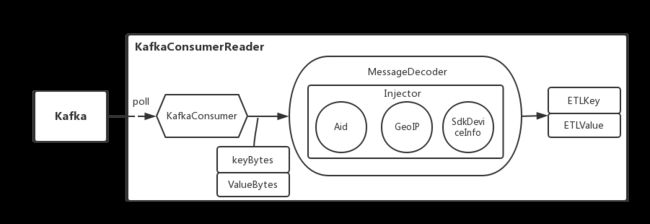
图 6
如图 6 所示,首先每个分片会有对应的 RecordReader 去解析,RecordReade 内包含多个 KafkaConsumerReader ,就是对每个 KafkaEevent 进行消费。每个 KafkaEevent 会对应一个 KafkaConsumer,拉取了字节数据消息之后需要对此进行 decode 反序列化,此时就涉及到 MessageDecoder 的结构。MessageDecoder 目前支持三种格式:
格式 |
涉及 topic |
|---|---|
Avro |
android、ios、ad_sdk_android... |
Json |
app-server-meipai、anti-spam... |
DelimiterText |
app-server-youyan、app-server-youyan-im... |
MessageDecoder 接收到 Kafka 的 key 和 value 时会对它们进行反序列化,最后生成 ETLKey 和 ETLValue。同时 MessageDecoder 内包含了 Injector,它主要做了如下事情:
注入 Aid:针对 arachnia agent 采集的日志数据,解析 KafkaKey 注入日志唯一标识 Aid;
注入 GeoIP 信息:根据 GeoIP 解析 ip 信息注入地理信息(如 country_id、province_id、city_id);
注入 SdkDeviceInfo: 本身实时流 ETL 会做注入 gid、is_app_new 等信息,但是离线 ETL 检测这些信息是否完整,做进一步保障。
过程中还有涉及到 DebugFilter,它将 SDK 调试设备的日志过滤,不落地到 HDFS。
多文件落地(Write)
由于 MapReduce 本身的 RecordWriter 不支持单个落地多个文件,需要进行特殊处理,并且 HDFS 文件是不支持多个进程(线程)writer、append,于是我们将 KafkaKey+ 业务分区+ 时间分区 + Kafka partition 定义一个唯一的文件,每个文件都是会到带上 kafka partition 信息。同时对每个文件创建一个 RecordWriter。
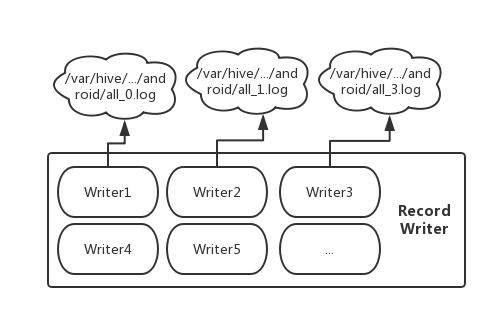
图 7
如图 7 所示,每个 RecordWriter 包含多个 Writer ,每个 Writer 对应一个文件,这样可以避免同一个文件多线程读写。目前是通过 guava cache 维护 writer 的数量,如果 writer 太多或者太长时间没有写访问就会触发 close 动作,待下批有对应目录的 kafka 消息在创建 writer 进行 append 操作。这样我们可以做到在同一个 map 内对多个文件进行写入追加。
检测数据消费完整性 (Commit)
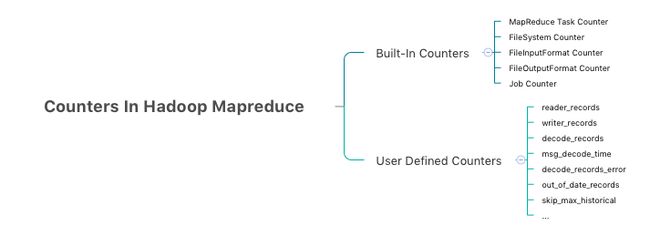
图 8
MapReduce Counter 为提供我们一个窗口,观察统计 MapReduce job 运行期的各种细节数据。并且它自带了许多默认 Counter,可以检测数据是否完整消费:
reader_records: 解析成功的消息条数;
decode_records_error: 解析失败的消息条数;
writer_records: 写入成功的消息条数;
...
最后通过本次要消费 topic offset 数量、reader_records 以及 writer_records 数量是否一致,来确认消息消费是否完整。
*允许一定比例的脏数据,若超出限度会生成短信告警
/ ETL 系统核心特征 /
数据补跑及其优化
ETL 是如何实现数据补跑以及优化的呢?首先了解一下需要重跑的场景:

*当用户调用 application kill 时会经历三个阶段:1) kill SIGTERM(-15) pid;2) Sleep for 250ms;3)kill SIGKILL(-9) pid 。
那么有哪些重跑的方式呢?

如图 9 所示是第三种重跑方式的整体流程,ETL 是按照小时调度的,首先将数据按小时写到临时目录中,如果消费失败会告警通知并重跑消费当前小时。如果落地成功则合并到仓库目录的目标文件,合并失败同样会告警通知并人工重跑,将小文件合并成目标文件。
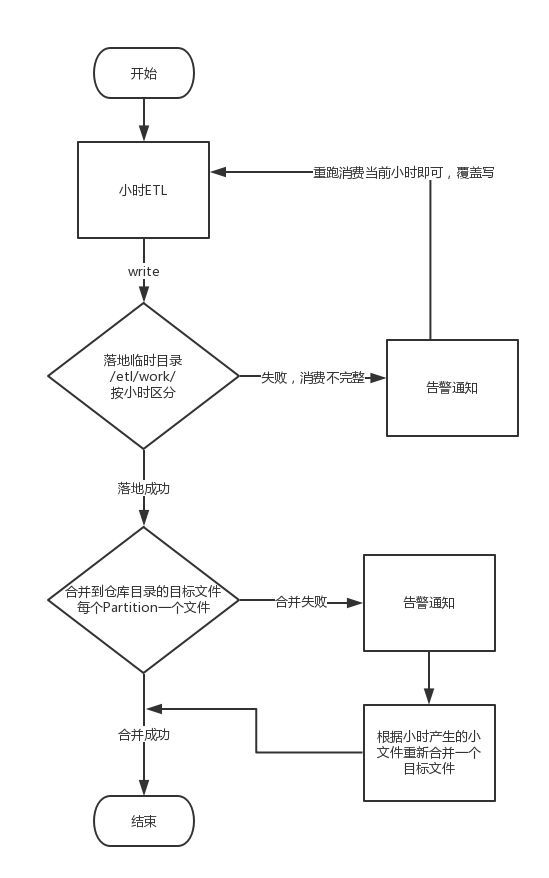
图 9
优化后的重跑情况分析如下表所示:

自动水平扩展
现在离线 Kafka-ETL 是每小时 05 分调度,每次调度的 ETL 都会获取每个 topic&partition 当前最新、最大的 latest offset,同时与上个小时消费的截止 offset 组合成本地要消费的 kafkaEvent。由于每次获取的 latest offset 是不可控的,有些情况下某些 topic&partition 的消息 offset 增长非常快,同时 kafka topic 的 partition 数量来不及调整,导致 ETL 消费处理延迟,影响下游的业务处理流程:
由于扩容、故障等原因需要补采集漏采集的数据或者历史数据,这种情况下 topic&&partition 的消息 offset 增长非常快,仅仅依赖 kafka topic partiton 扩容是不靠谱的,补采集完后面还得删除扩容的 partition;
周末高峰、节假日、6.18、双十一等用户流量高峰期,收集的用户行为数据会比平时翻几倍、几十倍,但是同样遇到来不及扩容 topic partition 个数、扩容后需要缩容的情况;
Kafka ETL 是否能自动水平扩展不强依赖于 kafka topic partition 的个数。如果某个 topic kafkaEvent 需要处理的数据过大,评估在合理时间范围单个 mapper 能消费的最大的条数,再将 kafkaEvent 水平拆分成多个子 kafkaEvent,并分配到各个 mapper 中处理,这样就避免单个 mapper 单次需要处理过大 kafkaEvent 而导致延迟,提高水平扩展能力。拆分的逻辑如图 10 所示:

图 10
后续我们将针对以下两点进行自动水平扩展的优化:
如果单个 mapper 处理的总消息数据比较大,将考虑扩容 mapper 个数并生成分片 split 进行负载均衡。
每种格式的消息处理速度不一样,分配时可能出现一些 mapper 负担比较重,将给每个格式配置一定的权重,根据消息条数、权重等结合一起分配 kafkaEvent。
