Day_50小结
目录
一. 比较和分析各种查找算法
二. 描述各种排序算法的特点和基本思想&比较分析各种排序算法
1. 插入排序
2. 交换排序
3. 选择排序
4. 外部排序
三. 设计一个自己的 Hash 函数和一个冲突解决机制
1. 对于哈希函数的构造:
2. 处理冲突的办法:
3. 代码展示:
一. 比较和分析各种查找算法
一般线性表的顺序查找:顺序查找对于顺序表和链表都适用,其基本思想就是通过对数字序列的递增顺序来扫描每个元素;若一直查找到序列的最后一个元素都没有找到需要查找的值则查找失败。
有序线性表的顺序查找:本质上和一般线性表的查找是一样的,区别在于判断查找失败的时候如果需要查找的值已经大于现在表内节点的值(假定有序表按升序排列),则直接判定失败,稍微减少了查找失败的长度,提高了效率。
折半查找:折半查找必须要在有序的顺序表内进行(链表不行),每次取区间的中间值和需要查找的值进行判断,若中间值大于需要查找的值则修改右边界为中间值-1,若中间值小于需要查找的值则修改左边界为中间值+1,一直循环下去,直到找到查找的值,若一直没有找到需要查找的值则返回查找失败。
哈希查找:哈希查找即根据需要查找的值,直接一步到位定位到这个值的存储位置,唯一需要进行考虑的冲突的情况。这里详见哈希查找。

二. 描述各种排序算法的特点和基本思想&比较分析各种排序算法
描述各种排序算法的特点和基本思想:
1. 插入排序
直接插入排序:总共进行n-1轮排序,其基本思想是每次将一个待排序的记录按其关键字大小插入前面已排好序的子序列,直到全部记录插入完成。
希尔排序:从直接插入排序改进而来,由于直接插入排序对于基本有序且少量元素的排序效率很高,所以希尔排序每一次只排少量有序元素(根据步长确定),多次少量的组合,其本质依然是插入排序,只不过是将一个大的数字序列分成了几部分小的数字序列。
2. 交换排序
冒泡排序:冒泡排序的基本思想是:从后往前(或从前往后)两两比较相邻元素的值,若为逆序(即A[i-1]>A[i]),则交换它们。直到序列比较完。我们称它为第一趟冒泡,结果是将最小的元素交换到待排序序列的第一个位置(或将最大的元素减缓到待排序序列的最后一个位置),关键字最小的元素如气泡一般逐渐往上“漂浮”直至“水面”(或关键字最大的元素如石头一般下沉至水底)。下一趟冒泡时,前一趟确定的最小元素不再参与比较,每趟冒泡的结果是把序列中的最小元素(或最大元素)放到了序列的最终位置...这样最多做n-1趟冒泡就能把所有元素排好序。
快速排序:快速排序的基本思想是基于分治法的,在待排序表L[1...n]中任取一个元素pivot作为枢轴(或称基准),通过一趟排序将待排序表划分为独立的两个部分L[1...k-1]和L[k+1...n],使得L[1...k-1]中的所有元素小于pivot,L[k+1...n]中的所有元素大于或等于pivot,则pivot放在了其最终位置L(k)上,这个过程称为一次划分。然后分别递归的对两个子表重复上述过程,直到每部分内只有一个元素或为空为止,即所有元素放在了其最终位置上。
3. 选择排序
选择排序:每一趟(如第i趟)在后面n-i+1(i=1,2,3...n-1)个待排序元素中选取关键字最小的元素,作为有序子序列的第i个元素,直到第n-1趟做完,待排序元素只剩下1个,完成排序。
堆排序:使用堆的元素下沉思想,即我先根据给定的数组序列构造一个堆,我每一次取根节点,并且将根节点删除(插入到最后一个位置),再对去掉根节点的数字序列构造一个堆;重复上述步骤即可得到最终的排序结果。
4. 外部排序
归并排序:归并排序与之前学习的基于交换、选择等排序的思想不一样,“归并”的含义是将两个或者两个以上的有序表合并成一个新的有序表。假定排序表含有n个记录,则可将其视为n个有序的子表,每个子表的长度为1,然后两两归并,得到n/2个长度为2或1的有序表;继续两两归并......如此重复,直到合成一个长度为n的有序表为止,这种排序方法称为2路归并。
比较分析各种排序算法:
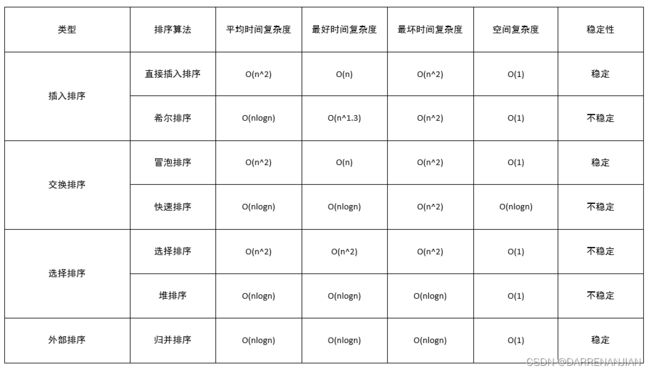
三. 设计一个自己的 Hash 函数和一个冲突解决机制
1. 对于哈希函数的构造:
这里采用除留余数法,p是最接近数字序列长度的质数。

2. 处理冲突的办法:
这里采用拉链法处理冲突。
3. 代码展示:
主类:
package Day_50;
public class demo1 {
public static void main(String[] args) {
int [] paraKeyArray = new int[]{11,2,3};
String[] paraContentArray = new String[]{"121","21","324"};
HashArray test=new HashArray(paraKeyArray,paraContentArray);
test.Hashtest();
}
}
调用类:
package Day_50;
/**
* Data array for searching and sorting algorithms.
*
* @author Jian An [email protected].
*/
public class HashArray {
/**
* An inner class for data nodes. The text book usually use an int value to
* represent the data. I would like to use a key-value pair instead.
*/
class DataNode {
/**
* The key.
*/
int key;
/**
* The data content.
*/
String content;
DataNode Next =null ;
/**
*********************
* The first constructor.
*********************
*/
public DataNode(int paraKey, String paraContent) {
key = paraKey;
content = paraContent;
Next = null;
}// Of the first constructor
/**
*********************
* Overrides the method claimed in Object, the superclass of any class.
*********************
*/
public String toString() {
return "(" + key + ", " + content + ") ";
}// Of toString
}// Of class DataNode
/**
* The data array.
*/
DataNode[] data;
/**
* The length of the data array.
*/
int length;
/**
*********************
* Overrides the method claimed in Object, the superclass of any class.
*********************
*/
public String toString() {
String resultString = "I am a data array with " + length + " items.\r\n";
for (int i = 0; i < length; i++) {
resultString += data[i] + " ";
} // Of for i
return resultString;
}// Of toString
/**
*********************
* The first constructor.
*
* @param paraKeyArray The array of the keys.
* @param paraContentArray The array of contents.
*********************
*/
public HashArray(int[] paraKeyArray, String[] paraContentArray) {
length = paraKeyArray.length;
data = new HashArray.DataNode[length];
for (int i = 0; i < length; i++) {
data[i] = new HashArray.DataNode(paraKeyArray[i], paraContentArray[i]);
} // Of for i
}// Of the first constructor
/**
*********************
* The second constructor. For Hash code only. It is assumed that
* paraKeyArray.length <= paraLength.
*
* @param paraKeyArray The array of the keys.
* @param paraContentArray The array of contents.
* @param p The key for the Hash function.
*********************
*/
public HashArray(int[] paraKeyArray, String[] paraContentArray, int p) {
// Step 1. Initialize.
length = p;
data = new DataNode[length];
for (int i = 0; i < length; i++) {
data[i] = new DataNode(-1,"-1");
} // Of for i
// Step 2. Fill the data.
int Position;
DataNode tempposition;
for (int i = 0; i < paraKeyArray.length; i++) {
Position = paraKeyArray[i] % p;
tempposition = data[Position];
while(tempposition.Next!=null){
tempposition=tempposition.Next;
}
tempposition.Next = new DataNode(paraKeyArray[i],paraContentArray[i]);
}
}// Of the second constructor
public static int zhishu(int HashLength) {
int j;
for (int i = HashLength; i >= 2; i--) {
for (j = 2; j <= i; j++) {
if (i % j == 0) {
break;
}
}
if (j == i) {
return i;
}
}
return 2;
}
public String HashSearch(int paraKey,int p){
int position =paraKey%p;
DataNode tempposition = data[position];
String result = " ";
while (tempposition.Next != null) {
if (tempposition.Next.key == paraKey) {
result = result + "key is_" + tempposition.Next.key + " string is_" + tempposition.Next.content
+ " the position is_" + position + "\r\n";
return result;
}
tempposition=tempposition.Next;
}
result = "there is no one";
return result;
}
public static void Hashtest(){
int[] tempUnsortedKeys = { 16, 33, 38, 69, 57, 95, 86 };
String[] tempContents = { "if", "then", "else", "switch", "case", "for", "while" };
int p = zhishu(tempUnsortedKeys.length-1);
HashArray temptest = new HashArray(tempUnsortedKeys , tempContents , p);
String temp;
temp=temptest.HashSearch(16,p);
System.out.println(temp);
temp=temptest.HashSearch(57,p);
System.out.println(temp);
temp=temptest.HashSearch(95,p);
System.out.println(temp);
temp=temptest.HashSearch(295,p);
System.out.println(temp);
}
}// Of class DataArray运行结果:
