ChatGLM2-6B 部署与微调
文章目录
-
- 一、ChatGLM-6B
- 二、ChatGLM2-6B
- 三、本地部署ChatGLM2-6B
-
- 3.1 命令行模式
- 3.2 网页版部署
- 3.3 本地加载模型权重
- 3.4 模型量化
- 3.5 CPU部署
- 3.6 多卡部署
- 四、P-tuning v2微调教程
-
- 4.1 P-tuning v2 原理
- 4.2 P-tuning v2微调实现
-
- 4.2.1 安装依赖,下载数据集
- 4.2.2 开始训练
- 4.2.3 训练效果对比
- 4.2.4 推理
- 五、 全参数微调(Finetune)
- bilibili视频《ChatGLM2-6B 部署与微调》、视频课件
- ChatGLM2-6B开源地址、官方博客、智谱清言
一、ChatGLM-6B
《LLMs模型速览(GPTs、LaMDA、GLM/ChatGLM、PaLM/Flan-PaLM、BLOOM、LLaMA、Alpaca)》
-
GLM:一种基于Transformer架构进行改进的通用预训练框架,GLM将不同任务的预训练目标统一为自回归填空任务(Autoregressive Blank Infilling),使得模型在自然语言理解和文本生成方面性能都有所改善。

-
GLM-130B:于2022年8月由清华智谱AI开源放出。该大语言模型基于之前提出的GLM(General Language Model),在Norm处理、激活函数、Mask机制等方面进行了调整,目的是训练出开源开放的高精度千亿中英双语稠密模型,能够让更多研发者用上千亿模型。 -
ChatGLM: 基于GLM-130B,引入面向对话的用户反馈,进行指令微调后得到的对话机器人。ChatGLM解决了大基座模型在复杂问题、动态知识、人类对齐场景的不足。ChatGLM于2023年3月开启申请内测,目前暂停了公开申请。 -
ChatGLM-6B:由于ChatGLM千亿参数版本暂未公开,为了与社区一起更好地推动大模型技术的发展,清华团队于2023.3开源了62亿参数版本的ChatGLM-6B。结合模型量化技术,用户可以在消费级的显卡上进行本地部署。
该版本具有以下特点:
- 充分的中英双语预训练: ChatGLM-6B 在 1:1 比例的中英语料上训练了 1T 的 token 量,兼具双语能力。
- 优化的模型架构和大小: 吸取 GLM-130B 训练经验,修正了二维 RoPE 位置编码实现,使用传统FFN结构。6B(62亿)的参数大小,也使得研究者和个人开发者自己微调和部署 ChatGLM-6B 成为可能。
- 较低的部署门槛: FP16 半精度下,ChatGLM-6B 需要至少 13GB 的显存进行推理,结合模型量化技术,这一需求可以进一步降低到 10GB(INT8) 和 6GB(INT4), 使得 ChatGLM-6B 可以部署在消费级显卡上。
- 更长的序列长度: 相比 GLM-10B(序列长度1024),ChatGLM-6B 序列长度达 2048,支持更长对话和应用。
- 人类意图对齐训练: 使用了监督微调(Supervised Fine-Tuning)、反馈自助(Feedback Bootstrap)、人类反馈强化学习(Reinforcement Learning from Human Feedback) 等方式,使模型初具理解人类指令意图的能力。输出格式为 markdown,方便展示。

有关GLM、GLM130B、ChatGLM模型原理、结构、效果的更详细介绍,请参考《LLMs模型速览(GPTs、LaMDA、GLM/ChatGLM、PaLM/Flan-PaLM、BLOOM、LLaMA、Alpaca)》第三章。
二、ChatGLM2-6B
参考:《ChatGLM2-6B:性能大幅提升,8-32k上下文,推理提速42%》
清华KEG和数据挖掘小组(THUDM)在2023.06.25发布了中英双语对话模型ChatGLM2-6B,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
- 基座模型升级,性能更强大。相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
- 支持8K-32k的上下文。模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。
- 推理性能提升了42%。基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
- 更开放的协议:ChatGLM2-6B 权重对学术研究完全开放,在获得官方的书面许可后,亦允许商业使用。

三、本地部署ChatGLM2-6B
3.1 命令行模式
git clone https://github.com/THUDM/ChatGLM2-6B
cd ChatGLM2-6B
pip install -r requirements.txt
python cli_demo.py
本地部署后运行 cli_demo.py,就会看到下面的原始界面
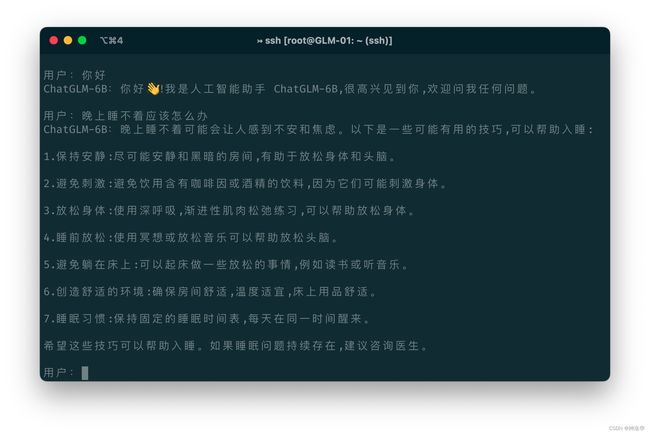
3.2 网页版部署
可以通过以下命令启动基于 Gradio 的网页版 demo:
python web_demo.py
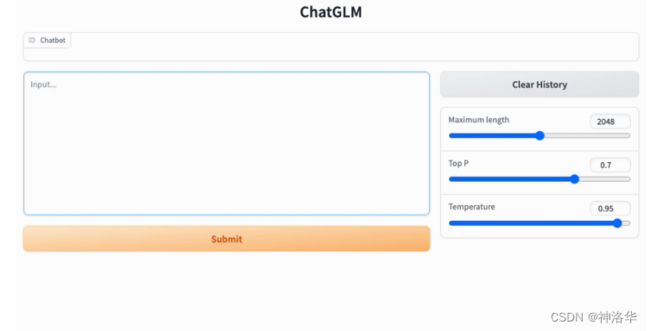
也可以通过以下命令启动基于 Streamlit 的网页版 demo:
streamlit run web_demo2.py
推理参数设置:

3.3 本地加载模型权重
默认情况下,会从huggingface自动下载模型权重,例如:
>>> from transformers import AutoTokenizer, AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
>>> model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True, device='cuda')
>>> model = model.eval()
>>> response, history = model.chat(tokenizer, "你好", history=[])
>>> print(response)
你好!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。
>>> response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
>>> print(response)
晚上睡不着可能会让你感到焦虑或不舒服,但以下是一些可以帮助你入睡的方法:
1. 制定规律的睡眠时间表:保持规律的睡眠时间表可以帮助你建立健康的睡眠习惯,使你更容易入睡。尽量在每天的相同时间上床,并在同一时间起床。
2. 创造一个舒适的睡眠环境:确保睡眠环境舒适,安静,黑暗且温度适宜。可以使用舒适的床上用品,并保持房间通风。
3. 放松身心:在睡前做些放松的活动,例如泡个热水澡,听些轻柔的音乐,阅读一些有趣的书籍等,有助于缓解紧张和焦虑,使你更容易入睡。
4. 避免饮用含有咖啡因的饮料:咖啡因是一种刺激性物质,会影响你的睡眠质量。尽量避免在睡前饮用含有咖啡因的饮料,例如咖啡,茶和可乐。
5. 避免在床上做与睡眠无关的事情:在床上做些与睡眠无关的事情,例如看电影,玩游戏或工作等,可能会干扰你的睡眠。
6. 尝试呼吸技巧:深呼吸是一种放松技巧,可以帮助你缓解紧张和焦虑,使你更容易入睡。试着慢慢吸气,保持几秒钟,然后缓慢呼气。
如果这些方法无法帮助你入睡,你可以考虑咨询医生或睡眠专家,寻求进一步的建议。
如果网速太慢,也可以从本地加载模型:
# 从Huggingface上下载模型权重
git clone https://huggingface.co/THUDM/chatglm2-6b
你可以也可以从清华云盘下载模型权重。
下载的文件需放到本地的 chatglm2-6b 目录下,然后修改以下代码,以从本地加载模型:
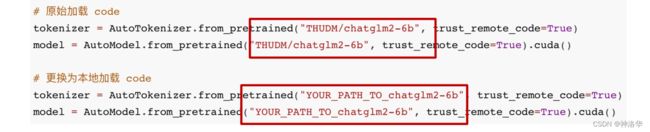
模型的实现仍然处在变动中。如果希望固定使用的模型实现以保证兼容性,可以在
from_pretrained的调用中增加revision="v1.0"参数。v1.0 是当前最新的版本号,完整的版本列表参见 Change Log。
3.4 模型量化

默认情况下,模型以 FP16 精度加载,运行上述代码需要大概 13GB 显存。如果你的 GPU 显存有限,可以尝试以量化方式加载模型,使用方法如下:
model = AutoModel.from_pretrained("THUDM/chatglm2-6",trust_remote_code=True).quantize(8).cuda()
如果内存不够,可以直接加载量化后的模型:
model = AutoModel.from_pretrained("THUDM/chatglm2-6b-int4",trust_remote_code=True).cuda()
对话越长,内存和显存的要求也越高。所以对于加载一篇paper或者小说,6B是不够的。在资源确实有限的时候,可以在做完一次有目的的对话后,重启webui,或者清除对话历史,节约资源。
3.5 CPU部署
如果你没有 GPU 硬件的话,也可以在 CPU 上进行推理,但是推理速度会更慢。使用方法如下(需要大概 32GB 内存)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).float()
如果你的内存不足的话,也可以使用量化后的模型
model = AutoModel.from_pretrained("THUDM/chatglm2-6b-int4",trust_remote_code=True).float()
3.6 多卡部署
如果你有多张 GPU,但是每张 GPU 的显存大小都不足以容纳完整的模型,那么可以将模型切分在多张GPU上。首先安装 accelerate: pip install accelerate,然后通过如下方法加载模型:
from utils import load_model_on_gpus
model = load_model_on_gpus("THUDM/chatglm2-6b", num_gpus=2) # num_gpus 表示使用的GPU 数
四、P-tuning v2微调教程
ChatGLM2-6B 的部署与微调教程
4.1 P-tuning v2 原理
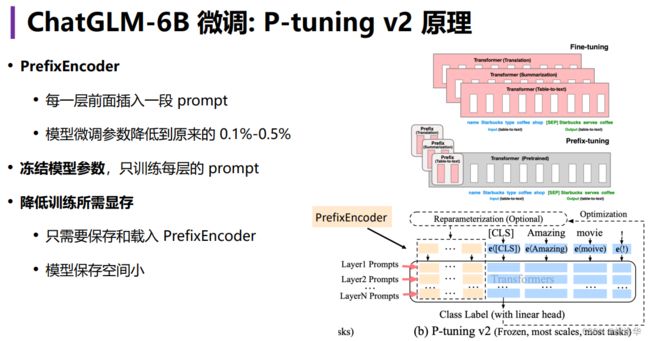
更多详情,请参考《大模型高效微调综述上:Adapter Tuning、AdaMix、PET、Prefix-Tuning、Prompt Tuning、P-tuning、P-tuning v2》3.2.5章节
4.2 P-tuning v2微调实现
P-Tuning v2 将需要微调的参数量减少到原来的 0.1%,再通过模型量化、Gradient Checkpoint 等方法,最低只需要 7GB 显存即可运行。下面以 ADGEN (广告生成) 数据集为例介绍代码的使用方法。
4.2.1 安装依赖,下载数据集
# 运行微调除 ChatGLM2-6B 的依赖之外,还需要安装以下依赖
!pip install rouge_chinese nltk jieba datasets transformers[torch] -i https://pypi.douban.com/simple/
接着从 Google Drive 或者 Tsinghua Cloud 下载处理好的 ADGEN 数据集,将解压后的 AdvertiseGen 目录放到 ptuning 目录下。
%cd ptuning
!wget https://cloud.tsinghua.edu.cn/seafhttp/files/737d36da-1b35-420c-8cea-7d5ffa0c6b96/AdvertiseGen.tar.gz
# 检查数据集
!ls -alh AdvertiseGen
total 52M
drwxr--r-- 2 mw users 4.0K Jul 7 09:22 .
drwxr-xr-x 3 mw users 4.0K Jul 7 09:22 ..
-rw-r--r-- 1 mw users 487K Jul 7 09:22 dev.json
-rw-r--r-- 1 mw users 52M Jul 7 09:22 train.json
ADGEN 数据集任务为根据输入(content)生成一段广告词(summary),其格式为json string的格式,例如:
{
"content": "类型#上衣*版型#宽松*版型#显瘦*图案#线条*衣样式#衬衫*衣袖型#泡泡袖*衣款式#抽绳",
"summary": "这件衬衫的款式非常的宽松,利落的线条可以很好的隐藏身材上的小缺点,穿在身上有着很好的显瘦效果。领口装饰了一个可爱的抽绳,漂亮的绳结展现出了十足的个性,配合时尚的泡泡袖型,尽显女性甜美可爱的气息。"
}
4.2.2 开始训练
运行ptuning 目录下的train.sh脚本,即可开始训练:
# train.sh
PRE_SEQ_LEN=128
LR=2e-2
NUM_GPUS=1
torchrun --standalone --nnodes=1 --nproc-per-node=$NUM_GPUS main.py \
--do_train \ # 训练模式
--train_file AdvertiseGen/train.json \ # 训练集路径
--validation_file AdvertiseGen/dev.json \ # 评估集路径
--preprocessing_num_workers 10 \ # 线程数
--prompt_column content \ # prompt的字段,对应ADGEN数据集中的content
--response_column summary \ # response的字段,对应ADGEN数据集中的summary
--overwrite_cache \
--model_name_or_path path/to/chatglm2_6b \ # 模型名称/路径
--output_dir output/adgen-chatglm2-6b-pt-$PRE_SEQ_LEN-$LR \
--overwrite_output_dir \
--max_source_length 64 \ # 最大输入长度
--max_target_length 128 \ # 最大输出长度,太短的话ChatGLM的表达有限
--per_device_train_batch_size 1 \ # 训练的batch_size
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 16 \ # 梯度累积步数
--predict_with_generate \
--max_steps 3000 \ # 总步数
--logging_steps 10 \
--save_steps 1000 \ # 每隔1000步保存一次模型
--learning_rate 2e-2 \ # 学习率
--pre_seq_len 128 \ # P-tuning v2中soft prompt的长度,可以进行调节以取得最佳的效果。不设置则为全量微调
--quantization_bit 4 # 量化等级,不加此选项则为 FP16 精度加载
默认配置为 quantization_bit=4,per_device_train_batch_size=1,gradient_accumulation_steps=16 ,此时为INT4 量化模型,且每次训练会以 1 的批处理大小进行 16 次累加的前后向传播(batch_size=1,累积16次才进行梯度回传,更新参数),等效为 16 的总批处理大小,此时最低只需 6.7G 显存。若想在提升训练效率,可在二者乘积不变的情况下,加大 per_device_train_batch_size 的值,但也会带来更多的显存消耗,请根据实际情况酌情调整。
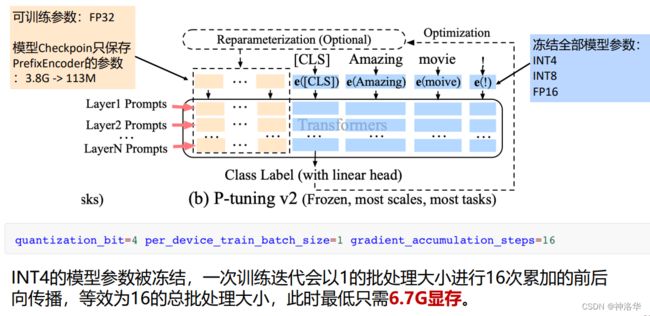
在训练完之后,我们只保存prefix encoder的参数,而不是整个模型。prefix encoder的参数在output_dir 下的checkpoint文件可以找到,其类型为pytorch_model.bin文件,大小只有一百多兆。
colab上内存不够只能跑int模型,batch_size可以设为16。设为8的时候跑300steps用了50min(GPU为T4)
4.2.3 训练效果对比
# 使用 Markdown 格式打印模型输出
from IPython.display import display, Markdown, clear_output
def display_answer(model, query, history=[]):
for response, history in model.stream_chat(
tokenizer, query, history=history):
clear_output(wait=True)
display(Markdown(response))
return history
# 加载模型
model_path = "chatglm2_6b"
from transformers import AutoTokenizer, AutoModel
# 载入Tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
# 加载微调前的模型
model = AutoModel.from_pretrained(model_path, trust_remote_code=True).half().cuda()
model = model.eval()
display_answer(model, "类型#上衣\*材质#牛仔布\*颜色#白色\*风格#简约\*图案#刺绣\*衣样式#外套\*衣款式#破洞")
上衣材质为牛仔布,颜色为白色,风格为简约,图案为刺绣,衣款式为外套,衣样式为破洞。
# 微调后
import os
import torch
from transformers import AutoConfig
config = AutoConfig.from_pretrained(model_path, trust_remote_code=True, pre_seq_len=128)
model = AutoModel.from_pretrained(model_path, config=config, trust_remote_code=True)
# 设定prefix_encoder 的路径,CHECKPOINT_PATH为刚刚output_dir 路径下的checkpoint文件
prefix_state_dict = torch.load(os.path.join("./output/adgen-chatglm2-6b-pt--/checkpoint-300", "pytorch_model.bin"))
new_prefix_state_dict = {}
for k, v in prefix_state_dict.items():
if k.startswith("transformer.prefix_encoder."):
new_prefix_state_dict[k[len("transformer.prefix_encoder."):]] = v
model.transformer.prefix_encoder.load_state_dict(new_prefix_state_dict)
# 以下代码如果不需要量化可以注释掉
model = model.quantize(4)
model = model.half().cuda()
model.transformer.prefix_encoder.float()
model = model.eval()
display_answer(model, "类型#上衣\*材质#牛仔布\*颜色#白色\*风格#简约\*图案#刺绣\*衣样式#外套\*衣款式#破洞")
这款牛仔外套采用经典白色,简约大方,不规则的破洞设计,打破单调,更显个性,白色与牛仔布色搭配,时尚有型。精致的刺绣图案,细节感十足,衬托出女性独特的气质。
4.2.4 推理
如果需要获取多个需求的响应,手动输入太慢了,此时可以运行以下代码进行推理:
PRE_SEQ_LEN=128
CHECKPOINT='adgen-chatglm2-6b-pt-128-2e-2'
STEP=300
!python main.py \
--do_predict \
--validation_file AdvertiseGen/dev.json \
--test_file AdvertiseGen/dev.json \
--overwrite_cache \
--prompt_column content \
--response_column summary \
--model_name_or_path /content/drive/MyDrive/LLMs/ChatGLM2-6B/ptuning/chatglm2-6b-int4 \
--ptuning_checkpoint ./output/$CHECKPOINT/checkpoint-$STEP \
--output_dir ./output/$CHECKPOINT \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 64 \
--per_device_eval_batch_size 64 \
--predict_with_generate \
--pre_seq_len $PRE_SEQ_LEN \
--quantization_bit 4
五、 全参数微调(Finetune)
如果需要进行全参数的 Finetune,需要安装 Deepspeed,然后运行以下指令:
bash ds_train_finetune.sh
# ds_train_finetune.sh
LR=1e-4
MASTER_PORT=$(shuf -n 1 -i 10000-65535)
deepspeed --num_gpus=4 --master_port $MASTER_PORT main.py \
--deepspeed deepspeed.json \
--do_train \
--train_file AdvertiseGen/train.json \
--test_file AdvertiseGen/dev.json \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path THUDM/chatglm2-6b \
--output_dir ./output/adgen-chatglm2-6b-ft-$LR \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 64 \
--per_device_train_batch_size 4 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 1 \
--predict_with_generate \
--max_steps 5000 \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate $LR \
--fp16
相比之下,就是batch_size、学习率等训练参数有些变化,并且没有设置pre_seq_len参数。另外全量微调对硬件要求较高:
